Java性能权威指南-总结4
- Java性能调优工具箱
- 操作系统的工具和分析
- CPU运行队列
- 磁盘使用率
- 网络使用率
- Java监控工具
- 基本的VM信息
Java性能调优工具箱
操作系统的工具和分析
CPU运行队列
快速小结
- 检查应用性能时,首先应该审查CPU时间。
- 优化代码的目的是提升而不是降低(更短时间段内的)CPU使用率。
- 在试图深入优化应用前,应该先弄清楚为何CPU使用率低。
磁盘使用率
监控磁盘使用率有两个目的。第一个目的与应用本身有关:如果应用正在做大量的磁盘I/O操作,那I/O就很容易成为瓶颈。
想了解何时磁盘I/O是瓶颈非常困难,因为这取决于应用的行为。如果应用往磁盘写数据时没有有效的缓冲,磁盘I/O的统计数据就会非常低。但是,如果应用执行的I/O超过了磁盘的承载,磁盘I/O的统计数据就会非常高。这两种情形的性能都需要提升。
有些系统的基本I/O监控要好于其他系统。这是Linux系统iostat的部分输出:
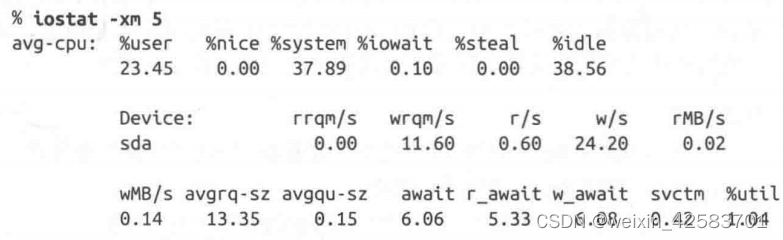
应用正在往磁盘sda写数据。乍一看,磁盘统计数据还不错。w_await——每次I/O写的时间——相当低(6.08毫秒),磁盘使用率只有1.04%。(可接受的值取决于物理磁盘,在低于15毫秒时。)但这里有条线索可以看出点问题:系统在内核花费了37.89%的时间。一种可能是系统正在进行其他I/O(在其他程序中)。如果这个系统时间都来自被测的应用,说明某些低效率的事正在发生。
另一条线索是,系统每秒写为24.2:当每秒写入只有0.14MB时,这算很大的数字。这说明I/O已经是瓶颈,接下来应该检查应用是如何写的。
如果磁盘速度赶不上I/O请求,问题的另外一面就出现了:

Linux好处在于可以立即告诉我们磁盘的使用率为100%。它也能告诉我们进程的47.89%的事件在iowait(表示正在等待磁盘)。
监控磁盘使用率的第二个理由是——即便预计应用不会有很高的I/O——有助于监控系统是否在进行内存交换。计算机的物理内存量是固定的,但它们可以用大得多的虚拟内存来运行一系列应用。应用会保留更多超过它们实际所需的内存量,并且它们通常也只使用分配给它们的内存的一部分。这两种情况下,操作系统可以将不用的内存保留在磁盘上,在需要时换页到物理内存。
大多数情况下,这种类型的内存管理可以工作得很好,特别是交互式应用和GUI程序。这种管理方式对服务器类应用来说效果稍差,因为这些应用需要更多内存。由于Java堆的原因,这种管理方式对于任何Java程序来说都比较糟糕。
正在内存交换的系统——从主内存移动数据到磁盘或者反过来——一般来说,性能比较差。还有其他系统工具可以报告系统交换,例如vmstat输出中有两列(si是换进,so是换出)可以警告我们系统是否正在交换。磁盘活动说明内存交换可能正在发生。
快速小结
- 对于所有应用来说,监控磁盘使用率非常重要。即便不直接写磁盘的应用,系统交换仍然会影响它们的性能。
- 写入磁盘的应用遇到瓶颈,是因为写入数据的效率不高(吞吐量太低),或者是因为写入太多数据(吞吐量太高)。
网络使用率
如果应用运行时需要网络——比如Java EE应用服务器——也必须监控网络流量。网络使用率类似磁盘流量:应用可能没有充分利用网络所以带宽很低,或者写入某网络接口的总数据量超过了它所能处理的量。
由于标准的系统工具通常只能显示某个网络接口发送和接收的数据报数和字节数,所以它们在监控网络流量方面差强人意。虽然这些信息有用,但无法告诉我们网络是没有充分利用,还是过度使用。Unix系统监控网络的基本工具是netstat它可以显示每个网络接口的流量概要,包括网络接口的使用度:

示例中的e1000g1是1000 MB接口,使用率非常低(0.33%)。这个工具(以及其他类似的工具)可以用来计算接口的使用率。在上述输出中,接口的数据写入速率是225.7 Kbps,读取速率是176.2 Kbps。对于1000MB的网络,相除以后可以得到使用率0.33%,nicstat也能自动算出接口的带宽。
typeperf或netstat这样的工具可以报告读取和写入的数据,但是要计算网络使用率,必须自己用脚本计算接口的带宽。一般工具报告的单位是字节/秒(Bps),但带宽的单位是位/秒(bps)。1000兆位网络每秒处理125兆字节(MB)。本示例中,读为0.22 MBps,写为0.16 MBps,相加然后除以125得出使用率为0.33%。nicstat更便于使用。
网络无法支持100%的使用率。 对本地以太局域网来说,承受的网络使用率超过40%就意味着接口饱和了。如果网络是包交换或使用不同的传输介质,网络使用率的最大值就可能会不同,因此最好是评估网络架构之后再确定合适的值。这个值与Java无关,只是简单利用网络参数和操作系统接口。
快速小结
- 对基于网络的应用来说,务必要监控网络以确保它不是瓶颈。
-
往网络写数据的应用遇到瓶颈,可能是因为写数据的效率太低(吞吐量太低),也可能是因为写入了太多的数据(吞吐量太高)。
Java监控工具
要想深入了解JVM自身,需要使用Java的监控工具。JDK自带以下所列工具:
- jcnd
用来打印Java进程所涉及的基本类、线程和VM信息。它适用于脚本,可以像这样执行:
%jcmd process_id conmand optional_arguments
jcmd help可以列出所有的命令。jcmd help <command>可以给出特定命令的语法。
- ·jconsole
提供JVM活动的图形化视图,包括线程的使用、类的使用和GC活动。
- ·jhat
读取内存堆转储,并有助于分析。这是事后使用的工具。
