新特性讲解第一篇~
文章目录
- 前言
- 一、较为重要的新特性
- 1.统一的初始化列表
- 2.decltype关键字
- 3.右值引用+移动语义
- 总结
前言
一、较为重要的新特性
1.统一的列表初始化
{}初始化相信大家应该并不陌生,比如int a[] = {1,2,3,4},而在c++11中,万物均可用{}进行初始化,并且还可以省略赋值符号。
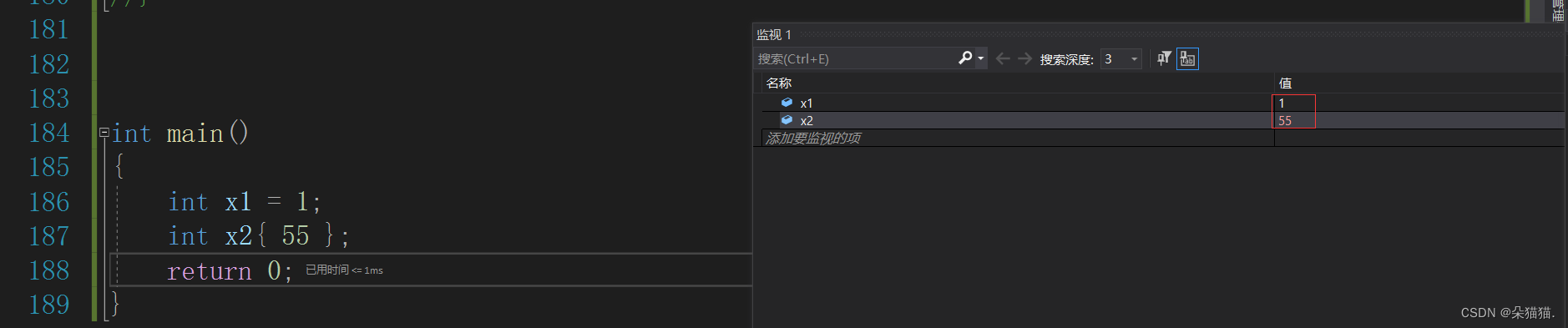
int main()
{int x1 = 1;int x2{ 55 };return 0;
}
下面我们再演示一下自定义类型:
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
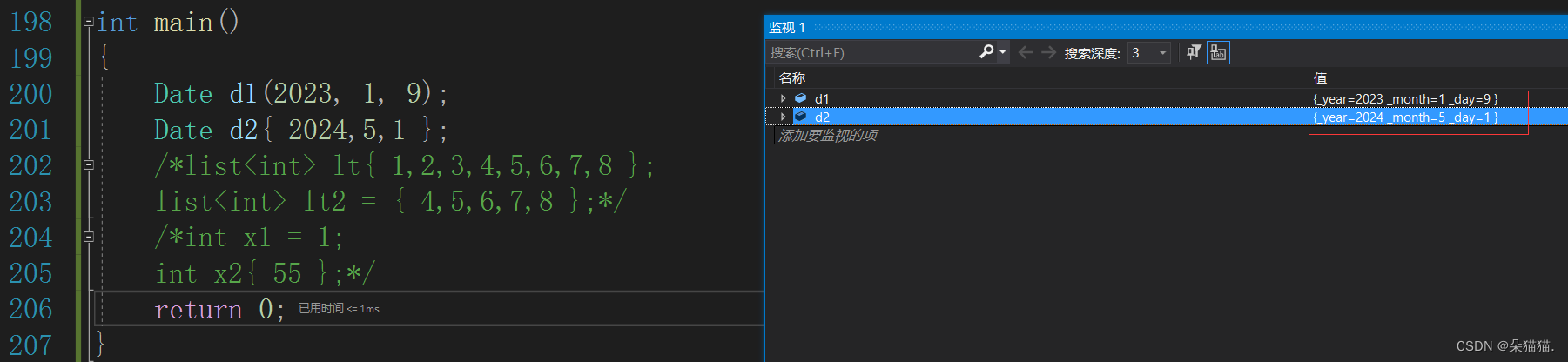
};int main()
{Date d1(2023, 1, 9);Date d2{ 2024,5,1 };return 0;
}
自定义类型也没有问题,下面我们再看看list,因为list和vector的意义不太一样:
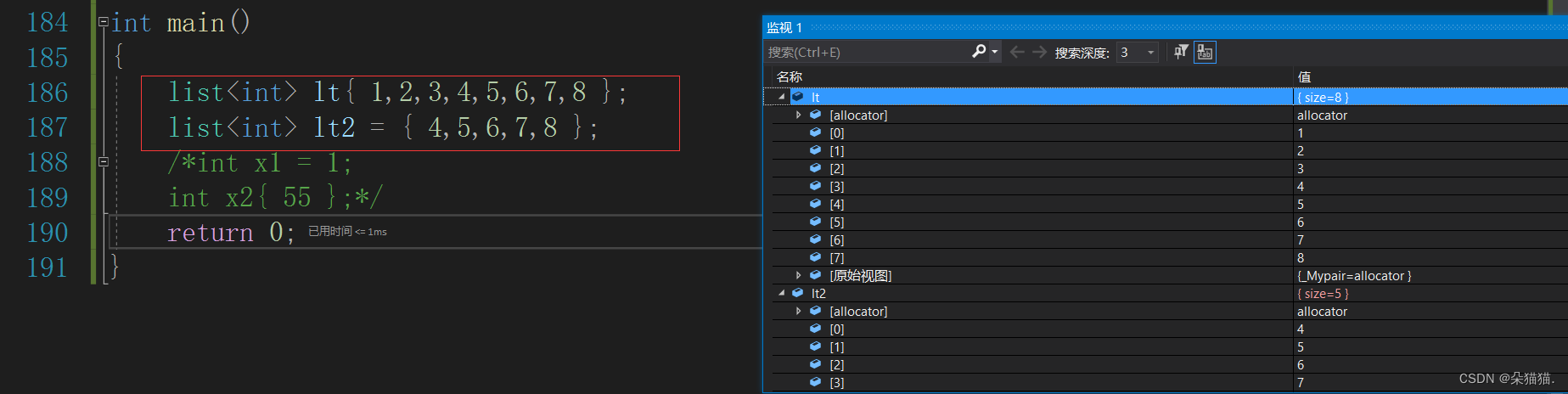
为什么说意义不一样呢,因为我们刚刚的内置类型用{}初始化是调用构造函数,自定义类型也一样。那么vector和list里面的参数都是可变的,这是怎么支持的呢?这是因为c++11增加了std::initializer_list的类,下面我们看看:
