目录
【Cortex-M7内核的L1 Cache】
二,Cache4种策略
三,Cache读操作和写操作
【cache配合MPU使用】
【什么是 cache 一致性问题】
一,第一种情况
二,第二种情况
【解决cache一致性问题,有两种可选方案】
一.所有的共享存储器都定义为共享属性
二.通过软件进行cache的维护
【常见Cache操作函数解释】
【其他指令解释】
DMB
DSB
ISB
【Cortex-M7内核的L1 Cache】
一
Cache又分数据缓存D-Cache和指令缓冲I-Cache,STM32H7 的数据缓存和指令缓存大小都是16KB。STM32H7主频是400MHz,除了TCM和Cache以400MHz工作,其它AXI SRAM,SRAM1,SRAM2等都是以200MHz工作。数据缓存D-Cache就是解决CPU加速访问SRAM。
如果每次CPU要读写SRAM区的数据,都能够在Cache里面进行,自然是最好的,实现了200MHz到400MHz的飞跃,实际是做不到的,因为数据Cache只有16KB大小,总有用完的时候。
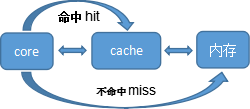
有了cache后,core对内存中的数据访问流程如下图所示:
L1 Cache由多行内存区组成,每行有32字节,每行都配有一个地址标签。
数据缓冲DCache:是每4行为一组,称为4-way set associative。
指令缓冲区ICache:是2行为一组, 称为2-way set-associative
这样节省地址标签,不用每个行都标记一个地址。
Cache hit: 要访问的数据/指令在cache里面.
Cache miss: 要访问的数据/指令不在cache里面.
二,Cache4种策略
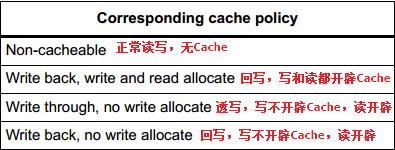
<回写:如果Cache中有,写数据只写到Cache,不写到RAM。>
<透写:如果Cache中有,写数据也要同时写到Cache和RAM。>
<write allocate:写数据时,如果Cache中没有,那么就要在Cache中开辟一个空间,把数据写入Cache,同时把RAM中的相邻数据加载进来填充Cache。>
<no write allocate:写数据时,如果Cache中没有,那么把数据直接写入RAM。>
<read allocate:读数据时,如果Cache中没有,那么就要在Cache中开辟一个空间,把数据从RAM中加载进来,后续的读操作,就可以直接从Cache中读取了。>
<no read allocate:读数据时,如果Cache中没有,那么直接从RAM中读。>
三,Cache读操作和写操作
1,Core 读cache时:
若hit,则直接从cache读出数据即可。
若miss,有两种处理方式:
>read through , 直接从内存中读出
>read allocate, 先把数据读到cache,再从cache读出。如果 CPU 要读取的 SRAM 区数据在 Cache 中已经加载好,就可以直接从 Cache 里面读取。如果没有,就用到配置 read allocate 了,意思就是在 Cache 里面开辟区域,将 SRAM 区数据加载进来,后续的操作,CPU 可以直接从 Cache 里面读取,从而时间加速。
2,Core 写cache时:
若hit,两种处理方式:
>write-through模式: 可以直接写到内存中同时放到Cache里面,优点是内存和cache同步更新,没有多总线访问造成的数据一致性问题,缺点是无法在写操作上面发挥性能。
>Write back模式: Cache line会被标为dirty,等到此行被evicted(驱逐,赶出, flush)时,才会执行实际的写操作,将Cache Line里面的数据写入到相应的存储区。
* Write back安全隐患:如果 Cache 命中的情况下,此时仅 Cache 更新了,而 SRAM,SDRAM 没有更新,那么 DMA 直接从 SRAM 里面读出来的就是错误的。
若miss,两种处理方式:
>write-allocate: 先把要写的数据载入到cache,写cache,然后再flush进内存。
>no-write-allocate: 直接写入内存。
Cache 命中是访问的地址落在了给定的 Cache Line 里面,所以硬件需要做少量的地址比较工作,以检查此地址是否被缓存。如果命中了,将用于缓存读操作或者写操作。如果没有命中,则分配和标记新行,填充新的读写操作。如果所有行都分配完毕了,Cache 控制器将支持 eviction 操作。根据 Cache Line 替换算法,一行将被清除 Clean,无效化 Invalid 或者重新配置。数据缓存和指令缓存是采用的伪随机替换算法。
Cache支持的4种基本操作,1.使能,2.禁止,3.清空,4.无效化。
Clean清空操作是将Cache Line中标记为dirty的数据写入到内存里面;
无效化Invalid是将 Cache Line 标记为无效,等同于删除操作。这样Cache 空间就都腾出来了,可以加载新的指令/数据。
Cortex-M7 core with 32K/32K L1 I/D-Cache!
