第1章 R的安装、帮助、工作空间管理
一、R的简介
R定义:一个能够自由有效地用于统计计算和绘图的语言和环境,它提供了广泛的统计分析和绘图技术。
R优势:
- R是免费的开源软件
- 全面的统计研究平台,提供了各种各样的数据分析技术
- R是一个程序设计语言,可以使用用户定义的函数扩展
R资源:
- R主页:http://www.r-project.org
- CRAN(Comprehensive R Archive Network):http://cran.r-project.org
- R的博客:http://www.r-bloggers.com
- R的书籍:《数据挖掘与R语言》、《R语言实战》、《R语言编程艺术》
x<-rnorm(5) #产生5个服从标准正态分布的随机数
x
[1] -0.198391303 0.170254626 0.456807851 0.006009944 -0.156965558
x=5 #用等号赋值
ls() #常看当前变量
[1] “x”
age<-c(1,3,5,2,11,9,3,9,12,3) #用c
age
[1] 1 3 5 2 11 9 3 9 12 3
weight<-c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1)
weight
[1] 4.4 5.3 7.2 5.2 8.5 7.3 6.0 10.4 10.2 6.1
mean(weight) #求均值
[1] 7.06
sd(weight) #求标准差
[1] 2.077498
cor(age,weight) #求相关系数
[1] 0.9075655
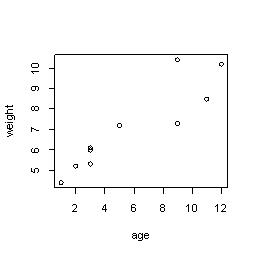
plot(age,weight) #画图
demo() #画图
demo(graphics)

二、帮助
help.start() #查找帮助文档
help(mean) #关于mean的参数说明
?mean #同上
三、工作空间管理
getwd() #当前工作命令
[1] “D:/默认安装的东西”
setwd("E:/R-code") #更改当前路径
getwd()
[1]“E:/R-code”
history() #查看此前的代码

第2章 R包的使用方法、结果的重用、R如何处理大数据集
一、R的包(Package)
- 目前有超过7000个称为包(Package)的用户贡献模块可供使用,可以从http://cran.r-project.org/web/packages下载
- R自带了一系列默认包(包括base、datasets、graphics、methods等等),它们提供了种类繁多的默认函数和数据集
- 包的安装和使用
library() #当前工作环境可使用的包

help(package="base") #查看base包的使用方法
install.packages("car") #安装car包
install.packages("car") #查看car包的使用方法
library(car) #将car包导入当前工作空间
update.packages("car") #更新car包
update.packages() #更新所有包
二、R结果的重用
head(mtcars) #mtcars的数据集

wt:汽车车身的重量
mpg:每加仑汽车可以行使的英里数
lm(mpg~wt,data=mtcars) #mpg~wt的线性关系
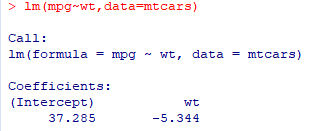
result<-lm(mpg~wt,data=mtcars) #将结果保存到result中
summary(result) #查看result的数据结果
plot(result) #绘图
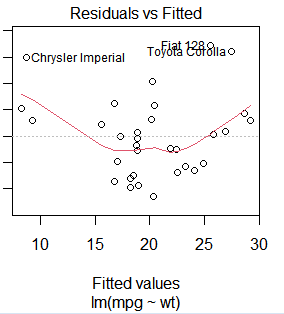
predict(result,mynewdata) #值wt预测mpg,wt即是mynewdata
三、R处理大数据集
-
专门的用于大数据的分析包,如lm()是做线性拟合的函数,而biglim()则能以内存搞笑的方式实现大型数据的线性模型拟合
-
R与大数据处理平台的结合,如RHadoop、RHive、RHipe等

第3章 R数据集的概念、向量、矩阵和数组
一、R的数据集 -
按照某种格式来创建数据集,是任何数据分析的第一步
-选择一种数据结构来存储
-将数据输入或导入到这个数据结构中 -
向R中导入数据有很多方便的方法,可以手工输入数据,也可以从外部源导入数据,数据源可以是电子表格(Excel)、文本文件(txt)、统计软件(SAS)和各类数据库(MySQL)等
-
数据集通常是由数据构成的一个矩形数组,行表示记录,列表示属性(字段)

二、R的数据结构 -
R拥有许多用于存储数据的对象类型,包括向量、矩阵、数组、数据框和列表
-
这些数据结构在存储数据的类型、创建方式、定位和访问其中个别元素的方法等方面都有所不同

