一.基本介绍
1.数据结构(算法)的介绍
(1).数据结构是一门研究算法的学科,自从有了编程语言也就有了数据结构,学好数据结构可以编写出更加漂亮,更加有效率的代码
(2).要学习好数据结构就要多多考虑如何将生活中遇到的问题用程序去实现解决
(3).程序= 数据结构 + 算法
2.数据结构和算法的关系
- 算法是程序的灵魂,为什么有些网站能够在高并发,在海量吞吐情况下依然坚如磐石,大家可能会说:网站使用了服务器群集技术、数据库读写分离和缓存技术(比如 redis等),那么如果再深入的问一句,这些优化技术又是怎样被那些天才的技术高手设计出来的呢?
- 大家请思考一个问题,是什么让不同的人写出的代码从功能看是一样的,但从效率上却有天壤之别,比如:我是做服务器的,环境是UNIX ,功能是要支持上千万人同时在线,并保证数据传输的稳定,在服务器上线前,做内侧,一切 OK.可上线后,服务器就支撑不住了,公司的CTO对我的代码进行优化,再次上线,坚如磐石,那一瞬间,我认识到程序是有灵魂的,就是算法.如果你不想永远都是代码工人,那就花时间来研究下算法
3.案例
(1).试写出用单链表表示的字符串类及字符串结点类的定义,并依次实现它的构造函数、以及计算串长度、串赋值、判断两串相等、求子串、两串连接、求子串在串中位置等7个成员函数
代码如下:
func main() {var str string = "go, golang, hello world"str = strings.Replace(str, "go", "c", -1)fmt.Println(str)
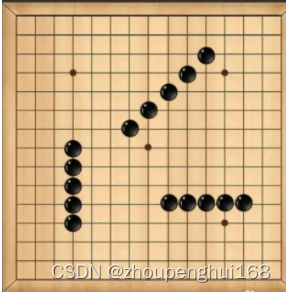
}(2).五子棋:如何判断游戏的输赢,并可以完成存盘退出和继续上局的功能
(3).约瑟夫问题(丢手帕问题)
设编号为 1 , 2 , … n 的 n 个人围坐一圈,约定编号为 k ( 1 <= k <= n)的人从 1 开始报数,数到m的那个人出列,它的下一位又从 1 开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列.
提示:
用一个不带头结点的循环链表来处理josephu问题,先构成一个有 n 个结点的单循环链表,然后由 k 结点起从 1 开始计数,计到m时,对应结点从链表中删除.然后再从被删除结点的下一个结点又从 1 开始计数,直到最后一个结点从链表中删除,算法结束.
(4).邮差问题
战争时期,胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在有六个邮差,从G点出发,需要分别把邮件分别送到 A, B, C , D, E, F 六个村庄
各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里
问:
如何计算出G村庄到 其它各个村庄的最短距离?如果从其它点出发到各个点的最短距离又是多少?
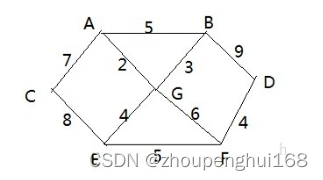
(5).最短路径问题
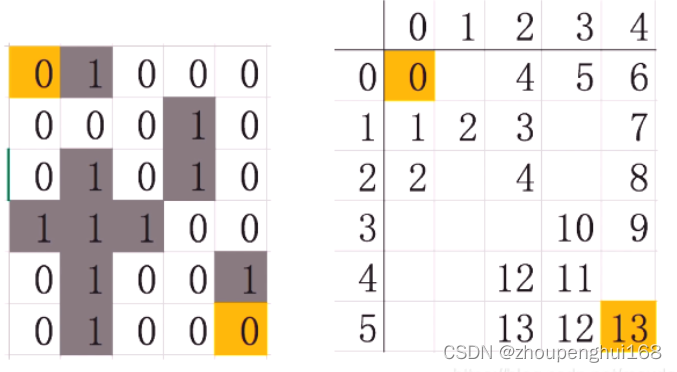
首先是迷宫的表示。如下图,起始位置是左上角黄色位置,重点位置是右下角黄色位置。在这个二维矩阵里,0表示道路通畅,可走;1表示有障碍物,不可走。最终计算出来的结果如右下角所示,从左上角0开始,每走一步,累加一次,这样就可以显示出整条路径的先后顺序。要走最短路径,只要从终点位置,不断递减1寻找上一步的位置直到回到起始位置即可.