I/DTCM(FlexRAM banks configured as TCM)由CPU核直接访问,绕过L1缓存。因此,建议将关键代码和数据放入TCM中,就像向量表vector table一样;
【cache配合MPU使用】
MPU(memory protection unit),首先需要通过MPU配置相应memory的属性(normal, strongly-ordered, device, XN etc.)
1、作用
防止不受信任的应用程序访问受保护的内存区域; 防止用户应用程序破坏操作系统使用的数据;通过阻止任务访问其它任务的数据区;允许将内存区域定义为只读,以便保护重要数据;检测意外的内存访问。 简单的说就是内存保护、外设保护和代码访问保护。
2、MPU可以配置的三种内存类型
1)、Normal memory
CPU以最高效的方式加载和存储字节、半字和字,对于这种内存区,CPU的加载或存储不一定要按照程序列出的顺序执行。
2)、Device memory
对于这种类型的内存区,加载和存储要严格按照次序进行,这样是为了确保寄存器按照正确顺序设置。
3)、Strongly ordered memory
程序完全按照代码顺序执行,CPU需要等待当前的加载/存储指令执行完毕后才执行下一条指令。这样会导致性能下降。
3、MPU的使用
MPU可以配置保护16个内存区域(这16个内存域是独立配置的),每个区域最小要求256字节,每个区域还可以配置为8个子区域。由于子区域一般都相同大小,这样每个子区域的大小就是32字节,正好跟Cache的Cache Line大小一样。
使用时把一段连续的内存区配置为一个MPU保护区域,然后再配置这个MPU保护区域的特性。比如128KB的DTCM、64KB的SRAM4、32MB的SDRAM。MPU保护区域的特性使用MPU_RASR寄存器来配置,描述如下:
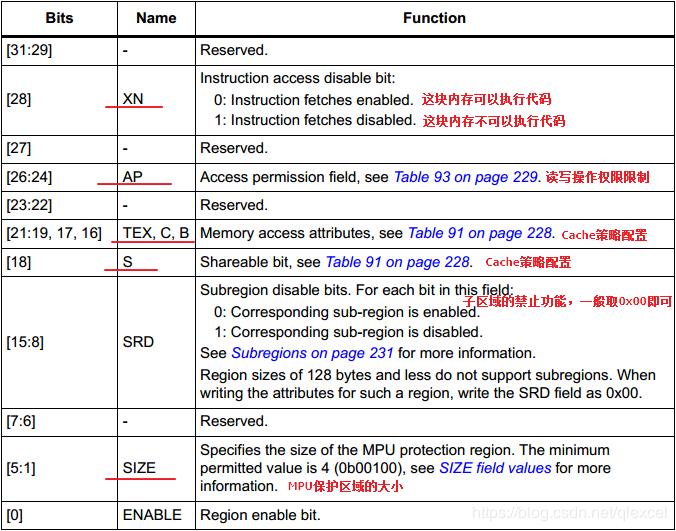
1)、XN:用于控制这个MPU保护区域能否执行程序代码。
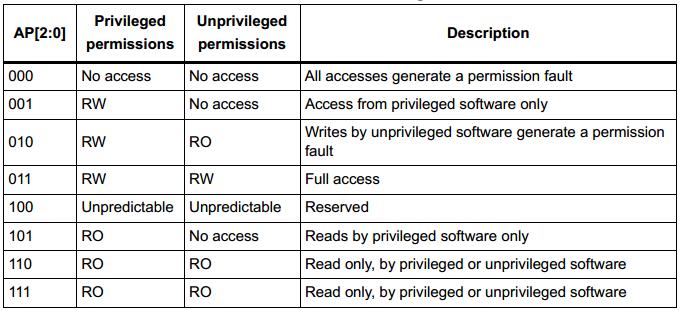
2)、AP:用于控制这个MPU保护区域的特权级和非特权级的读写访问权限。
3)、TEX、C、B、S:H7支持4种Cache策略,这几位就是用来控制这个MPU保护区域使用哪一种。
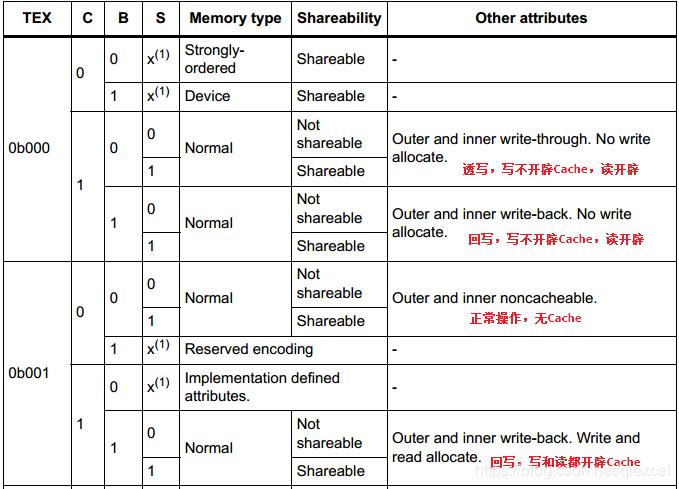
S位用于解决多总线或者多核访问的共享问题,一般不要开启。
4)、SRD:这个位用于控制内存区的子区域 ,使用的是bit[15:8],共计8个bit,一个bit控制一个子区域, 0表示使能此子区域, 1表示禁止。一般情况下,取值0x00,表示8个子区域都使能。
5)、SIZE:配置这个MPU保护区域的大小。
【什么是 cache 一致性问题】
对于指令缓冲I-Cache,用户不用管,这里主要说的是数据缓存 D-Cache。
所谓的 Cache 一致性问题, 主要指的是由于 D-cache 存在时,表现在有多个 Host(典型的如 MCU 的 Core, DMA 等)访问同一块内存时, 由于数据会缓存在 D-cache 中而没有更新实际的物理内存。