三、向量
a<-c(1,3,5,7,2,-4) #创建一个数字类型的一维向量
a
[1] 1 3 5 7 2 -4
b<-c("one","two","three") #创建一个字符串类型的一维向量
b
[1] “one” “two” “three”
c<-c(TRUE,TRUE,FALSE,FALSE,TRUE) #创建一个布尔类型的一维向量
c
[1] TRUE TRUE FALSE FALSE TRUE
a<-c(1,3,5,"one") #创建一个向量,类型会相同
a
[1] “1” “3” “5” “one”
a[3] #取a中的第3个值
[1] “5”
a[c(1,3,4)] #取a中的第1,3,4的值
[1] “1” “5” “one”
a[1:3] #取a中的第1-3的值
[1] “1” “3” “5”
四、矩阵
?matrix #查找matrix的帮助文档
y<-matrix(5:24,nrow=4,ncol=5) #创建一个5行4列的矩阵,默认按列填充
y
[,1] [,2] [,3] [,4] [,5][1,] 5 9 13 17 21[2,] 6 10 14 18 22[3,] 7 11 15 19 23[4,] 8 12 16 20 24
x<-c(2,45,68,94)
rname<-c("R1","R2")
rnames<-c("R1","R2")
cnames<-c("C1","C2")
newMatrix<-matrix(x,nrow=2,ncol=2,byrow=TRUE,dimnames=list(rnames,cnames)) #创建一个按行填充的矩阵
newMatrix
C1 C2
R1 2 45
R2 68 94
newMatrix<-matrix(x,nrow=2,ncol=2,dimnames=list(rnames,cnames)) #创建一个按列填充的矩阵
newMatrix
C1 C2
R1 2 68
R2 45 94
x<-matrix(1:20,nrow=4) #创建一个4行5列的矩阵
x
[,1] [,2] [,3] [,4] [,5][1,] 1 5 9 13 17[2,] 2 6 10 14 18[3,] 3 7 11 15 19[4,] 4 8 12 16 20
x[3,] #查找第3列的数
[1] 3 7 11 15 19
x[2,5] #查找2行5列的数
[1] 18
?array
dim1<-c("A1","A2","A3")
dim2<-c("B1","B2")
dim3<-c("C1","C2","C3","C4")
d<-array(1:24,c(3,2,4),dimnames=list(dim1,dim2,dim3)) #生成4个3行4列的矩阵
d
, , C1
B1 B2
A1 1 4
A2 2 5
A3 3 6
, , C2
B1 B2
A1 7 10
A2 8 11
A3 9 12
, , C3
B1 B2
A1 13 16
A2 14 17
A3 15 18
, , C4
B1 B2
A1 19 22
A2 20 23
A3 21 24
d[1,2,3] #元素16的定位:在第1行第2列第3个
[1] 16
第4章 R数据框、因子、列表
一、数据框
patientID<-c(1,2,3,4) #病人ID
age<-c(25,34,28,52) #年龄
diabetes<-c("Type1","Type2","Type1","Type2") #类型
status<-c("poor","Improved","Excellent","poor") #状况
patientsData<-data.frame(patientID,age,diabetes,status) #病人数据,整合成数据框
patientsData
patientID age diabetes status
1 1 25 Type1 poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type2 poor
patientsData[1:2] #取1-2列的数据
patientID age
1 1 25
2 2 34
3 3 28
4 4 52
patientsData[c("diabetes","status")] #取diabetes和status的数据
diabetes status
1 Type1 poor
2 Type2 Improved
3 Type1 Excellent
4 Type2 poor
patientsData$age #取age的数据集
[1] 25 34 28 52
head(mtcars) #选取mtcars数据集前六行
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
mtcars$mpg #用$符号选取mpg数据集
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
[15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
[29] 15.8 19.7 15.0 21.4
attach(mtcars) #用attach将mtcars数据框添加到R的搜索路径中
mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
[15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
[29] 15.8 19.7 15.0 21.4
detach(mtcars) #用detach将mtcars数据框从到R的搜索路径中移除,但不会改变mtcars本身
mpg #移除后在R的搜索路径中找不对mtcars的数据集
错误: 找不到对象’mpg’
with(mtcars,{
+l<-mpg
+l}
+) #将mpg赋值给l,在with中输出l
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
[15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
[29] 15.8 19.7 15.0 21.4
l #在with之外无法找到l
错误: 找不到对象’l’
二、因子
diabetes
[1] “Type1” “Type2” “Type1” “Type2”
diabetes<-factor(diabetes) #将diabetes转换成因子
]diabetes
[1] Type1 Type2 Type1 Type2