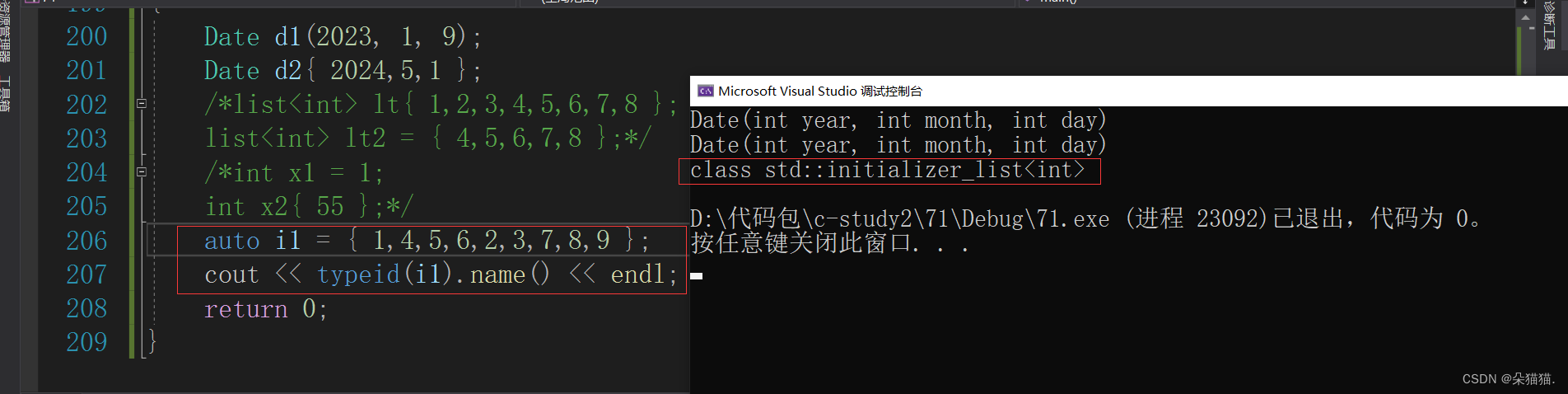
我们可以看到这个花括号的类型是一个initializer_list,下面我们看看这个可以修改吗:
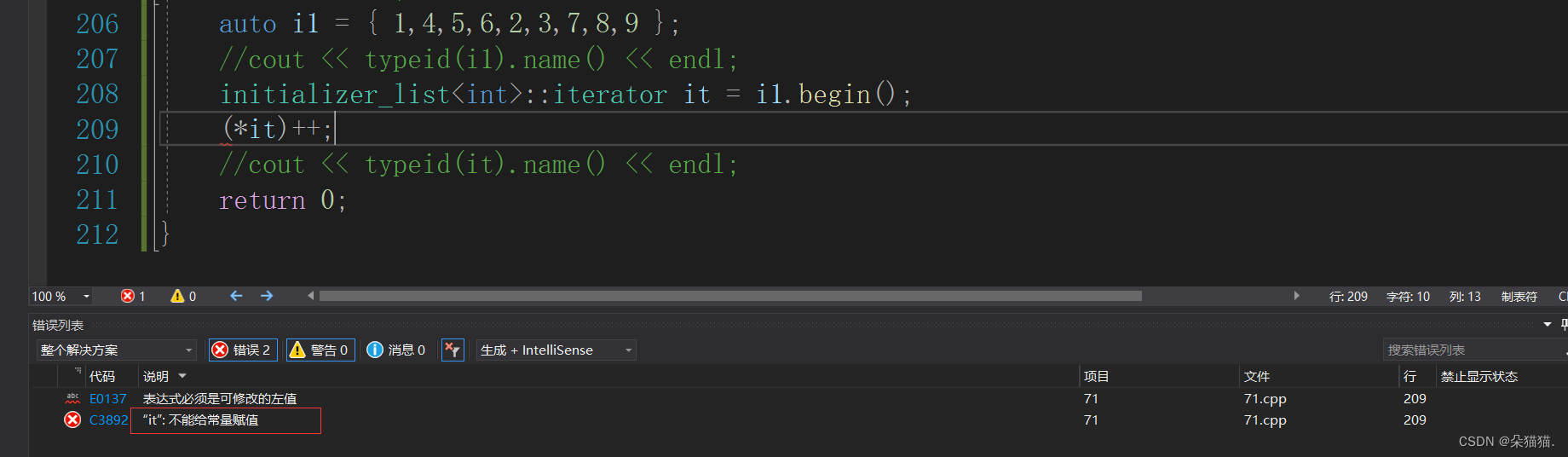
我们可以看到initializer_list指向的内容是不可以被修改的,因为initializer_list是存在常量区当中的。那么STL是如何支持用initializer_list初始化的呢?其实也很简单,就是增加一个支持用initializer_list初始化的构造函数,如下图所示:
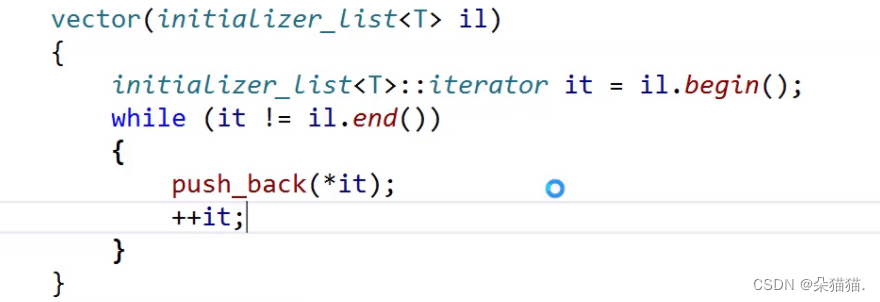
下面我们再看看其他初始化的用法: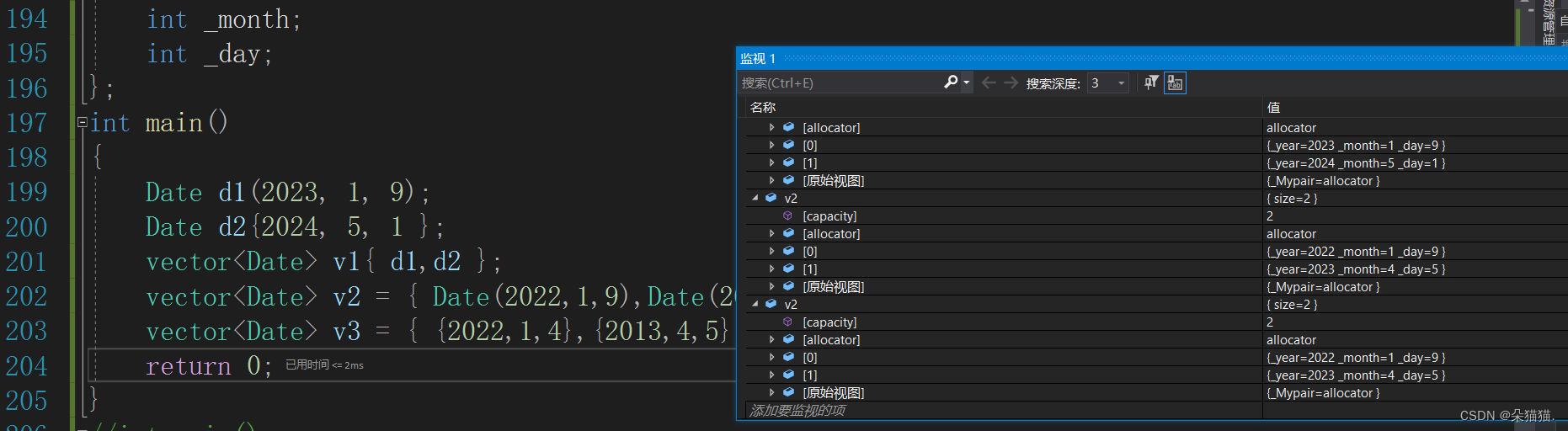
v3的初始化是先用里面的{}构造一个匿名对象,然后再调用initializer_list初始化。
2.decltype关键字
int main()
{const int x = 1;double y = 2.2;vector<decltype(x* y)> ret;return 0;
}
这个关键字的作用就这么多我们就不再演示了。
3.右值引用和移动语义
int main()
{// 10 一个常量// x + y 一个表达式// fmin(x,y) 一个函数返回值return 0;
}下面我们先看一下左值引用可以引用右值吗:
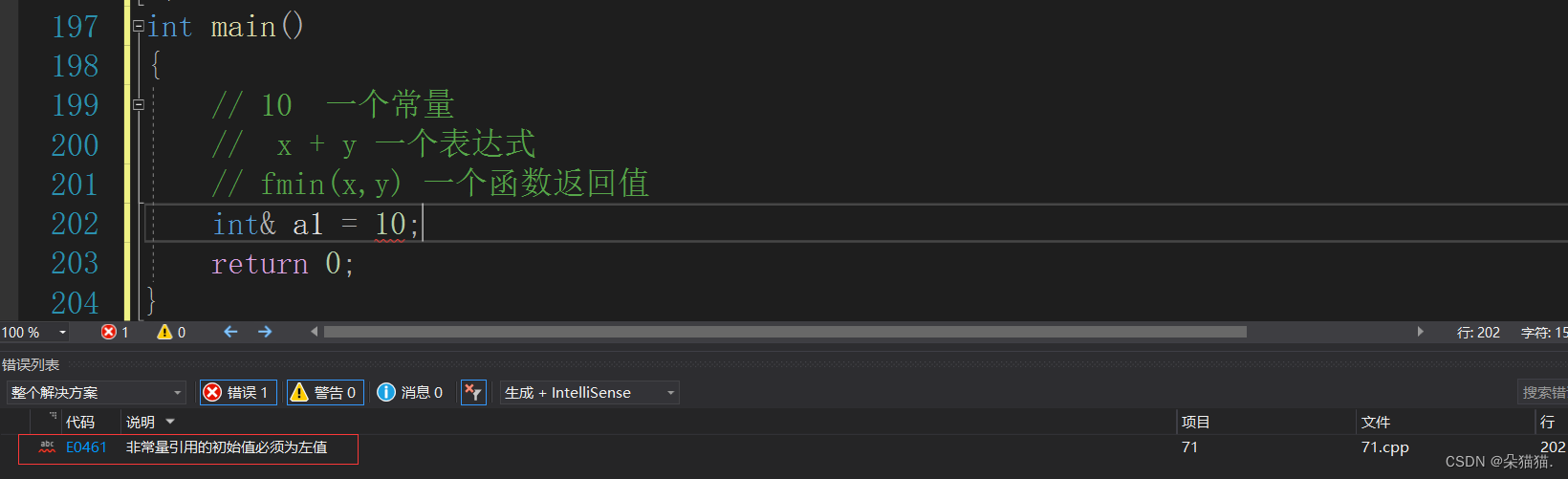
那么表达式呢?