在实际应用中,有以下两种情况:
一,第一种情况
当有core写物理内存(SRAM,0x20200000)的指令时,(对应SDK例程:*(uint8_t *)(startAddr + count) = 0xffu;)Core 会先去更新相应的 cache-line(Write-back 策略),在没有 clean 的情况下,会导致其对应的实际物理内存中的数据并没有被更新,如果这个时候有其它的 Host(如 DMA)访问这段内存时,就会出现问题(由于实际物理内存并未被更新,和 D-cache 中的不一致),如果clean一下(对应SDK例程:L1CACHE_CleanDCacheByRange(startAddr, MEM_DMATRANSFER_LEN);)这就是所谓的 cache 一致性的问题。
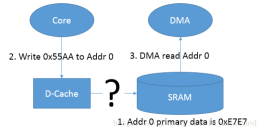
二,第二种情况
DMA 更新了某段物理内存(DMA 和 cache 直接没有直接通道),而这个时候 Core 再读取这段内存的时候,由于相对应地址的 cache-line 没有被 invalidate,导致 Core 读到的是 cache-line 中的数据,而非被 DMA 更新过的实际物理内存的数据。
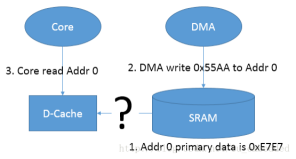
【解决cache一致性问题,有两种可选方案】
一.所有的共享存储器都定义为共享属性
• 这些区域将默认不被缓存到 D-Cache;
• 所有的操作都直接针对二级存储器(内部Flash,外部存储器),性能降低;
• 因为缓存对这些区域是透明的,写软件更容易;
二.通过软件进行cache的维护
(1)Cortex-M7 的写操作要是全局可见的
• 使用透写(write-through)属性(通过 MPU 设置)。
• 使用 SIWT@CACR(Shared = Write Through)。
• 通过指令清 D-cache,然后所有更新位置禁止 D-Cache操作;
这种情况,在DMA从SRAM搬运数据到SDRAM时,需要先执行clean,保证cache内的内容都被清除。
L1CACHE_CleanInvalidateDCache();
(2)其他主设备的写操作要对 Cortex-M7 可见
• 比如作废 Cortex-M7 Dache 中数据
这种情况,在DMA从SDRAM搬运数据到SRAM时,需要搬运后执行Invalidate。
L1CACHE_CleanInvalidateDCache()
【常见Cache操作函数解释】
SCB_EnableICache() 和 SCB_EnableDCache()
使能 I-cache 或 D-cache。系统上电后优先初始化即可。
SCB_DisableICache() 和 SCB_DisableDCache()
禁用 I-cache 或 D-cache。
SCB_InvalidateICache()
使 I-cache 无效,I-cache 被 invalidate 之后,当读取指令时,会忽略相应的 cache-line 中的内容(因为被 validate 了)。这样Cache空间就都腾出来了,可以加载新的指令,CPU等同于从真实的物理地址中去获取相应的指令。