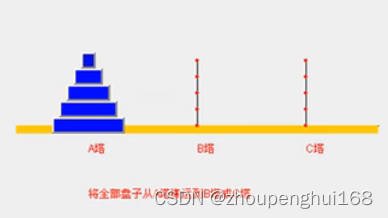
(6).汉诺塔
假设这个游戏中有 3 个柱子,即 A、B 和 C,需要移动的是方块,其中一个柱子上已经有 N 个有序的方块,最大的在底部,方块按顺序越来越小。另外 2 个是空柱子。
基本条件:
- 一次只能移动一颗方块
- 小方块一定要在大方块上面
- 最终目标是将柱子上的所有方块移到另一根柱子上
(7).八皇后问题
- 首先定义一个8*8的棋盘
- 我们有八个皇后在手里,目的是把八个都放在棋盘中
- 位于皇后的水平和垂直方向的棋格不能有其他皇后
- 位于皇后的斜对角线上的棋格不能有其他皇后
- 解出能将八个皇后都放在棋盘中的摆法
二.稀疏数组
1.需求
编写五子棋程序,存盘退出和续上盘功能

分析:
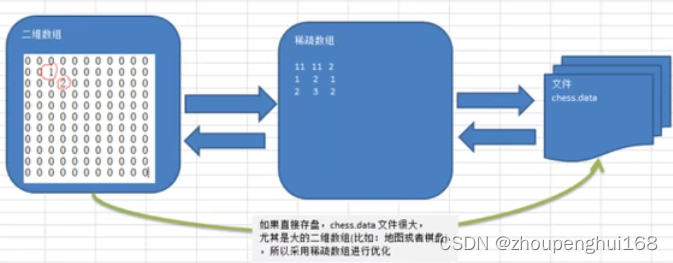
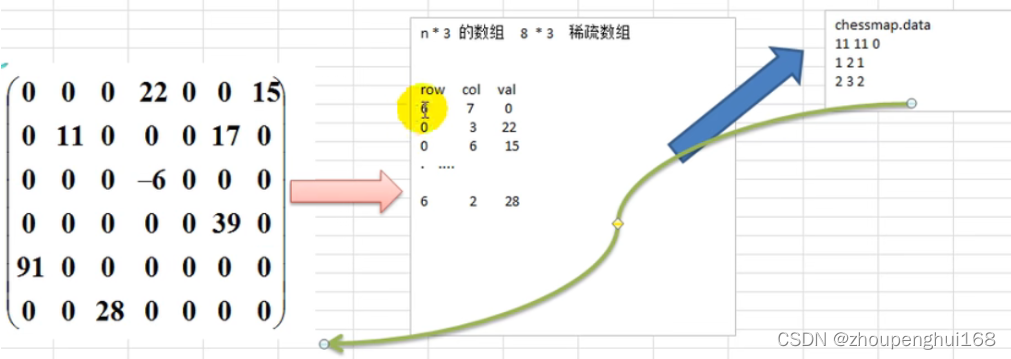
上图中,二维数组中很多数都是默认值(0),因此纪录了很多没有意义的数据,故使用稀疏数组来进行处理
2.基本介绍
当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组
稀疏数组的处理方法是:
(1).记录数组一共有几行几列,有多少个不同的值
(2).把具有不同值的元素的行列及值记录在一个小规模的数组中,从而缩小程序的规模


3.应用实例
(1).使用稀疏数组,来保留类似前面的二维数组棋盘、地图等等)
(2).把稀疏数组存盘,并且可以从新恢复原来的二维数组数
(3).整休思路分析(4).代码实现
代码如下:
package mainimport("fmt""os""bufio""io""strings""strconv"
)type ValNode struct {row int col intval int
}//编写五子棋程序, 有存盘退出和续上盘的功能
func main() {//1.先创建一个原始数组var chessMap [11][11]intchessMap[1][2] = 1 //黑子chessMap[2][3] = 2 //蓝子//2.输出原始数组看看for _, v := range chessMap {for _, v2 := range v {fmt.Printf("%d\t", v2)}fmt.Println()}//3.转换成稀疏数组//思路://1).遍历chessMap,如果发现有一个元素不为零,创建一个node结构体//2).将其放入对应的切片即可//定义切片var spaseArr []ValNode//标准的一个稀疏数组应该还有一个记录元素的二维数组的规模(行和列,默认值)//创建一个ValNode节点valNode := ValNode {row: 11,col: 11,val: 0,}//追加到spaseArr切片中spaseArr = append(spaseArr, valNode)//循环chessMap,把不为零的元素放到spaseArr中for i, v := range chessMap {for j, v2 := range v {if v2 != 0 {//创建一个ValNode 值节点valNode = ValNode{row: i,col: j,val: v2,}spaseArr = append(spaseArr, valNode)}}}//输出稀疏数组fmt.Println("当前的稀疏数组为:")for i, valNode := range spaseArr {fmt.Printf("%d: %d %d %d\n", i, valNode.row, valNode.col, valNode.val)}//将稀疏数组存盘//创建一个新文件//打开一个文件 "f:/www/test2.txt"filePath := "f:/www/chessMap.data"file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)if err != nil {fmt.Printf("open file err =%v\n", err)}//及时关闭filedefer file.Close()var content string//准备写入writer := bufio.NewWriter(file)for _, valNode := range spaseArr {content = fmt.Sprintf("%d %d %d\n", valNode.row, valNode.col, valNode.val)writer.WriteString(content)}writer.Flush()//把存盘的稀疏数组恢复到原始数组//创建一个原始数组var chessMap2 [11][11]int//打开文件,遍历每一行数据file, err = os.Open(filePath)if err != nil {fmt.Println("os.Open file fail, err = ", err)}defer file.Close()//创建一个Readerreader := bufio.NewReader(file)//循环读取reader里的内容//文件中第一行数据过滤掉i := 1for {str, err := reader.ReadString('\n')if