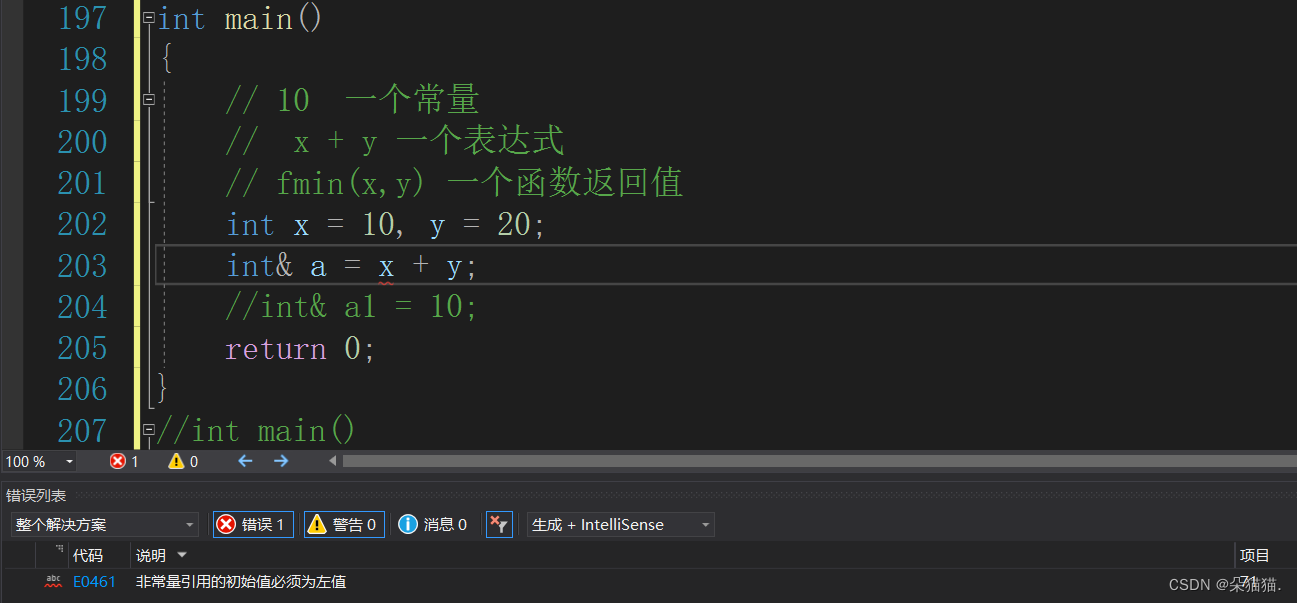
同样不行,但是我们说过向函数的返回值这些都是临时变量具有常性,所以我们可以加上const:
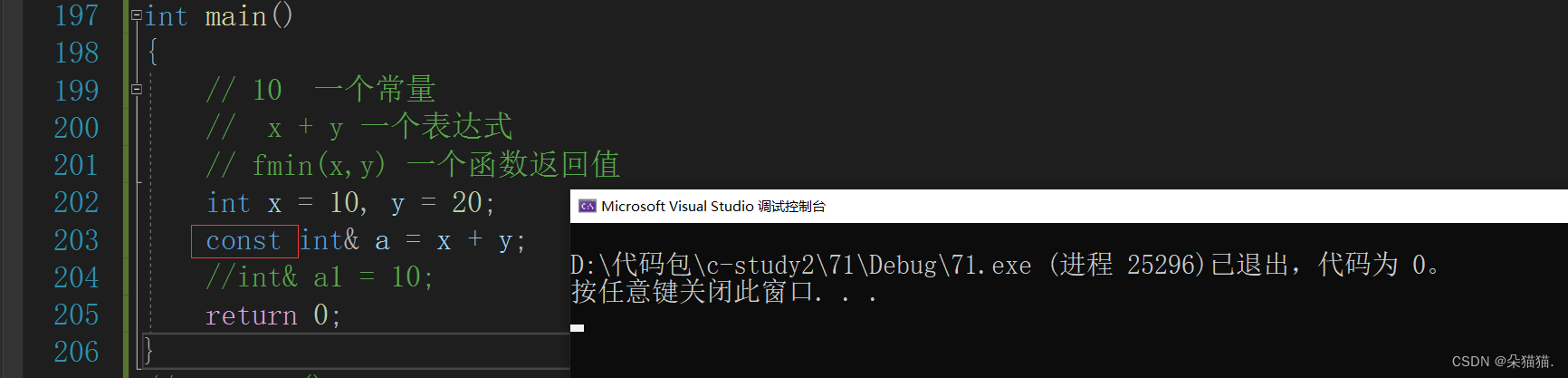 没错,我们的左值引用既可以引用左值也可以引用右值。下面我们用右值引用试试:
没错,我们的左值引用既可以引用左值也可以引用右值。下面我们用右值引用试试:
int main()
{int&& a1 = 10;double x = 10, y = 20;double&& ret = x + y;return 0;
}
刚刚我们的左值引用既可以引用左值也可以引用右值,下面我们看看右值引用能否引用左值呢?
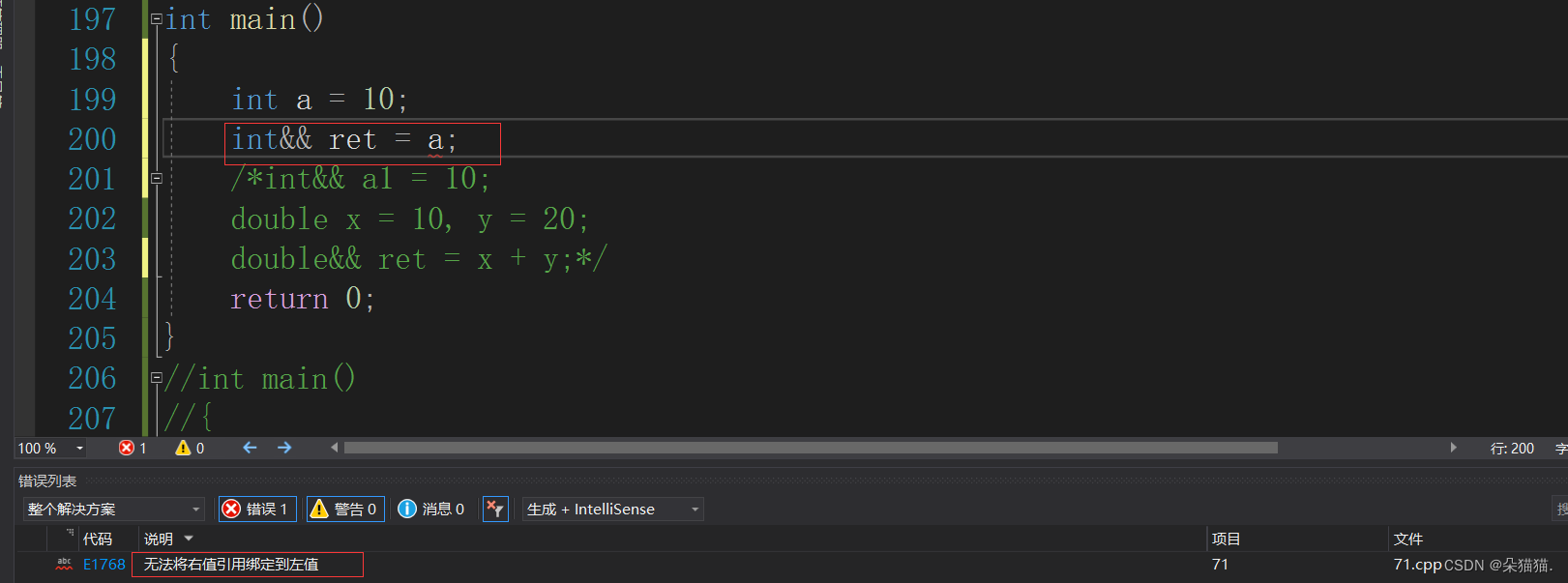
很明显右值引用是无法引用左值的,在这里我们说一个小细节:右值引用可以给move后的左值取别名:
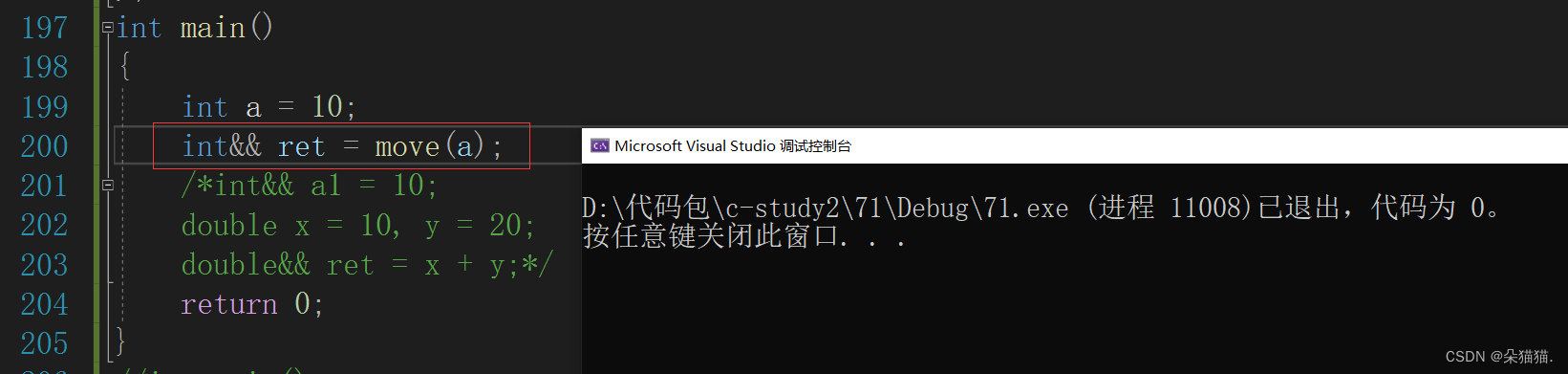
move是什么意思呢?move可以将一个值变成将亡值,比如上图中我们的a变量,这个变量的声明周期本来在这个main函数内,但是经过move后a的声明周期变成了200行这一行,这就是move的作用,也就是move后一定是右值。
下面我们先对比一下左值引用和右值引用,然后我们就进入右值引用+移动语义的学习。
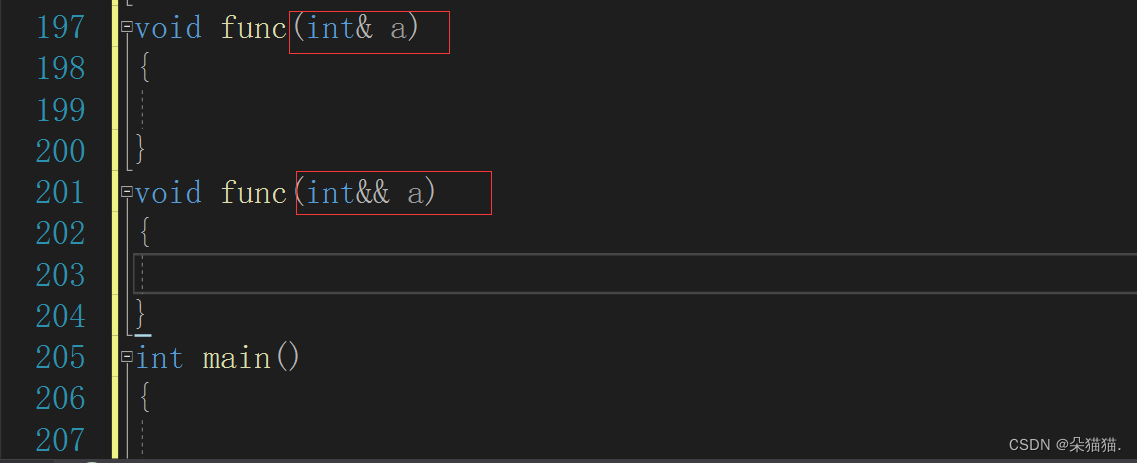
首先我们可以看到左值引用和右值引用是可以构成重载的,下面我们调用一下看看:
void func(int& a)
{cout << "func(int& a)" << endl;
}
void func(int&& a)
{cout << "func(int&& a)" << endl;
}
int main()
{int x = 10, y = 20;func(x);func(x + y);return 0;
}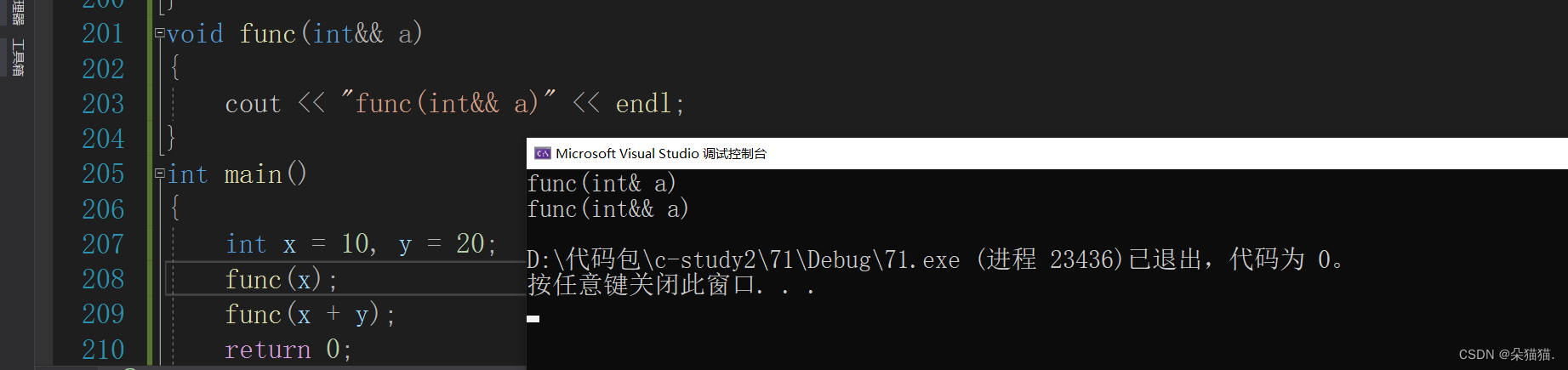
可以看到编译器是可以正确识别左值和右值的,下面我们用string类做一下演示:
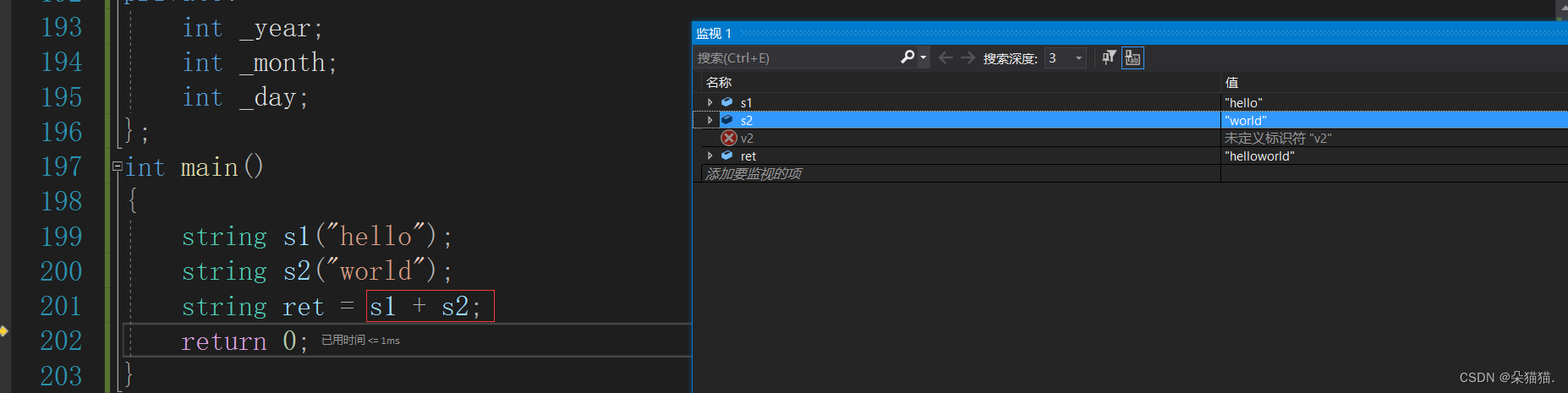
我们可以看到库中的string类是支持右值的,下面我们讲讲这里支持右值的好处:
本来s1+s2的返回值会调用一次拷贝构造构造一个匿名对象,然后再用这个匿名对象调用拷贝构造来给ret(注意这里不是赋值,因为ret是一个新的对象,赋值只针对已经定义过的对象),所以这里耗费的资源是很大的,而有了右值引用+移动语义后这里就变成了直接将返回值和ret交换,也就是说ret直接拿到了s1+s2返回值的资源。下面我们用自己实现的string来试试:
namespace sxy
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}string operator+(char ch){string tmp(*this);tmp += ch;return tmp;}const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};
}int main()
{sxy::string s1("hello world");sxy::string ret1 = s1;sxy::string ret2 = (s1 + '!');return 0;
}上面是我们自己实现的string,是没有实现右值引用版本的:
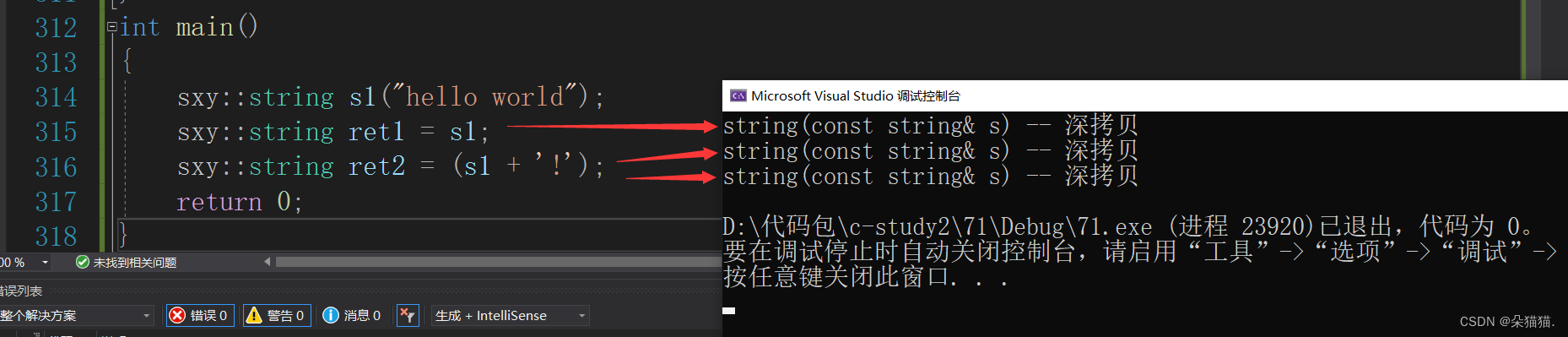
首先构造一个s1,然后用s1拷贝构造ret1,这里调用一次拷贝构造。s1+!是右值,对于表达式首先返回值会调用一次拷贝构造产生一个匿名对象,然后再调用一次拷贝构造用这个匿名对象构造ret2。下面我们加入右值引用版本:
// 移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移动构造" << endl;swap(s);}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动赋值" << endl;swap(s);return *this;}我们再重新运行一下:

首先ret1 = s1会调用一次拷贝构造,而有右值引用后本来ret2只需要移动构造就可以了,但是我们重载运算符+的时候用了拷贝构造:
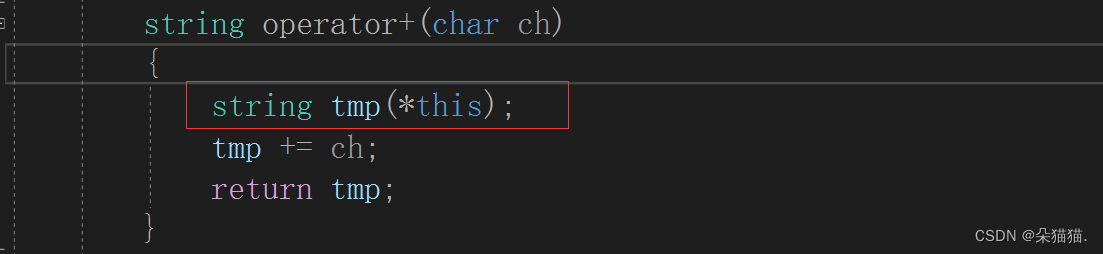
所以才会有如下现象,下面我们看看是如何转移资源的:

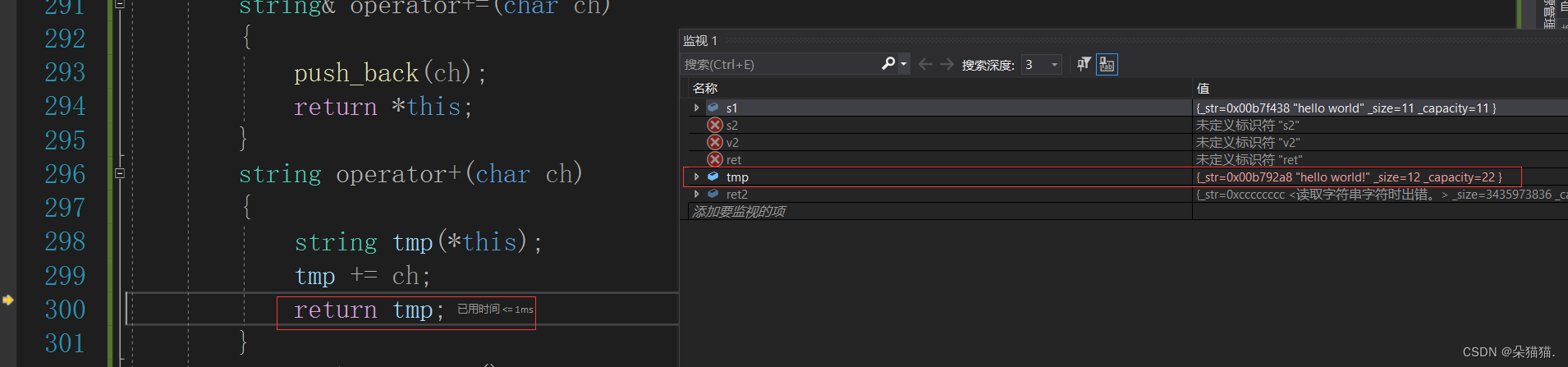

我们可以看到刚开始ret2的地址是0xcccccc,然后调用运算符重载+,进入函数内部本来返回tmp的时候需要拷贝构造一个临时对象,但是对于右值这里调用移动构造直接将tmp和ret2做了交换,所以最后ret2的地址直接变成刚刚tmp的地址了。
下面我们看个更明显的:
int main()
{sxy::string s1("hello world");sxy::string ret1 = s1;sxy::string ret2 = move(s1);return 0;
}

可以看到s1和ret2直接做了资源交换,所以经过move后一个变量就变成了将亡值,这个时候我们再使用s1这个变量就非法访问了,所以我们在用move的时候一定要注意,之前的那个值会变成将亡值不可以被使用。

有了上面这么多案列下面我们总结一下:左值引用直接减少拷贝,可以左值引用传参,也可以传引用返回,但是左值引用不能解决函数内的局部对象不能用引用返回的问题,而这样的问题就需要右值引用进行解决(比如杨辉三角,返回的是一个局部对象的二维数组,深拷贝一个二维数组的代价太大了,用右值引用就可以很好的解决这个问题 )。
C++11以后,STL的所有容器都增加了移动构造,所以我们在平常使用的时候一定是能用右值就用。
下面这种场景会被转移资源吗?
int main()
{sxy::string s1("hello world");move(s1);sxy::string ret2 = s1;return 0;
} 很明显并不会,move实际上是一个函数调用,是这个表达式是个右值,单独访问s1,s1还是右值这里要记住。
很明显并不会,move实际上是一个函数调用,是这个表达式是个右值,单独访问s1,s1还是右值这里要记住。
而在C++11以后,STL所有的容器插入数据接口函数都增加了右值引用版本。


对于链表的插入,普通插入s1需要先拷贝构造一个hello world,然后插入到链表中,而直接插入“hello hello”因为这是一个右值,所以可以直接调用移动构造,直接将这个匿名对象的资源转移到链表中。
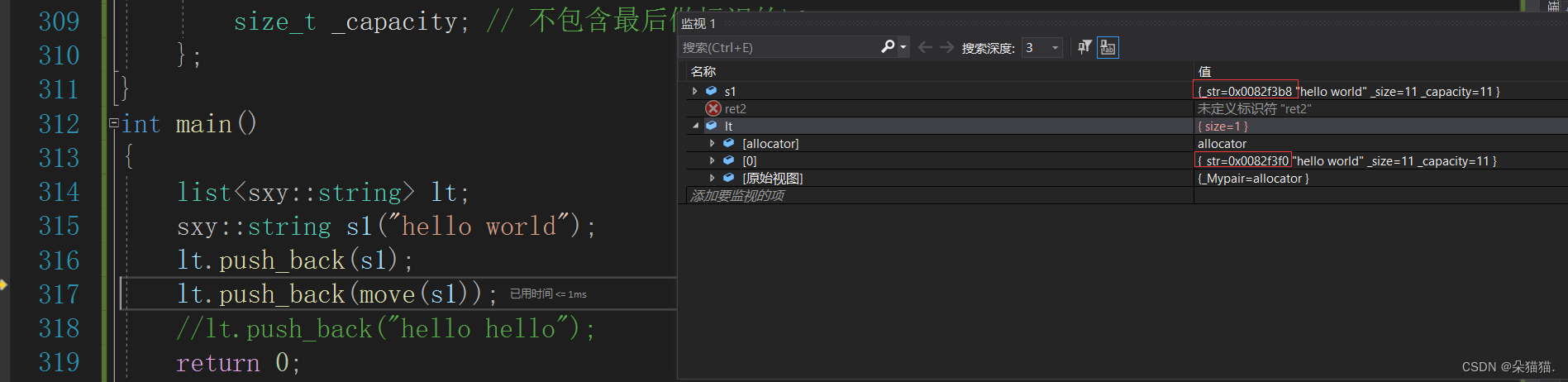
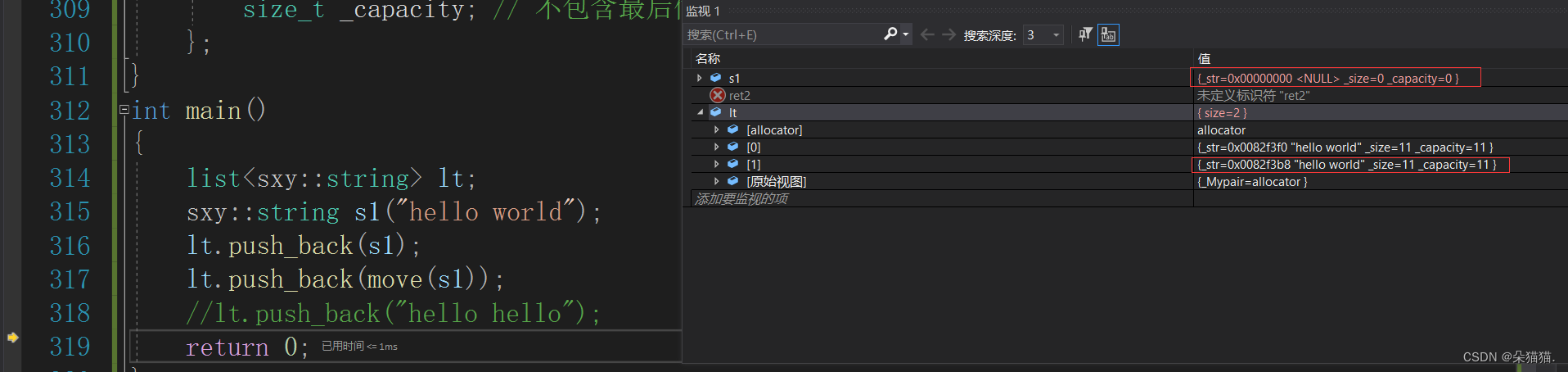 可以看到资源的转移。注意:匿名对象也是右值
可以看到资源的转移。注意:匿名对象也是右值
下面我们再总结一下:左值引用减少拷贝,提高效率。右值引用也是减少拷贝,提高效率。但是他们的角度不同,左值引用是直接减少拷贝。右值引用是间接减少拷贝,识别出是左值还是右值,如果是右值,则不再深拷贝直接移动拷贝提高效率。
下面我们看一看完美转发:
首先我们说明一下:模板中的右值引用是万能引用,既能接收左值又能接收右值。
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{Fun(t);
}
int main()
{PerfectForward(10);int a;PerfectForward(a);PerfectForward(std::move(a));const int b = 8;PerfectForward(b);PerfectForward(std::move(b));return 0;
}下面这段程序可以演示出完美转发的问题,我们先运行看一下结果:
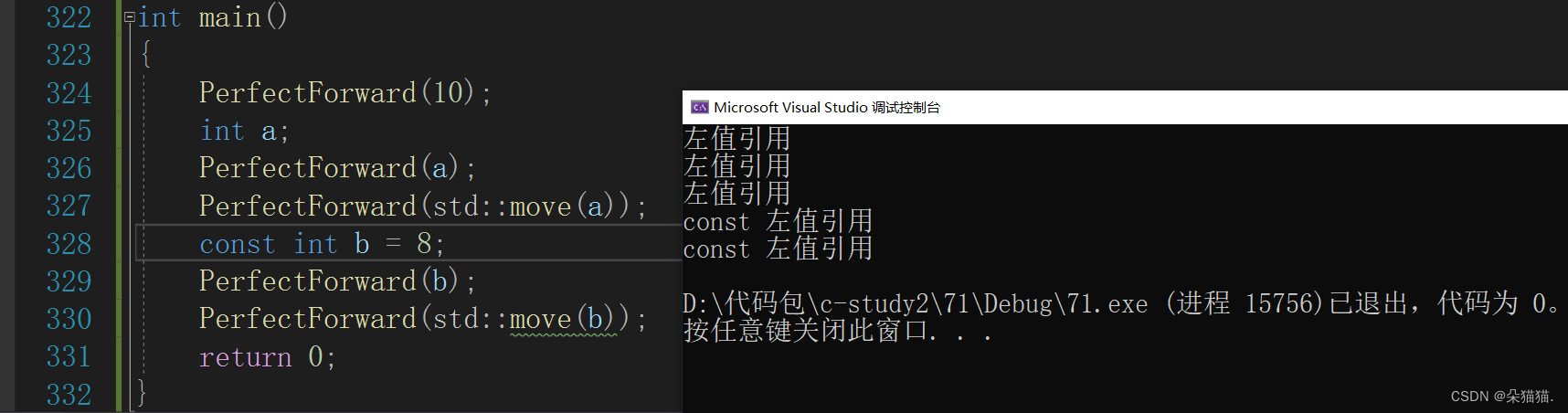
全是左值引用,这是怎么回事呢?(注意:参数传递的时候右值的下一层会变成左值)首先10是右值,进入PF函数后调用Fun函数,而右值进入Fun函数就变成了左值,所以无论左值还是右值进入Fun函数后就变成了左值,这也就是全打印左值的原因,
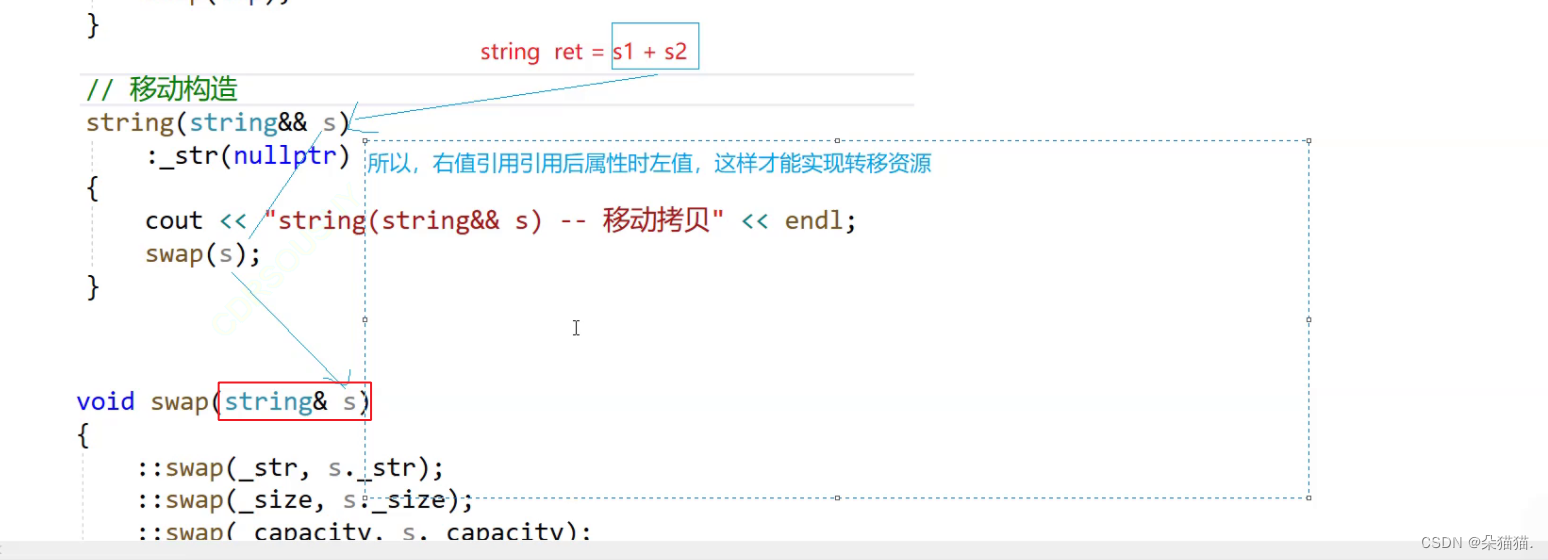
那么如何让他进入fun的时候还是右值呢,用forward完美转发即可,下面我们试一下:

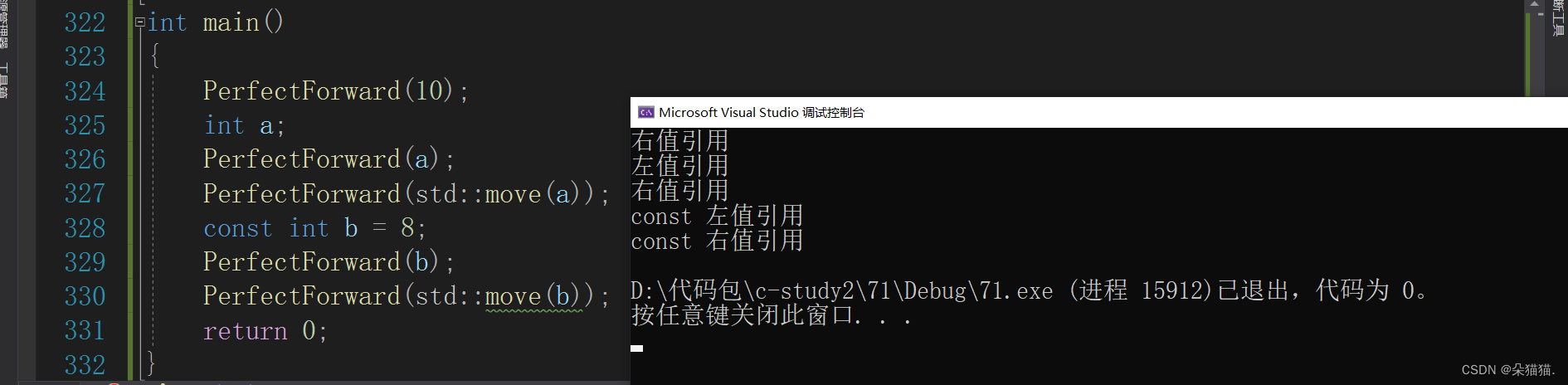 现在就解决了刚刚的问题,也就是说我们使用右值+移动语义的时候,为了让右值一直层层递归下去必须用完美转发。
现在就解决了刚刚的问题,也就是说我们使用右值+移动语义的时候,为了让右值一直层层递归下去必须用完美转发。
下面我们用自己的链表来演示不用完美转发发生的问题:
namespace sxy