Levels: Type1 Type2
三、列表
g<-"My first list"
h<-c(12,45,43,90)
j<-matrix(1:10,nrow=2)
k<-c("one","two","three")
mylist<-list(g,h,j,k) #创建一个列表,列表中可以是多种数据结构
mylist
[[1]]
[1] “My first list”
[[2]]
[1] 12 45 43 90
[[3]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
[[4]]
[1] “one” “two” “three”
mylist[[2]] #双重方括号访问列表的第二列元素
[1] 12 45 43 90
第5章 R的常用命令
ls() #列举当前内存的工作对象,此时无对象
character(0)
data<-c(1,2,4,5) #创建一个向量data
strings<-"I like R" #创建一个字符型数据
ls() #当前工作空间有两个对象:data和strings
[1] “data” “strings”
rm(data) #移除对象data
ls() #当前工作空间只有对象strings
[1] “strings”
a<-1
A<-1
ls() #区分大小写
[1] “a” “A” “strings”
v<-c(4,7,23,56,32) #创建向量v
length(v) #计算v向量的长度
[1] 5
mode(v) #查看v的数据类型
[1] “numeric”
c<-c(1,2,3,"r") #创建一个向量c
mode(c) #c的数据类型为字符串
[1] “character”
> c
[1] “1” “2” “3” “r”
c[2]<-"test" #将c的第二个数据改为”test”
c #数据c被更改
[1] “1” “test” “3” “r”
x<-c(4,8,9,15,24)
y<-sqrt(x) #对x求平方根再赋值给y
y
[1] 2.000000 2.828427 3.000000 3.872983 4.898979
z<-x+y #将两个向量相加
z
[1] 6.00000 10.82843 12.00000 18.87298 28.89898
x<-c(1,2,3,1,2,3) #x有6个元素
y<-c(2,3,4) #y有3个元素
z<-x+y #x和y成倍数关系,则可进行相加,重复短的那一列进行相加
z
[1] 3 5 7 3 5 7
x<-1:1000 #取1~1000的数
length(x)
[1] 1000
x<-seq(1,10,2) #以序列的方式产生x,[1,10]的数,步长为2
x
[1] 1 3 5 7 9
x<-rep(5,10) #循环生成10个5的向量
x
[1] 5 5 5 5 5 5 5 5 5 5
rep(1:3,3) #1~3的数据循环3次
[1] 1 2 3 1 2 3 1 2 3
rnorm(10) #生成10个服从标准正态分布的数
[1] -0.8033261 -0.4699996 -1.0905840 0.8166522 -1.2559955 1.7089862
[7] 1.5937450 -0.2006823 0.3404796 -0.7786696
rnorm(6,mean=6,sd=2) 生成6个服从均值为6,方差为2的正态分布的数
[1] 7.933261 5.111293 8.689779 7.044589 6.256306 10.605670
x<-c(0,-3,4,-1,45,98,-12)
x[x>0] #取出x>0的数
[1] 4 45 98
x[-5] #取非第5的数
[1] 0 -3 4 -1 98 -12
x[-(1:3)] #取非1~3的数
[1] -1 45 98 -12
第6章 R的list列表详解
mylist<-list(stud.id=1234,
+stud.name="Tom",
+stud.marks=c(12,3,14,25,19)
+)
mylist$stud.id
[1] 1234
$stud.name
[1] “Tom”
$stud.marks
[1] 12 3 14 25 19
mylist[[1]] #取第1列的数
[1] 1234
mylist[[3]] #取第3列的数
[1] 12 3 14 25 19
mylist[1] #取第1列
$stud.id
[1] 1234
mode(mylist[[1]]) #第1列的值为数值型
[1] “numeric”
mode(mylist[1]) #第1列为一个列表
[1] “list”
mylist$stud.id #通过$取stud.id的值
[1] 1234
names(mylist) #查看mylist的列名
[1] “stud.id” “stud.name” “stud.marks”
names(mylist)<-c("id","name","marks") #更改mylist的列名
names(mylist) #mylist列名更改成功
[1] “id” “name” “marks”
mylist$parents<-c("Mna","Jutice") #在mylist列表中添加parents列表
mylist$id
[1] 1234
$name
[1] “Tom”
$marks
[1] 12 3 14 25 19
$parents
[1] “Mna” “Jutice”
length(mylist) #此时mylist的长度
[1] 4
mylist<-mylist[-4] #取非第4列的数据
mylist$id
[1] 1234
$name
[1] “Tom”
$marks
[1] 12 3 14 25 19
other<-list(age=19,sex="male")
other$age
[1] 19
$sex
[1] “male”
lst<-c(mylist,other) #合并两个列表
lst$id
[1] 1234
$name
[1] “Tom”
$marks
[1] 12 3 14 25 19
$age
[1] 19
$sex
[1] “male”
unlist(lst) #将列表转换成向量的形式,但是元素类型要一致
id name marks1 marks2 marks3 marks4 marks5 age sex
“1234” “Tom” “12” “3” “14” “25” “19” “19” “male”
第7章 R的数据源导入方法
一、R可导入的数据源
- 键盘输入
- 从文本文件导入
- 导入Excel数据