err == io.EOF { //读到文件末尾就退出break}if i == 1 {i++continue}//通过空格切割字符串,并转换成数组arr := strings.Fields(string(str))row, err := strconv.ParseInt(arr[0], 10, 64)col, err := strconv.ParseInt(arr[1], 10, 64)val, err := strconv.ParseInt(arr[2], 10, 64)chessMap2[row][col] = int(val)}//打印稀疏数组for _, v := range chessMap2 {for _, v2 := range v {fmt.Printf("%d\t", v2)}fmt.Println()}
}
三.队列(数组实现)
1.队列的应用场景
银行排队案例:

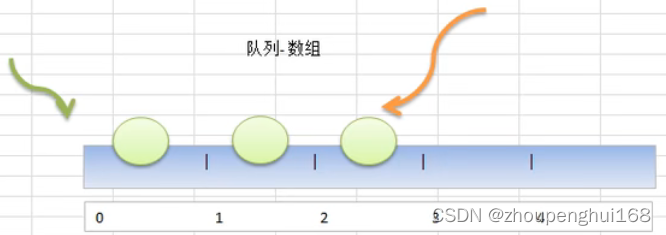
2.队列介绍
队列是一个有序列表,可以用数组或是链表来实现.遵循先入先出的原则。即:先存入队列的数据,要先取出,后存入的要后取出示意图,使用数组模拟队列示意图如下:
3.数组模拟队列
队列本身是有序列表,若使用数组的结构来存储队列的数据,则队列数组的声明如下:其中 maxSize 是该队列的最大容量
因为队列的输出、输入是分别从前后端来处理,因此需要两个变量front及rear分别记录队列前后端的下标, front 会随着数据输出而改变,而rear则是随着数据输入而改变,如图所示:
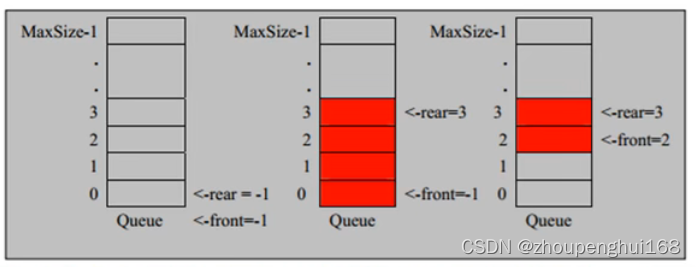
将数据存入队列时称为"addqueue", addqueue 的处理需要有两个步骤
(1).将尾指针往后移: rear + 1 , front ==real [空]
(2).若尾指引 rear 小于等于队列的最大下标 MaxSize -1, 则将数据存入 rear 所指的数组元素,否则无法存入数据

package mainimport ("fmt""errors""os"
)//定义一个结构体,存放队列相关数据
type Queue struct {maxSize int //队列最大数array [5]int // 数组=>模拟队列front int //指向队列首部 rear int //指向队列尾部
}//添加队列数据
func (this *Queue) AddQueue(val int) (err error) {//判断队列是否已满if this.maxSize -1 == this.rear { // rear是队列尾部(含最后一个元素)return errors.New("queue full")} this.rear++ //rear后移this.array[this.rear] = valreturn
}//显示队列:找到队首,然后遍历
func (this *Queue) ShowQueue () {fmt.Println("队列当前情况:")//this.front是不包含队首的元素for i := this.front + 1; i <= this.rear; i++ {fmt.Printf("arrar[%d]=%d\n", i, this.array[i])}
}//从队列中取出数据
func (this *Queue) GetQueue() (val int, err error) {//先判断队列是否为空if this.rear == this.front { //队列为空了return -1, errors.New("queue empty")}this.front++val = this.array[this.front]return val, err
}func main() {//先创建一个队列queue := &Queue {maxSize: 5,front: -1,rear: -1,}var key stringvar val intfor {fmt.Println("1. 输入add,表示添加数据到队列")fmt.Println("2. 输入get,表示从队列获取数据")fmt.Println("3. 输入show,表示显示队列")fmt.Println("4. 输入exit,表示退出队列")fmt.Scanln(&key)switch key {case "add":fmt.Println("输入要入队的对数:")fmt.Scanln(&val)err := queue.AddQueue(val)if err != nil {fmt.Println(err.Error())} else {fmt.Println("加入队列成功")}case "get":val, err := queue.GetQueue()if err != nil {fmt.Println(err.Error())} else {fmt.Printf("从队列中取出的数为:%d\n", val)}case "show":queue.ShowQueue()case "exit":os.Exit(0)default:fmt.Println("输入有误,请重新输入")}}
}对上面代码的小节和说明:
(1).上面代码实现了基本队列结构,但是役有有效的利用数组空间
(2).请思考:如何使用数组实现一个环形的队列