- jmap
提供堆转储和其他JVM内存使用的信息。可以适用于脚本,但堆转储必须在事后分析工具中使用。
- jinfo
查看JVM的系统属性,可以动态设置一些系统属性。可适用于脚本。
- jstack
转储Java进程的栈信息。可适用于脚本。
- jstat
提供GC和类装载活动的信息。可适用于脚本。
- jvisualvm
监视JVM的GUI工具,可用来剖析运行的应用,分析JVM堆转储(事后活动,jvisualvm也可以实时抓取程序的堆转储)。
这些工具可广泛用于以下领域:
- 基本的VM信息
- 线程信息
- 类信息
- 实时GC分析
- 堆转储的事后处理
- JVM的性能分析
工具和适用领域并非一一对应的,许多工具可用于多个领域。所以不是单个研究每个工具,而是着眼于Java重要的可观测领域,讨论这些工具如何提供这类信息。同时,我们还会讨论其他工具(有些是开源,有些是商业),虽然提供的基本功能相同,但是相比基本的JDK工具具有一定的优势。
基本的VM信息
JVM工具可以提供JVM进程的基本运行信息:它运行多久了,使用哪些JVM标志,以及JVM的系统属性,等等。
运行时间
此命令可以查看JVM运行的时长:
% jcmd process_id VM.uptime
系统属性
以下命令可以显示System.getProperties()的各个条目。
% jcmd process_id VM.systen_properties
或者
% jinfo -sysprops process_id
这包括通过命令行-D标志设置的所有属性,应用动态添加的所有属性和JVM的默认属性。
JVM版本
用以下方式获取JVM版本:
% jcmd process_id VM.version
JVM命令行
jconsole的“VM摘要”页可以显示程序所用的命令行,或者用jcmd显示:% jcmd process_id VM.command_line
JVM调优标志
可用以下方式获得对应用生效的JVM调优标志:
% jcmd process_id VM.flags [-all]
调优标志
JVM可以设置许多调优标志,上面最后两个jcmd示例对于获取这类信息很有用。command_line显示直接在命令行指定的标志。flags显示命令行设置的标志,以及JVM直接设置的标志(因为它们的值是通过自动优化决定的)。该命令加上all时,可以列出JVM内部所有的标志。
诊断性能问题时,找出哪些标志起作用是很常见的事。JVM运行时,可以用jcmd做到这一点。如果想找出特定JVM的平台特定的默认值是什么,那么在命令行上添加-XX:+Printflagsfinal会很有用。
想知道特定平台所设置的标志是什么,可以执行以下命令:
% java other_options -XX:+PrintFlagsFinal -version
……几百行输出,包括……
uintx InitialHeapSize : = 4169431040 {product}
intx InlineSmallCode = 2000 {pd product}
应该在命令行包括所有标志,因为有些标志会影响其他标志,特别是GC相关的标志。这个命令会打印JVM标志及其取值的完整列表(结果和jcnd结合VM.flags -all打印的相同)。这些命令的标志数据以上述两种方式之一显示。输出第1行中的冒号表示标志使用的是非默认值。发生这种情况,可能是以下原因导致。
- 标志值直接在命令行指定。
- 其他标志间接改变了该标志的值。
- JVM自动优化计算出来的默认值。
第2行(没有冒号)表示,值是这个JVM版本的默认值。某些标志的默认值在不同平台上可能会不相同,输出的最右列会指示。product表示在所有平台上的默认设置都是一致的。pd product表示标志的默认值是独立于平台的。
另一种查看运行中的应用的此类信息的工具,叫作jinfo。jinfo的好处在于,它允许程序在执行时更改某个标志的值。
以下是如何获取进程中所有标志的值:
% jinfo -flags process_id
jinfo带有-flags时可以提供所有标志的信息,否则只打印命令行所指定的标志。这两种
数据都不像-XX:+Printflagsfinal那样易读,但jinfo有其他值得注意的特性。
jinfo可以检查单个标志的值:
% jinfo -flag PrintGCDetails process_id
-XX:+PrintGCDetails
虽然jinfo本身不会显示是否manageable,但manageable(如Printflagsfinal输出中所标识的)的标志可以通过jinfo开启或关闭:
% jinfo -flag -PrintGCDetails process_id # turns off PrintGCDetails
% jinfo -flag PrintGCDetails process_id
-XX:-PrintGCDetails
需要当心的是,jinfo可以更改任意标志的值,但并不意味着JVM会响应更改。比如说,大多数影响GC算法行为的标志都在启动时使用,以决定垃圾收集器的行为方式。之后通过jinfo更改标志值,并不会导致JVM改变它的行为。它会以初始时的算法继续执行。所以这个技术只会对那些在Printflagsfinal输出中标记为manageable的标志有效。
快速小结
- jcmd可用来查找运行中的应用所在JVM的基本信息——包括所有调优标志的值。
- 2.命令行上添加
-XX:+Printflagsfinal可输出标志的默认值。这在查看特定平台自动优化所判定的默认值时很有用。
3.info在检查(某些情况下可以更改)单个标志时很有用。