二、键盘输入
mydata<-data.frame(age=numeric(0),
+gender=character(0),
+weight=numeric(0)) #创建一个空的数据框
mydata<-edit(mydata) #对空的数据框进行编辑,即从键盘输入数据
mydata

age gender weight isteacher
1 25 m 120 y
2 30 f 140 n
3 18 f 98 n
fix(mydata) #修改mydata的数据,但不用事先赋值给mydata
mydata #数据修改成功

age gender weight isteacher
1 25 m 120 y
2 30 f 140 y
3 18 f 98 y
三、从文本文件导入
data<-read.table("E:/R-code/accident1.txt",header=TRUE,sep=",")
head(data)
id SGBH DMSM1 SGDD SGFSSJ
1 1 3.101176e+15 伤人事故 泗陈公路出余北公路东约3米 2014-8-29 18:30:00
2 2 3.101182e+15 死亡事故 嘉松中路出华隆路南约3000米 2014-8-12 22:55:00
四、导入Excel数据
data<-read.csv("E:/R-code/data.csv",header=TRUE,sep=",")
head(data)
时间 进站人数 出站人数 总人数1 2015-08-01-06.00.00.000000 45 0 452 2015-08-01-06.10.00.000000 33 0 333 2015-08-01-06.20.00.000000 34 3 374 2015-08-01-06.30.00.000000 47 1 485 2015-08-01-06.40.00.000000 61 0 616 2015-08-01-06.50.00.000000 66 57 123
第8章 R的用户自定义函数
R中用户自定义函数的格式:
一、时间函数
mydate<-function(type){
+switch(type,
+long=format(Sys.time(),"%A %B %d %Y"),
+short=format(Sys.time(),"%m-%d-%y"),
+cat(type,"is not recognized type\n")
+)
+}
mydate("long")
[1] “星期日 十二月 26 2021”
> mydate("short")[1] “12-26-21”
mydate("medium")
medium is not recognized type
二、求和函数
sum<-function(num){
+for (i in 1:num){
+x<-x+i
+}}
fix(sum)
sum(3)
[1] 6
第9章 R访问MySQL数据库
R访问MySQL数据库
1.安装RODBC包
2.在http://dev.mysql.com/downloads/connector/odbc下载connectorsODBC
3.windows:控制面板->管理工具->数据源(ODBC)->双击->添加->选中mysql ODBC driver
install.packages("RODBC") #安装RODBC包
library(RODBC) #安装RODBC
myconn<-odbcConnect("Rdata",uid="root",pwd="123456") #连接数据库
data1<-sqlFetch(myconn,"movie") #读取数据库表的数据
head(data1)
id title
1 1 肖申克的救赎
2 2 霸王别姬
3 3 阿甘正传
4 4 这个杀手不太冷
5 5 泰坦尼克号
6 6 美丽人生
data2<-sqlQuery(myconn,"select id,title,context from movie") #读取数据库表数据的另一种方式
head(data2)
id title context
1 1 肖申克的救赎 希望让人自由。
2 2 霸王别姬 风华绝代。
3 3 阿甘正传 一部美国近现代史。
4 4 这个杀手不太冷 怪蜀黍和小萝莉不得不说的故事。
5 5 泰坦尼克号 失去的才是永恒的。
6 6 美丽人生 最美的谎言。
第10章 R的集成开发环境(IDE)–Rstudio
R语言集成开发环境(IDE)-Rstudio,基于C++开发。在基于窗口的R编程中使用特别广泛,相对于R自带的GUI界面,它具有更加友好的界面,更好的项目管理功能、package管理功能、图片预览功能等。
http://www.rstudio.com/