4.环形数组队列
对前面的数组模拟队列的优化,充分利用数组,因此将数组看做是一个环形的( 通过取模的方式来实现即可)
提醒:
(1).尾索引的下一个为头索引时表示队列满,即将队列容量空出一个作为约定,这个在做判断队列满的时候需要注意(tail+1)%maxSize == head(满)
(2).tail == head (空)
分析思路:
(1).什么时候表示队列满? (tail+1)%maxSize == head
(2).什么时候表示队列空? tail == head
(3).初始化时,tail == 0,head == 0
(4).怎么统计该队列有多少个元素? (tail + maxSize - head) % maxSize
代码如下:
package mainimport("fmt""errors""os"
)//定义一个结构体管理环形队列
type CircleQueue struct{ maxSize int //队列最大值:5array [5]int //使用数组 =>队列head int //指向队列队首:0tail int //指向队列队尾:0
}//入队列 AddQueue(push)
func (this *CircleQueue) Push(val int) (err error) {//判断环形队列是否满了if this.IsFull() {return errors.New("queue full")}//this.tail在队列尾部,但是不包含最后一个元素this.array[this.tail] = val //把值给尾部this.tail = (this.tail + 1) % this.maxSizereturn
}//出队列 GetQueue(pop)
func (this *CircleQueue) Pop() (val int, err error) {//判断环形队列是否为空if this.IsEmpty() {return 0, errors.New("queue empty")}//取出:head是指向队首,并且含队首元素val = this.array[this.head]this.head = (this.head + 1) % this.maxSizereturn val, err
}//判断环形队列是否满了
func (this *CircleQueue) IsFull() bool {return (this.tail + 1) % this.maxSize == this.head
}//判断环形队列是否为空
func (this *CircleQueue) IsEmpty() bool {return this.tail == this.head
}//取出环形队列有多少个元素
func (this *CircleQueue) Size() int {//这是个关键的点return (this.tail + this.maxSize - this.head) % this.maxSize
}//显示队列
func (this *CircleQueue) ListQueue() {fmt.Println("环形队列情况如下:")//取出当前队列有多少个元素size := this.Size()if size == 0 {fmt.Println("队列为空")}//定义一个临时变量,指向headtempHead := this.headfor i := 0; i < size; i++ {fmt.Printf("array[%d] = %d\n", tempHead, this.array[tempHead])tempHead = (tempHead + 1) % this.maxSize}}
func main() {//先创建一个队列queue := &CircleQueue {maxSize: 5,head: 0,tail: 0,}var key stringvar val intfor {fmt.Println("1. 输入push,表示添加数据到队列")fmt.Println("2. 输入pop,表示从队列获取数据")fmt.Println("3. 输入list,表示显示队列")fmt.Println("4. 输入exit,表示退出队列")fmt.Scanln(&key)switch key {case "push":fmt.Println("输入要入队的对数:")fmt.Scanln(&val)err := queue.Push(val)if err != nil {fmt.Println(err.Error())} else {fmt.Println("加入队列成功")}case "pop":val, err := queue.Pop()if err != nil {fmt.Println(err.Error())} else {fmt.Printf("从队列中取出的数为:%d\n", val)}case "list":queue.ListQueue()case "exit":os.Exit(0)default:fmt.Println("输入有误,请重新输入")}}
}四.链表
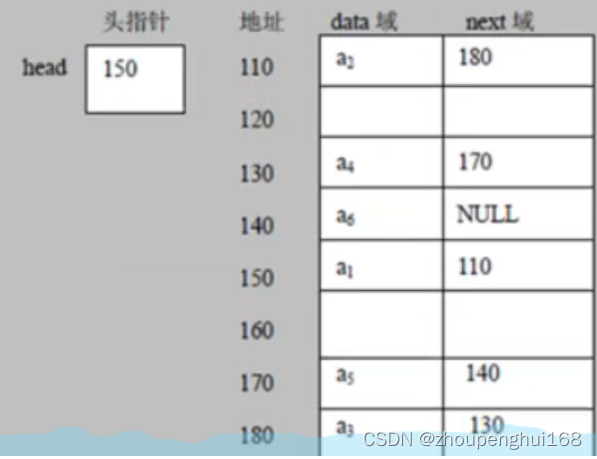
1.链表的介绍
链表是有序的列表,它在内存中的存储如下
2.单链表的介绍
示意图如下:
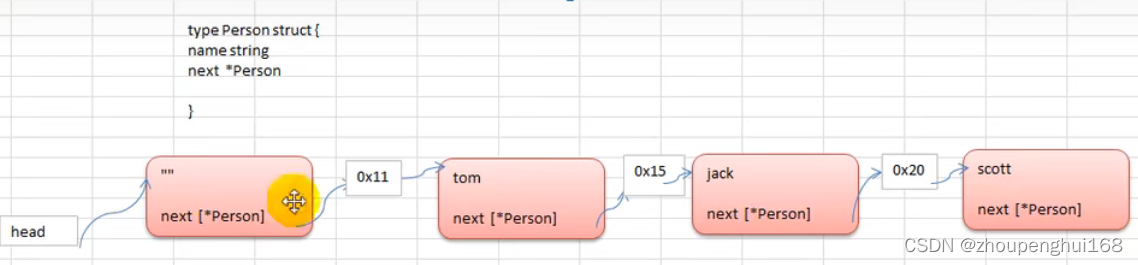
说明: 一般来说,为了比较好的对单链表进行增删改查的操作,都会给其设置一个头结点,头结点的作用主要是用来标识链表头,本身这个结点不存放数据
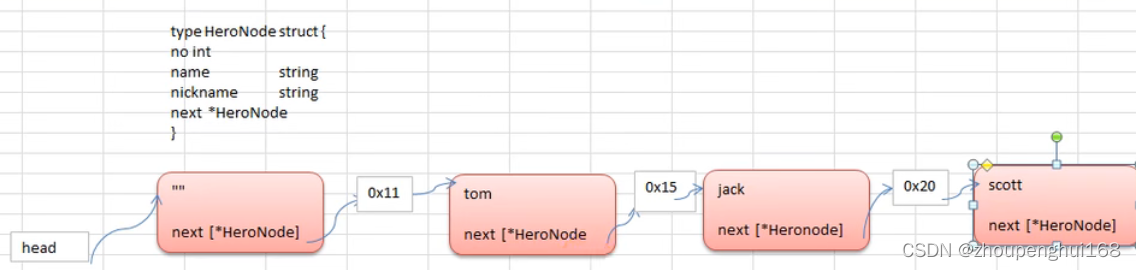
3.单链表的应用实例
使用带 head 头的单向链表实现\:水浒英雄排行榜管理
完成对英雄人物的增删改查操作
在添加英雄时,直接添加到链表的尾部
package mainimport ("fmt"
)//定义一个HeroNode结构体
type HeroNode struct {no intname stringnickname stringnext *HeroNode //表示指向下一个结点
}//给链表插入一个结点
//编写第一种插入方式:在单链表的最后插入
func InsertHeroNode(head *HeroNode, newHeroNode *HeroNode) {//1.先找到链表最后这个结点//2.创建一个辅助结点temp := headfor {if temp.next == nil { //表示找到了最后break}temp = temp.next //让temp不断指向下一个结点}//当for结束时,temp一定是找到了最后一个节点的//3.将newHeroNode加入道最后temp.next = newHeroNode
}//编写第二种插入方式: 根据no的编号从小到大插入
func InsertHeroNode2(head *HeroNode, newHeroNode *HeroNode) {//1.先找适当的结点//2.创建一个辅助结点temp := headflag := true//让插入结点的no和temp的下一个结点的no比较for {if temp.next == nil { //表示到了最后的链表break} else if temp.next.no > newHeroNode.no {//说明newHeroNode就应该插入到temp后面break} else if temp.next.no == newHeroNode.no {//说明链表中已经有这个no,就不允许插入了flag = falsebreak}temp = temp.next //让temp不断指向下一个结点}if !flag {fmt.Println("已存在no=", newHeroNode.no)return} else {newHeroNode.next = temp.nexttemp.next = newHeroNode}
}//显示链表的所有结点信息
func ListHeroNode(head *HeroNode) {//1.创建一个辅助结点temp := head//先判断该链表是不是空的链表if temp.next == nil { fmt.Println("空的链表")return}//2.遍历链表for {fmt.Printf("[%d, %s, %s] ==> ", temp.next.no, temp.next.name, temp.next.nickname)//判断链表是否最后temp = temp.nextif temp.next == nil {break}}
}//删除一个结点
func DelHeroNode(head *HeroNode, id int) {temp := headflag := false//找到要删除的结点的no,和temp的下一个结点的no比较for {if temp.next == nil {//说明到了链表的最后break} else if temp.next.no == id {//说明找到了flag = truebreak}temp = temp.next}if flag {//找到了,就行删除操作temp.next = temp.next.next // 这样目标结点就会成为一个垃圾结点,被系统回收} else {fmt.Println("要删除的结点id不存在")}
}
func main() {//1.先创建一个头结点head := &HeroNode{}//2.创建一个新的结点head1 := &HeroNode{no: 1,name: "宋江",nickname: "及时雨",}head2 := &HeroNode{no: 2,name: "陆静怡",nickname: "玉骑铃",}head3 := &HeroNode{no: 3,name: "零充",nickname: "包子头",}//3.加入//第一种方法// InsertHeroNode(head, head1)// InsertHeroNode(head, head3)// InsertHeroNode(head, head2)//第二种方法InsertHeroNode2(head, head1)InsertHeroNode2(head, head3)InsertHeroNode2(head, head2)//4.列表ListHeroNode(head)//5.删除fmt.Println()DelHeroNode(head, 2)ListHeroNode(head)
}4.双向链表的应用实例
使用带 head 头的双向链表实现:水浒英雄排行榜管理
单向链表的缺点分析:
(1).单向链表,查找的方向只能是一个方向,而双向链表可以向前或者向后查找
(2).单向链表不能自我删除,需要靠辅助节点,而双向链表,则可以自我删除,所以前面单链表删除时节点,总是找到 temp 的下一个节点来删除

package mainimport ("fmt"
)//定义一个HeroNode结构体
type HeroNode struct {no intname stringnickname stringpre *HeroNode //表示指向上一个结点next *HeroNode //表示指向下一个结点
}//给链表插入一个结点
//编写第一种插入方式:在链表的最后插入
func InsertHeroNode(head *HeroNode, newHeroNode *HeroNode) {//1.先找到链表最后这个结点//2.创建一个辅助结点temp := headfor {if temp.next == nil { //表示找到了最后break}temp = temp.next //让temp不断指向下一个结点}//当for结束时,temp一定是找到了最后一个节点的//3.将newHeroNOde加入道最后temp.next = newHeroNode//4.再将temp指向newHeroNode.prenewHeroNode.pre = temp
}//编写第二种插入方式: 根据no的编号从小到大插入
func InsertHeroNode2(head *HeroNode, newHeroNode *HeroNode) {//1.先找适当的结点//2.创建一个辅助结点temp := headflag := true//让插入结点的no和temp的下一个结点的no比较for {if temp.next == nil { //表示到了最后的链表break} else if temp.next.no > newHeroNode.no {//说明newHeroNode就应该插入到temp后面break} else if temp.next.no == newHeroNode.no {//说明链表中已经有这个no,就不允许插入了flag = falsebreak}temp = temp.next //让temp不断指向下一个结点}if !flag {fmt.Println("已存在no=", newHeroNode.no)return} else {newHeroNode.next = temp.nextnewHeroNode.pre = tempif temp.next != nil {temp.next.pre = newHeroNode}temp.next = newHeroNode}
}//显示链表的所有信息:顺序方式
func ListHeroNode(head *HeroNode) {//1.创建一个辅助结点temp := head//先判断该链表是不是空的链表if temp.next == nil { fmt.Println("空的链表")return}//2.遍历链表for {fmt.Printf("[%d, %s, %s] ==> ", temp.next.no, temp.next.name, temp.next.nickname)//判断链表是否最后temp = temp.nextif temp.next == nil {break}}
}//显示链表的所有信息:逆序方式
func ListHeroNode2(head *HeroNode) {//1.创建一个辅助结点temp := head//先判断该链表是不是空的链表if temp.next == nil { fmt.Println("空的链表")return}//2.让temp定位到双向链表的最后结点for {if temp.next == nil {break}temp = temp.next}//2.遍历链表for {fmt.Printf("[%d, %s, %s] <== ", temp.no, temp.name, temp.nickname)//判断链表是否到headtemp = temp.preif temp.pre == nil {break}}
}//删除一个结点
func DelHeroNode(head *HeroNode, id int) {temp := headflag := false//找到要删除的结点的no,和temp的下一个结点的no比较for {if temp.next == nil {//说明到了链表的最后break} else if temp.next.no == id {//说明找到了flag = truebreak}temp = temp.next}if flag {//找到了,就行删除操作temp.next = temp.next.next // 这样目标结点就会成为一个垃圾结点,被系统回收if temp.next != nil { //当下一个结点存在时,才操作temp.next.pre = temp}} else {fmt.Println("要删除的结点id不存在")}
}
func main() {//1.先创建一个头结点head := &HeroNode{}//2.创建一个新的结点head1 := &HeroNode{no: 1,name: "宋江",nickname: "及时雨",}head2 := &HeroNode{no: 2,name: "陆静怡",nickname: "玉骑铃",}head3 := &HeroNode{no: 3,name: "零充",nickname: "包子头",}//3.加入//第一种方法InsertHeroNode(head, head1)InsertHeroNode(head, head2)InsertHeroNode(head, head3)//第二种方法// InsertHeroNode2(head, head1)// InsertHeroNode2(head, head3)// InsertHeroNode2(head, head2)// //4.列表//顺序ListHeroNode(head)fmt.Println()//逆序ListHeroNode2(head)// //5.删除// fmt.Println()DelHeroNode(head, 2)ListHeroNode(head)
}5.单向环形链表的应用场景
josephu 问题:
设编号为1, 2 ,... n 的n个人围坐一圈, 约定编号为 k (1<=k<=n )的人从 1 开始报数,数到m的那个人出列,它的下一位又从1开始报数,数到 m 的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列
提示:
用一个不带头结点的循环链表来处理josephu问题,先构成一个有 n 个结点的单循环链表,然后由 k 结点起从1开始计数,计到 m 时,对应结点从链表中删除,然后再从被删除结点的下一个结点又从 1 开始计数,直到最后一个结点从链表中删除,算法结束
6.环形单向链表的介绍
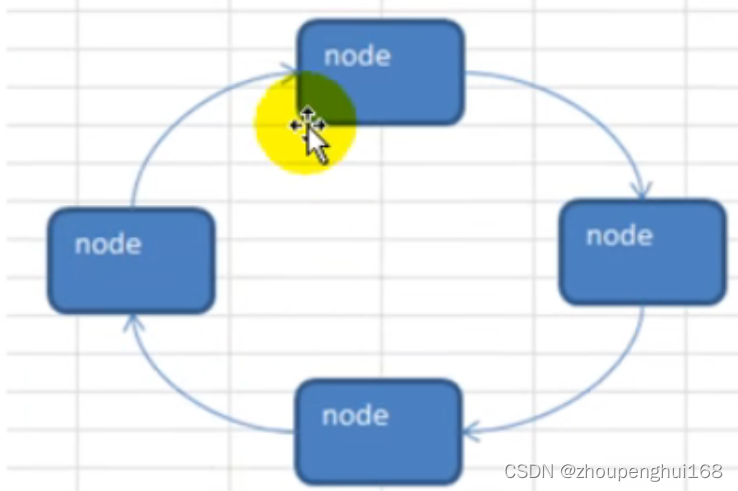
7.环形单向链表应用案例
完成对单向环形链表的添加结点,删除结点和显示
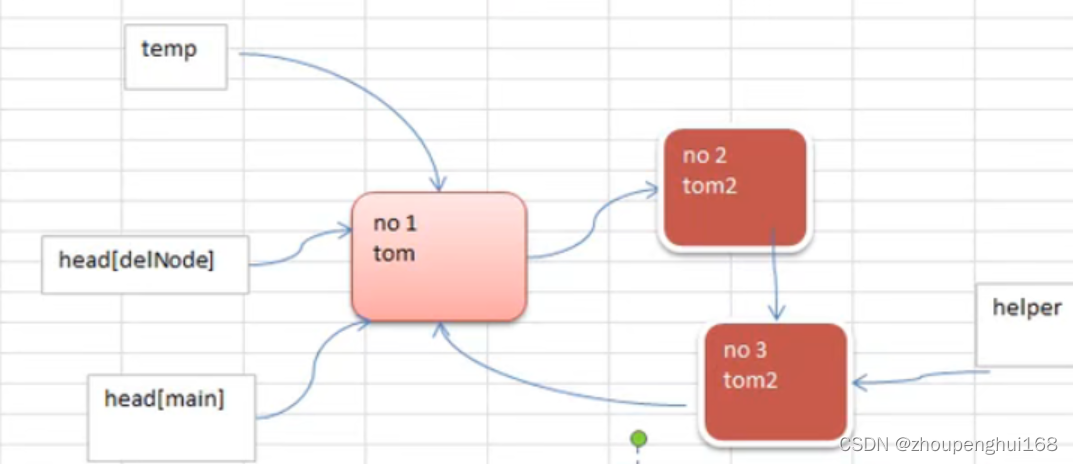
删除一个环形单向琏表的思路如下:
1.先让 temp 指向 head
2.让 helper 指向环形链表最后
3.让temp 和要删除的id进行比较,如果相同,则同helper完成删除(这里必须考虑如果删除的就是头结点)
package mainimport ("fmt"
)//定义一个CatNode结构体
type CatNode struct {no int //猫的编号name string //名字next *CatNode //下一个结点
}//插入环形链表
func InsertCatNode(head *CatNode, newCatNode *CatNode) {//判断是不是添加第一只猫if head.next == nil {head.no = newCatNode.nohead.name = newCatNode.namehead.next = head // 构成一个环形fmt.Println(newCatNode, "加入到环形的链表")return } //先定义一个临时的变量,找到环形的最后结点temp := headfor {if temp.next == head {break}temp = temp.next}//加入到链表temp.next = newCatNodenewCatNode.next = head
}//显示环形链表
func ListCircleLink(head *CatNode) {temp := headif temp.next == nil {fmt.Println("空的链表")return}for {fmt.Printf("猫的信息为:no=%d,name=%s, =>\n", temp.no, temp.name)if temp.next == head {//说明链表环状查询完毕break}temp = temp.next}
}//删除
func DelCircleCatNode(head *CatNode, id int) *CatNode {temp := headhelper := head//空链表if temp.next == nil {fmt.Println("空链表")return head}//如果只有一个结点if temp.next == head {temp.next = nilreturn head}//将helper定位到环形链表最后for {if helper.next == head {break}helper = helper.next}//如果有两个以及以上的结点flag := truefor {if temp.next == head { //说明已经比较到最后一个(最后一个还没比较)break}if temp.no == id { // 找到了if temp == head { // 说明删除的是头结点head = temp.next}//可以在这里删除helper.next = temp.nextfmt.Printf("猫:%d已经被删除了\n", id)flag = falsebreak}temp = temp.next // 移动,目的是为了 "比较"helper = helper.next // 移动,目的是为了删除结点}//这里还要比较一次if flag { // 如果flag为true,则上面没有删除if temp.no == id {helper.next = temp.nextfmt.Printf("猫:%d已经被删除了\n", id)} else {fmt.Printf("没有该猫,no=%d\n", id)}}return head
}
func main() {//初始化一个环形链表的头结点head := &CatNode{}//创建一只猫cat1 := &CatNode{no: 1,name: "tom",}cat2 := &CatNode{no: 2,name: "jack",}cat3 := &CatNode{no: 3,name: "mary",}InsertCatNode(head, cat1)InsertCatNode(head, cat2)InsertCatNode(head, cat3)ListCircleLink(head)head = DelCircleCatNode(head, 2)ListCircleLink(head)
}创建一个链表模拟队列,实现数据入队列,数据出队列,显示队列
package mainimport ("fmt""errors""os"
)//定义一个结构体管理环形队列
type CircleQueue struct {maxSize int //队列最大值:5array [5]int //使用数组 =>队列head int //指向队列队首:0tail int //指向队列队尾:0
}//入队列 AddQueue(push)
func (this *CircleQueue) Push(val int) (err error) {//判断环形队列是否满了if this.IsFull() {return errors.New("queue full")}//this.tail在队列尾部,但是不包含最后一个元素this.array[this.tail] = val //把值给尾部this.tail = (this.tail + 1) % this.maxSizereturn
}//出队列 GetQueue(pop)
func (this *CircleQueue) Pop() (val int, err error) {//判断环形队列是否为空if this.IsEmpty() {return 0, errors.New("queue empty")}//取出:head是指向队首,并且含队首元素val = this.array[this.head]this.head = (this.head + 1) % this.maxSizereturn val, err
}//判断环形队列是否满了
func (this *CircleQueue) IsFull() bool {return (this.tail+1)%this.maxSize == this.head
}//判断环形队列是否为空
func (this *CircleQueue) IsEmpty() bool {return this.tail == this.head
}//取出环形队列有多少个元素
func (this *CircleQueue) Size() int {//这是个关键的点return (this.tail + this.maxSize - this.head) % this.maxSize
}//显示队列
func (this *CircleQueue) ListQueue() {fmt.Println("环形队列情况如下:")//取出当前队列有多少个元素size := this.Size()if size == 0 {fmt.Println("队列为空")}//定义一个临时变量,指向headtempHead := this.headfor i := 0; i < size; i++ {fmt.Printf("array[%d] = %d\n", tempHead, this.array[tempHead])tempHead = (tempHead + 1) % this.maxSize}}
func main() {//先创建一个队列queue := &CircleQueue{maxSize: 5,head: 0,tail: 0,}var key stringvar val intfor {fmt.Println("1. 输入push,表示添加数据到队列")fmt.Println("2. 输入pop,表示从队列获取数据")fmt.Println("3. 输入list,表示显示队列")fmt.Println("4. 输入exit,表示退出队列")fmt.Scanln(&key)switch key {case "push":fmt.Println("输入要入队的对数:")fmt.Scanln(&val)err := queue.Push(val)if err != nil {fmt.Println(err.Error())} else {fmt.Println("加入队列成功")}case "pop":val, err := queue.Pop()if err != nil {fmt.Println(err.Error())} else {fmt.Printf("从队列中取出的数为:%d\n", val)}case "list":queue.ListQueue()case "exit":os.Exit(0)default:fmt.Println("输入有误,请重新输入")}}
}
[上一节][go学习笔记.第十七章.redis的使用] 1.redis的使用