九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
文章目录
- 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
- 1. RDB 概述
- 2. RDB 持久化执行流程
- 3. RDB 的详细配置
- 4. RDB 备份&恢复
- 5. RDB 持久化小结(优势 和 劣势)
- 6. 最后:
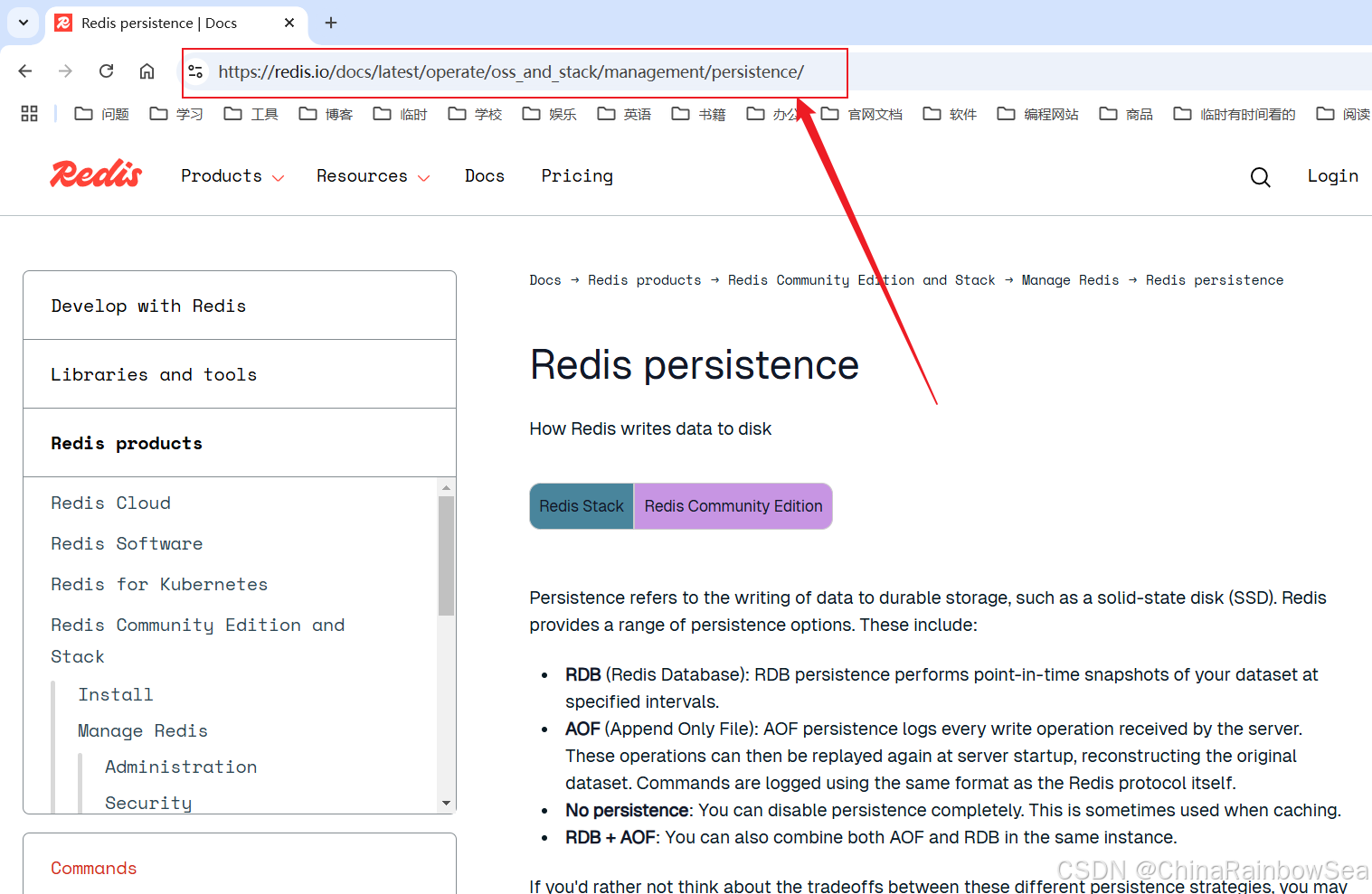
Redis 持久化-RDB:官网文档地址: https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
Redis 关于持久化方案:有两种:
- RDB(Redis DataBase)
- AOF(Append Of File)
这里我们主要介绍 RDB 持久化方案,AOF 持久化方案,在下一篇文章当中。
1. RDB 概述
RDB 是什么 ?:
在指定的时间间隔内将内存当中的数据集快照写入到磁盘当中,也就是 Snapshot 快照,恢复时将快照文件当中的内容读取到内存 当中。
2. RDB 持久化执行流程
RDB 及其执行流程:

对上图的解读:
具体流程如下:
- Redis 客户端执行 bgsave 命令或者自动触发 bgsave 命令。
- 主进程判断当前是否已经存在正在执行的子进程 ,如果存在,那么主进程直接返回。
- 如果不存在,正在执行的子进程 ,那么就 fork 一个新的子进程进行持久化数据,fork 过程是阻塞的,fork 操作完成后主进程即可执行其它操作。
- 子进程先将数据写入到 临时的
rdb文件中 ,待快照数据写入完成后,再原子替换旧的rdb文件。- 同时发送信号给主进程,通知主进程
rdb持久化完成,主进程更新相关的统计信息。
小结:
- 整个过程中,主进程是不进行任何 IO 操作的,这就确保了极高的性能。
- 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加的高效。
- RDB的缺点是最后一次持久化的数据可能丢失。
如果你是正常关闭 Redis ,仍然会进行持久化,不会造成数据丢失。
如果是 Redis 异常终止/宕机 ,就可能造成数据丢失。
后面在讲解快照配置的时候,进行说明。
Fork&Copy-On-Write:
-
Fork 的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量,环境变量,程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
-
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后都会 exec 系统调用,出于效率考虑,Linux 中引入了 “写时复制技术 即:copy-on-write” ,有兴趣的可以移步至🌟🌟🌟 https://blog.csdn.net/Code_beeps/article/details/92838520 一位网友的解读。
-
一般情况父进程和子进程会共用一段物理内存,只有进程空间的各段的内容要发送变化时,才会将父进程的内容复制一份给子进程。
3. RDB 的详细配置
- 默认快照配置:
Redis 当中的快照的文件是名为 dump.rdb 文件,这是默认的。
在 /etc/redis.conf 中配置文件名称当中,存在这个 dump.rdb 的配置。

如何配置
默认为 Redis 启动时命令行所在的目录下:
意思就是:默认会将 “dump.rdb” 快照文件存储到 Redis 启动时命令行所在的目录下

重点: 进入到/usr/local/bin 目录下, 启动 Redis, 这个那么这里的 ./ 所指的路径就是 /usr/local/bin , 如果你在 /root/ 目录下启动 Redis , 那么这里 ./ 所指的就是 /root/ 下了路径 , 这点请大家注意。

那么这样的默认配置就存在一个问题,那就是,如果我们每次去到不同的目录下启动 redis 的化,那么这个
dump.rdb(快照存储我们信息/数据的文件) 就会存储到不同的目录下,这样就导致了,如果该目录下没有我们之前执行存储的数据的dump.rdb文件的话,我们Redis 就无法读取到该存有我们之前dump.rdb数据的文件,也就无法恢复我们之前存储操作的数据了。演示:
我们创建两个目录:分别是: test01,和 test02 在 test01 目录下执行 set k1 "test01" 同时查看该目录下是否生成 dump.rdb(快照文件) 在 test02 目录下执行 set k2 "test02" 同时查看该目录下是否生成 dump.rdb(快照文件)[root@localhost home]# mkdir test01 # 创建目录

[root@localhost test01]# redis-cli 127.0.0.1:6379> keys * (error) NOAUTH Authentication required. 127.0.0.1:6379> auth rainbowsea OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set k1 "test01" OK 127.0.0.1:6379> keys * 1) "k1"


同理执行:test02


怎么解决这个,Redis 在不同的目录下,导致数据存储快照不同,数据没有跟上?
我们可以自定义配置好这个 dump.rdb 文件的存放路径,不是默认的dir./(根据启动Redis目录不同而变化) ,而是一直配置在一个固定的路径下。就可以解决这个问题了。
这里我们将其配置到 /root/ 目录下,这样我们每次生成的 dump.rdb 文件就一直是在同一个路径的目录下了
dir /root/

注意:需要关闭 Redis 服务,重新启动 Redis 服务,配置才会生效 。
[root@localhost test02]# redis-server /etc/redis.conf [root@localhost test02]# redis-cli


- save 和 bgsave
127.0.0.1:6379> save
127.0.0.1:6379> bgsave

默认的快照配置: 如图:同样是在 `/etc/redis.conf文件当中配置的。


注意理解这个时间段的概念.:

如果我们没有开启 save 的注释 那么在退出,Redis 时 也会进行备份 更新 dump.rdb 文件的。
- save : save 时只管保存,其它不管,全部阻塞。手动保存,不建议。
- bgsave: Redis 会在后台异步进行快照操作,快照同时还可以响应客户端请求。
- 可以通过 lastave 命令获取最后一次成功执行快照的时间(unix 时间戳),可以使用工具转换。https://tool.lu/timestamp/
- flushall
- 执行 flushall 命令,也会产生 dump.rdb 文件,数据为空。
Redis Flushall命令用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key )


- Save
格式:save 秒钟 写操作次数, 如图


RDB 是整个内存的压缩过的 Snapshot,RDB 的数据结构,可以配置复合的快照触发条件 。
禁用:给 save 传空字符串,可以看文档:
- stop-writes-on-bgsave-error

意思是:当 Redis 无法写入磁盘的话(比如磁盘满了), 直接关掉 Redis 的写操作。推荐 yes
- rdbcompression

该配置的意思是:
- 对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis 会采用 LZF 算法进行压缩。
- 如果你不想消耗 CPU 来进行压缩的话,可以设置为关闭此功能,默认 yes。
- rdbchecksum

该配置的意思是:
- 在存储快照后,还可以让 redis 使用 CRC64算法来进行数据校验,保证文件是完整的。
- 但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能,推荐 yes 打开。
-
动态停止 RDB:
-
动态停止RDB:
redis-cli config set save "",就是给 save 属性赋值为""空字符串,表示禁用保护策略。这里使用命令是让 客户端在此刻,启动的客户端停止 RDB,一旦退出了该客户端就,该配置就失效了。RDB 持久化策略又启动了。
示例演示:
需求: 如果 Redis 的 key 在 30 秒内, 有 5 个 key 变化, 就自动进行 RDB 备份.

save 30 5





4. RDB 备份&恢复
Redis 可以充当缓存,对项目进行优化,因此重要/敏感的数据建议在 MySQL要保存一份。
从设计层面来说,Redis 的内存数据,都是可以重新获取的(可能来自程序,也可能来自MySQL)
因此我们这里说的备份&恢复 :主要是给大家说明一下 Redis 启动时,初始化数据是从 dump.rdb 来的 整个机制。
演示:
这里我们演示的是:
将我们已经的
dump.rdb备份文件复制拷贝(备份)一份,复制后之后,再将原来的dump.rdb文件删除了(模拟文件损坏了,或者是执行 flushall 删除库)。再将我们拷贝备份的 dum.rdb 文件,复制过去,然后重启 redis 读取 dump.rdb 备份文件当中的数据,进行一个数据上的恢复。
config get dir 查询 rdb 文件的目录
127.0.0.1:6379> config get dir

将 dump.rdb 进行备份 如果有必要可以写 shell 脚本来定时备份 [参考韩顺平老师 Linux 课程定时
,备份 Mysql 数据库视频地址 https://www.bilibili.com/video/BV1Sv411r7vd?p=105 ] 。
[root@localhost ~]# cp /root/dump.rdb /root/dump.rdb.bak



127.0.0.1:6379> flushall


注意:这里得关闭一下服务器

[root@localhost ~]# rm /root/dump.rdb # 删除文件夹



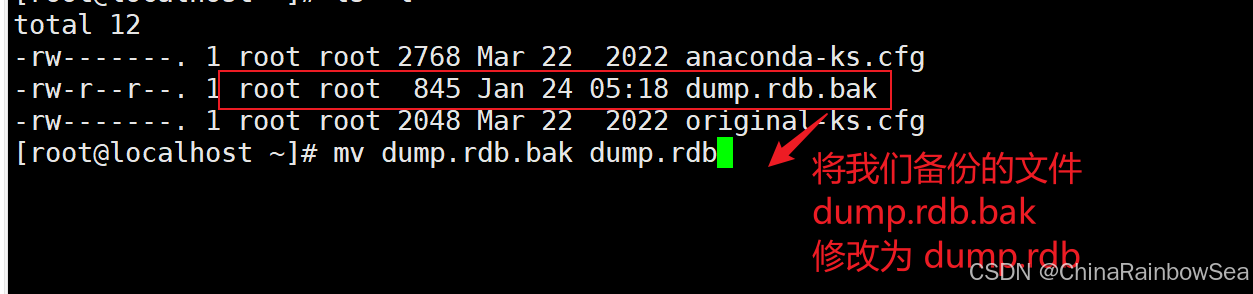
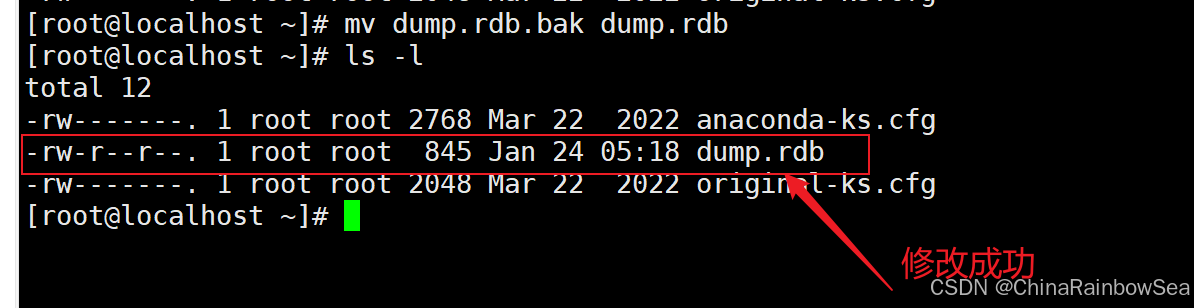
关闭 Redis 服务器,重新启动 Redis 服务器,让它读取到我们配置的dump.rdb 备份文件,恢复我们的数据信息。

5. RDB 持久化小结(优势 和 劣势)
优势:
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快

劣势:
- 虽然 Redis 在 fork 时使用了写时拷贝技术(Cop-On-Write) ,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果 Redis 意外 down 掉 的话(如果正常关闭 Redis仍然会进行 RDB 备份,不会丢失数据),就会丢失最后一次快照后的所有修改。
6. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”