SCB_InvalidateDCache()
使 D-cache 无效,D-cache 被 invalidate 之后,当有 Host(如 core,DMA 等)读取数据时,会忽略相应的 cache-line 中的内容( 因为被 validate 了),从真实的物理地址中去获取相应的数据
SCB_InvalidateDCache_by_Addr()
根据地址信息无效其对应的 cache-line,删除对应的内容。
SCB_CleanDCache()
Clean 所有的 cache-line,即将 dirty 的 cache-line 全部写到 cache line 对应的真实的物理地址中。所谓的 drity 属性,即写操作时, 更新了相应的 cache-line,但是没有更新到真实的物理地址,而这个 clean 的动作, 就是将 cache 中的内容更新到真实的物理地址中。
SCB_CleanDCache_by_Addr()
根据地址信息 clean 其对应的 cache-line
SCB_CleanInvalidateDCache()
此函数是前面两个函数SCB_InvalidateDCache和SCB_CleanDCache的二合一。将Cache Line中标记为dirty的数据写入到相应的存储区后,再将Cache Line标记为无效,表示删除。这样Cache空间就都腾出来了,可以加载新的数据。
SCB_CleanInvalidateDCache_by_Addr()
可以指定地址和存储区大小。将Cache Line中标记为dirty的数据写入到相应的存储区后,再将Cache Line标记为无效,表示删除。这样Cache空间就都腾出来了,可以加载新的数据。
【其他指令解释】
DMB
数据存储器隔离。DMB 指令保证: 仅当所有在它前面的存储器访问操作都执行完毕后,才提交(commit)在它后面的存储器访问操作。不影响其他不访问存储器指令的执行。
DSB
数据同步隔离。比 DMB 严格: 仅当所有在它前面的存储器访问操作都执行完毕后,才执行在它后面的指令(亦即任何指令都要等待存储器访问操作)
ISB
指令同步隔离。最严格:ISB充当指令同步屏障。它刷新处理器的流水线,因此 ISB之后的所有指令都会在ISB之后再次从缓存或内存中取出 指令已完成。
大部分操作(有关与外设的)都是基于内存访问的(例如外设寄存器,内存等),这些情况下的同步只需要DMB指令就能同步了。我发现需要DSB的例子就只有关中断指令,如果操作会导致代码区更新,并且可能调用其中的代码,则需要ISB指令
对于高级底层技巧:“自我更新”(self-mofifying)代码,非常有用。举例 来说,如果某个程序从下一条要执行的指令处更新了自己,但是先前的旧指令已经被预取到流水线 中去了,此时就必须清洗流水线,把旧版本的指令洗出去,再预取新版本的指令。因此,必须在被 更新代码段的前面使用 ISB,以保证旧的代码从流水线中被清洗出去,不再有机会执行
Bootloader在跳转到app之前的清洗,就是1个例子,如下: