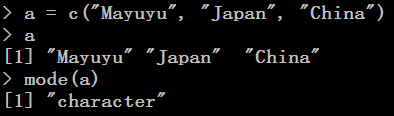
目录
1.加载数据
2. 查看数据
3. 数据类型转化
3.1 批量转化变量为因子型
3.2 插入缺失值
4. 重命名列变量
5. 创建新变量
6. 删除列变量
7. 列变量重排序
8. 行观测重排序
8.1升序排列
8.2 降序排列
8.3 缺失值排序
9. 数据筛选子集
9.1 筛选行数据
9.2 筛选列变量
10. 修改因子水平顺序
11. 修改因子水平名称
12. 连续变量转分类变量
13. 分类变量转分类变量
14. 宽数据转为长数据
15. 长数据转为宽数据
16. 数据集横向合并添加列,可以使用merge()函数
17. 数据集纵向合并添加行
1.加载数据
library(survival) # 加载 survival包
data(cancer) # 导入内置数据集
data <- cancer[1:10, 1:10] # 选取部分数据进行演示2. 查看数据
head(cancer) # 查看数据集前6行
head(cancer, 3) # 查看数据集前3行
tail(cancer) # 查看数据集后6行
tail(cancer, 3) # 查看数据集后3行
View(cancer) # 预览整个数据集
str(cancer) # 查看数据属性结构
names(cancer) # 输出数据框变量名称
dput(names(cancer)) # 输出数据框变量名称,并用c()括起来3. 数据类型转化
3.1 批量转化变量为因子型
class(cancer$sex) # 查看cancer数据集中sex变量的类型
cancer$sex <- as.factor(cancer$sex) # 将cancer数据集中sex变量转化为因子
is.factor(cancer$sex) # 查看cancer数据集中sex变量是否为因子型变量vars <- c("sex", "status") # 选中需要转化为因子的变量
cancer[vars] <- lapply(cancer[vars], factor) # 使用lapply函数批量转化为因子
str(cancer)#查看结构3.2 插入缺失值
cancer$age[c(1,4)] <- NA # 将age变量的第1和第4个数设置为NA4. 重命名列变量
names(cancer)[1:2] <- c("Inst","Time") # 将colon数据框第1、2列变量"inst","time"名修改为"ID","Time"
names(cancer) # 输出colon列变量名,查看是否修改成功5. 创建新变量
mytest <- data.frame(id = c(1, 2, 3, 4, 5),weight = c(45, 50, 55, 60, 58),height = c(165, 155, 157, 169, 158))
options(digits = 4) # 设定有效数字4位
mytest <- transform(mytest, BMI = (weight/((height/100)^2))) # 创建BMI新变量
mytest
mytest$new <- c(1,2,3,4,5)6. 删除列变量
mytest1 <- subset(mytest, select = -weight)
mytest1
mytest2 <- subset(mytest, select = c(-weight, -height)) # 在weight和height变量前加减号就可以删除两个变量
mytest27. 列变量重排序
cancer <- cancer[c(1, 2, 4, 3, 5, 6, 7, 8, 9, 10)]
head(cancer)
cancer <- cancer[c(1:4, 7, 5, 6, 8:10)]
head(cancer)8. 行观测重排序
8.1升序排列
library(dplyr) # 为了使用arrange()
arrange(cancer, age) # 将age按升序排列
arrange(cancer, age, Time) # 先将age变量升序排列,再将Time变量升序排列8.2 降序排列
arrange(cancer, desc(age)) # age按降序排列
arrange(cancer, desc(age), desc(Time)) # 先按age降序排列,再按Time降序排列
arrange(cancer, desc(age), Time) # 先按age降序排列,再按Time升序排列8.3 缺失值排序
arrange(cancer, desc(is.na(pat.karno)))
arrange(cancer, desc(is.na(pat.karno)), pat.karno)9. 数据筛选子集
9.1 筛选行数据
#使用subset()
test <- subset(cancer, sex == 1) # 将筛选后的子集命名为 test
test#可以使用符号 & (AND) 和符号 | (OR)来连接变量
#筛选行数据还可以使用dplyr包的filter()
test <- filter(cancer, sex == 1)
test1 <- filter(cancer, sex == 1 & age >= 60)
test19.2 筛选列变量
test2 <- subset(cancer, sex == 1 & age >= 60,select = c(age, sex))
test210. 修改因子水平顺序
colon
str(colon) # 查看数据结构
colon$rx <- factor(colon$rx, order=TRUE, levels = c("Lev", "Obs","Lev+5FU"))
levels(colon$rx)colon$rx <- factor(colon$rx, levels = rev(levels(colon$rx))) # 颠倒已经改好了的因子顺序, 使用函数rev(levels())
levels(colon$rx)11. 修改因子水平名称
library(plyr) # revalue()函数需要
colon$rx <- revalue(colon$rx, c("Obs" = "观察组", "Lev" = "Lev组","Lev+5FU" = "Lev+5-FU组"))
colon12. 连续变量转分类变量
colon <- within(colon, { agecat <- NA agecat[age > 75] <- "Elder" agecat[age >= 55 & age <= 75] <- "Middle" agecat[age < 55] <- "Young" })colon$agecat <- factor(colon$agecat, order = TRUE, levels = c("Young","Middle","Elder"))
str(colon$agecat)13. 分类变量转分类变量
oldvals <- c("观察组", "Lev组", "Lev+5-FU组") # 指明旧的变量
newvals <- factor(c("观察组", "治疗组", "治疗组")) # 新变量也设置三个水平一一对应
colon$newrx <- newvals[match(colon$rx, oldvals)] # 使用 match() 进行匹配
colon14. 宽数据转为长数据
mydata <- data.frame(id = c(1, 2, 3, 4, 5),age = c(56, 45, 74, 56, 54),testA = c(25, 26, 56, 28, 36),testB = c(15, 29, 36, 48, 52))
mydata# id age testA testB
# 1 1 56 25 15
# 2 2 45 26 29
# 3 3 74 56 36
# 4 4 56 28 48
# 5 5 54 36 52library(reshape2) # melt()函数的包
mytest <- melt(mydata, # 变量来源的数据集id.vars = c(1:2), # 1-2列为保持不变的变量measure.vars = c("testA","testB"), # 需要转换的变量variable.name = "group", # 转换后的变量列名value.name = "value") # 转换后的列的值mytest # 查看转换效果
# id age group value
# 1 1 56 testA 25
# 2 2 45 testA 26
# 3 3 74 testA 56
# 4 4 56 testA 28
# 5 5 54 testA 36
# 6 1 56 testB 15
# 7 2 45 testB 29
# 8 3 74 testB 36
# 9 4 56 testB 48
# 10 5 54 testB 5215. 长数据转为宽数据
library(reshape2) # 为了使用dcast()
mytest1 <- dcast(data = mytest, # 数据源formula = id + age ~ group,# 前面为保持不变的列,后面为需要转换的变量value.var = "value") # 需要转换的列的值
mytest1 #查看输出结果
# id age testA testB
# 1 1 56 25 15
# 2 2 45 26 29
# 3 3 74 56 36
# 4 4 56 28 48
# 5 5 54 36 5216. 数据集横向合并添加列,可以使用merge()函数
testA <- data.frame(id = c(1, 2, 3, 4, 5),study = c(1, 3, 5, 9, 8), age = c(56, 45, 74, 56, 54))
testB <- data.frame(id = c(1, 2, 3, 4, 5),study = c(1, 3, 5, 9, 8), sex = c(1, 2, 1, 2, 2))#共有变量
total <- merge(testA, testB, # 数据框 A和 Bby="id") # 两个数据集的共有变量id,study
total
# id study.x age study.y sex
# 1 1 1 56 1 1
# 2 2 3 45 3 2
# 3 3 5 74 5 1
# 4 4 9 56 9 2
# 5 5 8 54 8 2# 两个共有变量
total1 <- merge(testA, testB, by=c("id","study")) # 两个数据集的共有变量id和study
total1
# id study age sex
# 1 1 1 56 1
# 2 2 3 45 2
# 3 3 5 74 1
# 4 4 9 56 2
# 5 5 8 54 2#直接横向合并两个矩阵或数据框,并且不需要指定一个公共索引,那么可以使用cbind()
total2 <- cbind(testA, testB)
total2
# id study age id study sex
# 1 1 1 56 1 1 1
# 2 2 3 45 2 3 2
# 3 3 5 74 3 5 1
# 4 4 9 56 4 9 2
# 5 5 8 54 5 8 2
17. 数据集纵向合并添加行
# 要纵向合并两个数据框,可以使用rbind()
# 两个数据框必须拥有相同的变量
testA <- data.frame(id = c(1, 2, 3, 4, 5),study = c(1, 3, 5, 9, 8), age = c(56, 45, 74, 56, 54))
testB <- data.frame(id = c(1, 2, 3, 4, 5),study = c(1, 8, 9, 10, 18), age = c(45, 52, 61, 72, 82))
total3 <- rbind(testA, testB)
total3
# id study age
# 1 1 1 56
# 2 2 3 45
# 3 3 5 74
# 4 4 9 56
# 5 5 8 54
# 6 1 1 45
# 7 2 8 52
# 8 3 9 61
# 9 4 10 72
# 10 5 18 82