{template<class T>struct list_node{list_node(const T& x = T()):_data(x), _next(nullptr), _prev(nullptr){}list_node<T>* _prev;list_node<T>* _next;T _data;};template<class T, class Ref, class Ptr>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T, Ref, Ptr> self;node* _node;list_iterator(node* n):_node(n){}Ref operator*(){return _node->_data;}self& operator++(){_node = _node->_next;return *this;}self operator++(int){self tmp(*this);_node = _node->_next;return tmp;}self& operator--(){_node = _node->_prev;return *this;}self operator--(int){self tmp(*this);_node = _node->_prev;return tmp;}Ptr operator->(){return &_node->_data;}bool operator!=(const self& it){return _node != it._node;}bool operator==(const self& it){return _node == it._node;}};template<class T>class list{public:typedef list_node<T> node;typedef list_iterator<T, T&, T*> iterator;typedef list_iterator<T, const T&, const T*> const_iterator;iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}void empty_init(){_head = new node(T());_head->_next = _head;_head->_prev = _head;}list(){empty_init();}template<class Iterator>list(Iterator first, Iterator last){empty_init();while (first != last){push_back(*first);++first;}}list(const list<T>& ls){empty_init();list<T> tmp(ls.begin(), ls.end());swap(tmp);}list<T>& operator=(list<T> ls){swap(ls);return *this;}void swap(list<T>& ls){std::swap(_head, ls._head);}~list(){clear();delete _head;_head = nullptr;}void push_back(const T& x){insert(end(), x);}void push_back(T&& x){insert(end(), forward<T>(x));}void push_front(const T& x){insert(begin(), x);}void insert(iterator pos, const T& x){node* cur = pos._node;node* prev = cur->_prev;node* newnode = new node(x);newnode->_next = cur;cur->_prev = newnode;newnode->_prev = prev;prev->_next = newnode;}iterator erase(iterator pos){assert(pos != end());node* prev = pos._node->_prev;node* tail = pos._node->_next;prev->_next = tail;tail->_prev = prev;delete pos._node;return iterator(tail);}void pop_front(){erase(begin());}void pop_back(){erase(_head->_prev);}void clear(){iterator it = begin();while (it != end()){//it = erase(it);erase(it++);}}private:node* _head;};
}上面是我们自己实现的list源代码,下面是测试代码:
int main()
{sxy::list<sxy::string> lt;sxy::string s1("hello world");lt.push_back(s1);lt.push_back("hello hello");return 0;
}
我们可以看到,这里都用的深拷贝,这是因为我们自己的list没有实现右值版本,现在我们实现一下:
首先链表插入的时候需要判断是否为右值,所以我们先修改push_back:
void push_back(T&& x){insert(end(), x);}
运行后确实进入了右值版本的push_back
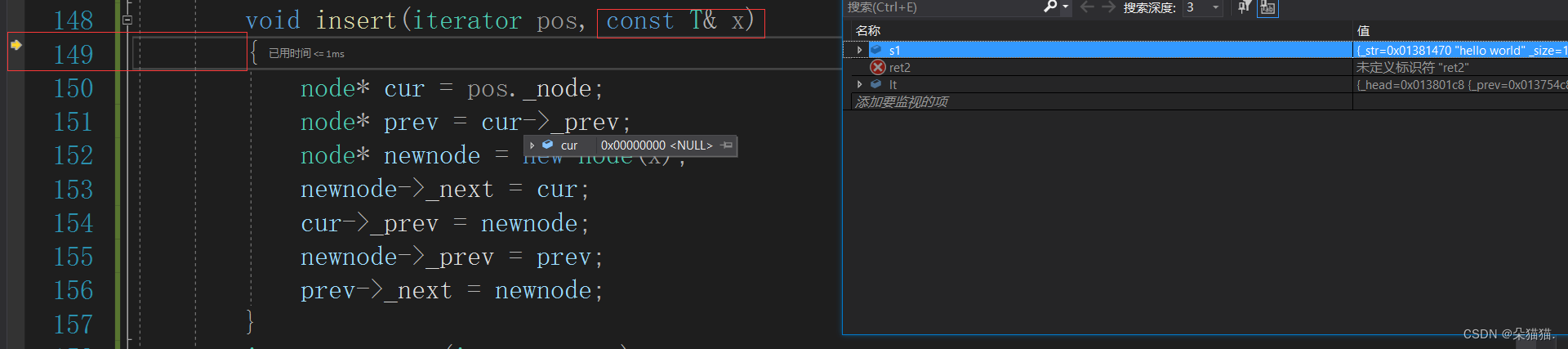
可以看到往下走进入insert的时候进入了左值版本,那么我们再给inser增加一个右值版本:
void insert(iterator pos, T&& x){node* cur = pos._node;node* prev = cur->_prev;node* newnode = new node(x);newnode->_next = cur;cur->_prev = newnode;newnode->_prev = prev;prev->_next = newnode;}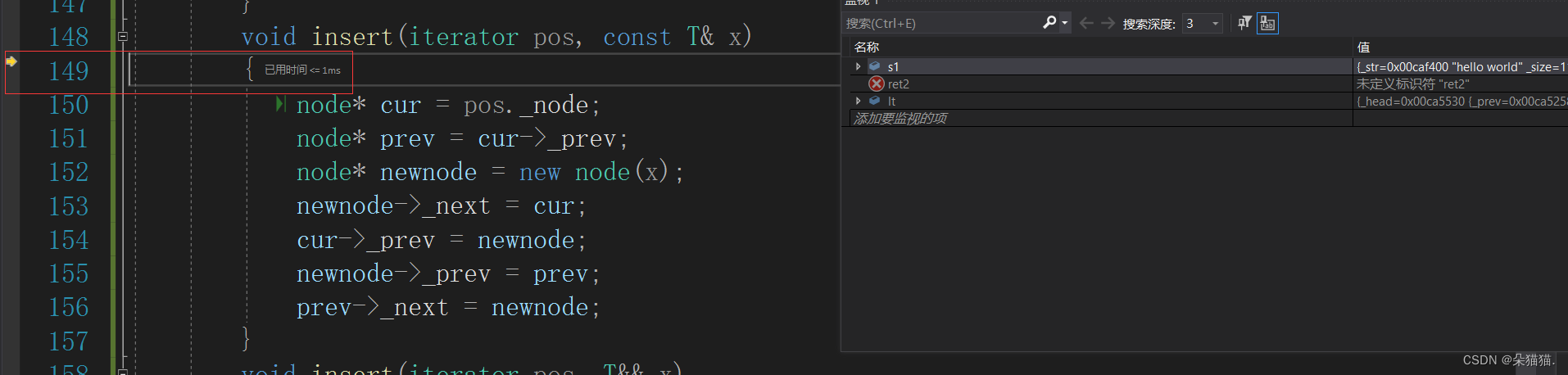
可以看到即使我们实现了右值版本还是没进入,这就是我们刚刚讲的完美转发问题,刚进入的右值进入下一层变成左值了,所以我们现在转发一下:
 下面我们运行起来:
下面我们运行起来:
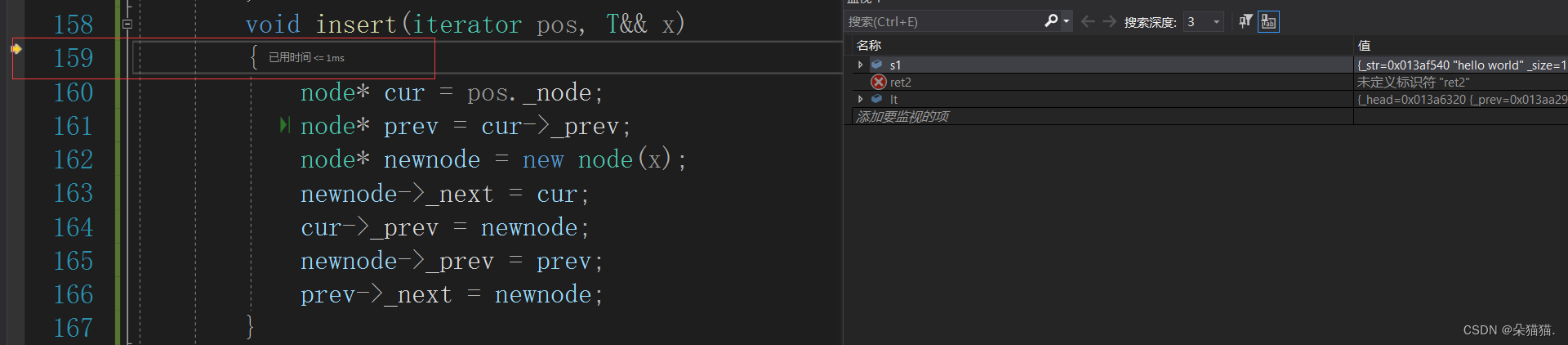
这次成功进入右值版本:
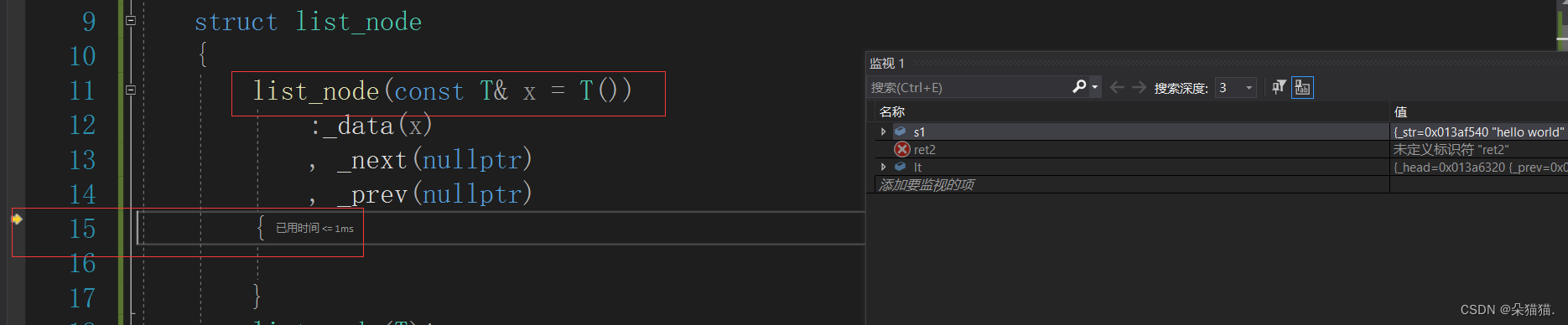
但是在new新节点的时候进入构造函数还是左值版本的构造,所以我们再增加一个右值版本的节点构造:
list_node(T&& x = T()):_data(forward<T>(x)), _next(nullptr), _prev(nullptr){}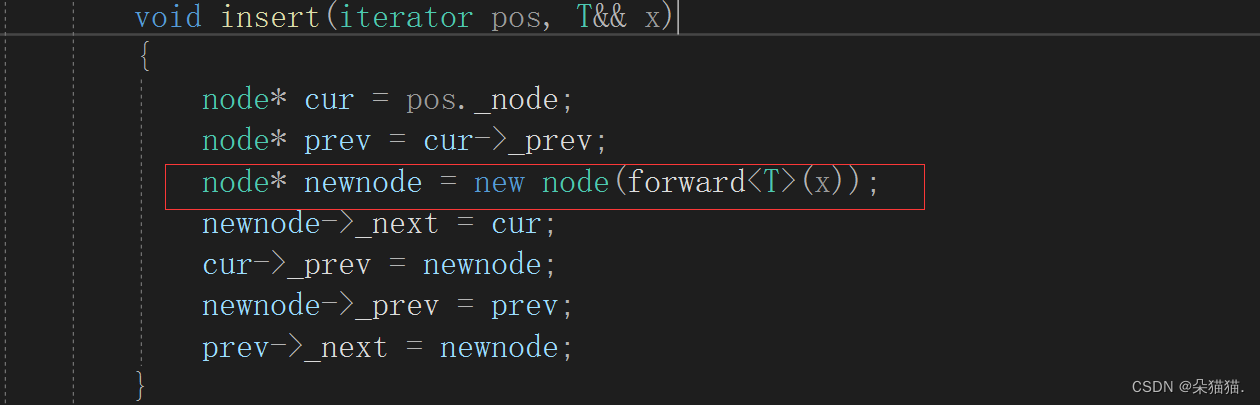
这次我们运行起来:

这次我们看到成功了,以上就是完美转发所引发的问题。
下面我们总结一下:
左值引用和右值引用都是给对象取别名,减少拷贝,左值引用解决了大多数场景问题,下面有些场景是左值引用没有办法解决的:
1.局部对象返回问题。
2.插入接口,对象拷贝问题。
而右值引用+移动语义解决了上面的问题:1.对于浅拷贝的类,移动构造就相当于拷贝构造,因为没有资源的转移。
2.深拷贝的类,这里就是移动构造,对于深拷贝的类,移动构造可以转移右值(将亡值)的资源,没有拷贝提高效率。
下面我们再看看移动赋值,移动赋值与移动构造一样:
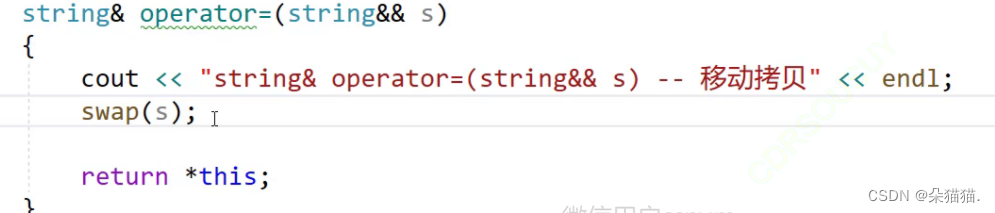
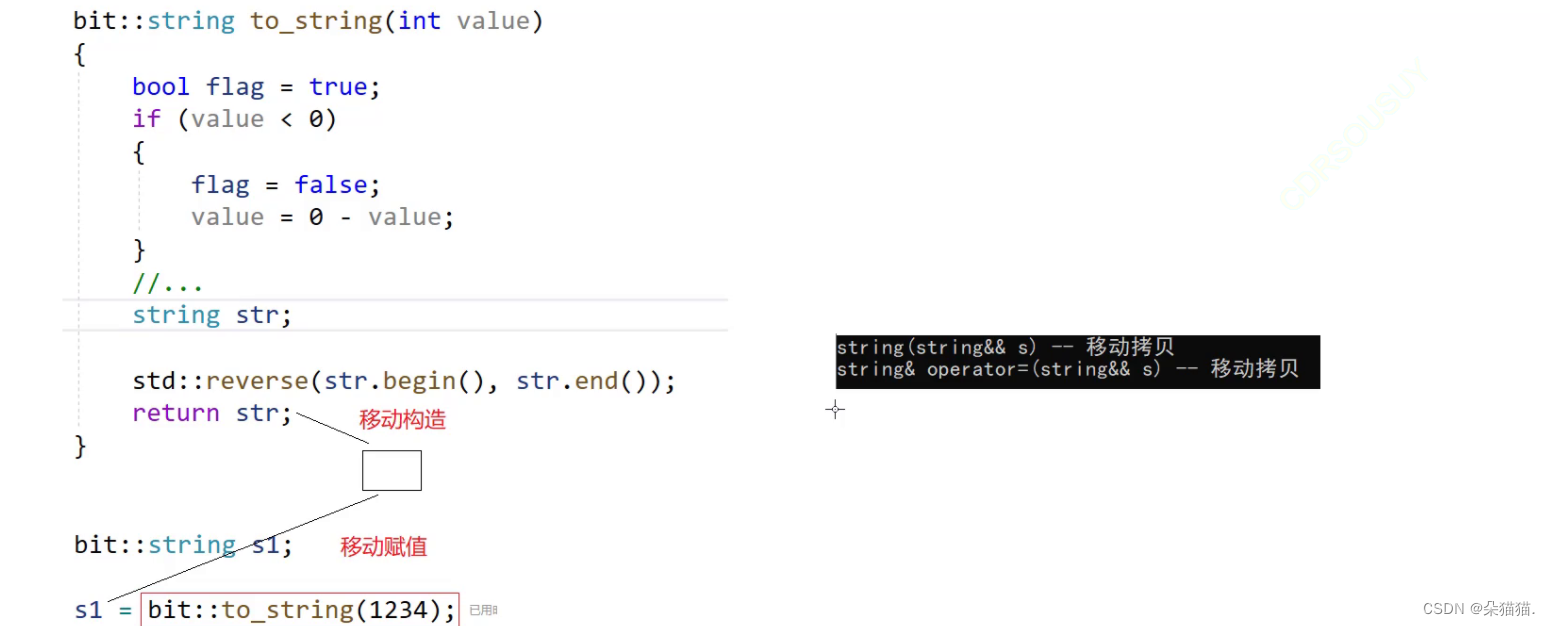
这里我们将to_string函数的返回值赋值给s1,首先这个函数会调用移动构造拿到to_string中的返回值的资源然后再调用移动赋值直接将s1的资源和刚刚返回值的资源做交换,也就是说整体就直接交换了s1和to_string返回值的资源,如果是以前没有移动语义的话这段代码需要这几步:首先to_string函数的返回值调用一次拷贝构造,然后将这个拷贝出来的匿名对象赋值给s1的时候会调用第二次拷贝构造(注意:大多数赋值重载里实现的时候都用的拷贝构造)。
以上就是右值引用+移动语义的全部内容了。
总结
这一篇比较难的就是右值引用,要注意的是:右值引用给我们c++提高了很大的效率,左值+右值引用减少了很多的拷贝,下一篇文章的重点主要是可变参数模板和lambda函数。
![[图表]pyecharts模块-柱状图2](https://img-blog.csdnimg.cn/c8b3348eeb34417cb2d867db12632e15.png#pic_center)




