1. Nacos 的介绍和安装
与 Eureka 一样,Nacos 也提供服务注册和服务发现的功能,Nacos 还支持更多元数据的管理, 同时具备配置管理功能,功能更丰富。
1.1. windows 下的安装和启动方式
下载地址:Release 2.2.3 (May 25th, 2023) · alibaba/nacos · GitHub
下载之后进行解压,bin 目录下面是启动和关闭脚本

由于 Nacos 默认的启动方式是集群,所以启动前需要修改配置为单机模式
使用记事本打开 startup.cmd,大概在 26 行左右,把 set MODE="cluster" 改为 set MODE="standalone"
保存之后再双击打开 startup.cmd,运行成功之后可以看出 Nacos 的端口号为 8848

在浏览器中输入 http://127.0.0.1:8848/nacos 就能访问了

在 windows 系统下,如果端口号冲突,可以关闭当前占用 8848 端口号下的进程,也可以修改 conf 目录下的 application.properties 文件中的端口号配置

1.2. Linux 系统下的安装和启动方式
在 Linux 系统中也是同样的操作,把刚刚下载的安装包解压之后也是相同的目录

此时就需要启动 startup.sh 了,以 Ubuntu 系统为例,同样是以单机模式启动,启动 Nacos 服务的命令为:
bash startup.sh -m standalone
如果端口号冲突同样也是两种解决方案
在访问之前还需要确保开放云服务器的端口号,除了 8848 端口号,还需要开启 9848 端口号

2. Nacos 的使用
2.1. 配置导入
和 Eureka 一样,需要在父项目中的 dependencyManagement 下导入下面的依赖,版本可以统一管理

spring-cloud-alibaba 的版本和 spring boot 也是对应的,具体可见官方文档:
版本发布说明-阿里云Spring Cloud Alibaba官网
<properties><spring-cloud-alibaba.version>2022.0.0.0-RC2</spring-cloud-alibaba.version>
</properties>
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope>
</dependency>接下来子项目也需要引入 nacos 的依赖,order-service 在这里作为客户端需要引入发现服务的依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>负载均衡的依赖也需要添加:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-loadbalancer</artifactId>
</dependency>接下来,在官方文档中也给出 Nacos Config 地址的配置格式

spring:cloud:nacos:discovery:serverAddr: 127.0.0.1:8848应用名称也需要配置一下
spring:application:name: order-serviceproduct-service 也做相同的配置
之后就可以按照和 Eureka 一样的方式进行远程调用了:
public OrderInfo selectOrderById(Integer orderId){OrderInfo orderInfo = orderMapper.selectOrderById(orderId);String url = "http://product-service/product/" + orderInfo.getProductId();ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;
}2.2. 服务下线
如果某个服务出现了问题,为了减少损失,需要把这个服务下线,解决好了之后再进行上线

例如,把端口号为 9091 的服务下线之后,该服务就不会收到请求了

同样的,再点击上线就又可以接收请求了
2.3. 负载均衡
点击编辑就可以修改该服务的权重


但是修改之后再次请求发现,目前 9090 端口和其它端口接收到的请求还是一样的

这是因为 Spring Cloud LoadBalance 组件自身有负载均衡配置的方式,所以不支持 Nacos 的权重属性配置,需要开启 Nacos 的负载均衡策略,让权重生效
#开启nacos负载均衡策略
spring:cloud:loadbalancer:nacos:enabled: true此时 order-service 作为客户端发起请求,所以需要配置在 order-service 下,之后重启服务,再重新发起请求,发现此时的权重配置已经生效了

可能出现的问题:
在修改权重的时候可能会出现下面的报错

是因为 Nacos 采用 raft 算法来计算 Leader,并且会记录前一次启动的集群地址,当服务器 IP 改变时会导致 raft 记录的集群地址失效,导致选 Leader 出现问题(网络环境发生变化时,IP 地址也会发生变化)
解决办法就是删除 Nacos 根目录下 data 文件夹下的 protocol 文件夹
2.4. 配置同集群优先访问
微服务访问时,应该同一个集群优先访问的,例如同一个机房的电脑是在同一个局域网下的,访问速度会快一点

配置格式如下:
spring:cloud:nacos:discovery:server-addr: cluster-name: BJ #集群名称: 上海集群把 order-service 和 端口号为 9090 的 product-service 的集群都设置为北京:

9091 和 9092 服务集群的配置方式:

之后再重启服务,集群就配置成功了

此时再发起请求,由于 order-service 的集群为 BJ,那么会优先访问集群为 BJ 的 product-service 了:

如果把 9090 的服务下线,那么就会访问 SH 的集群了
2.5. 健康检查
Nacos 提供了两种健康检查机制,一种是客户端主动上报,另一种是服务端反向探测
- 客户端主动上报:客户端会以心跳上报的形式向 Nacos 告知自身健康状态。若 Nacos 在一定时间内未收到客户端的心跳报告,便会将该实例置为不健康状态。若继续在超过另一段更长的时间后仍未收到报告,就会将实例从注册列表中删除,以此来确保注册列表中的实例都是活跃可用的。
- 服务端反向探测:Nacos 服务器主动对客户端进行健康状态探测,若探测失败,实例会被标记为不健康。这样在进行服务调用时,负载均衡器等组件就不会将请求分发到这些不健康的实例上,以保障服务质量,但一般不会立即删除该实例,以便在实例恢复健康后可继续使用。

Nacos 的服务实例(注册的节点)又分为临时实例和非临时实例
临时实例:如果实例宕机超过一定时间,会从服务列表去除
非临时实例:如果实例宕机,不会从服务列表去除
Nacos 对临时实例采取的是客户端主动上报的机制,对于非临时实例,采取服务器端反向探测机制,之前创建的服务都是非临时的,可以通过下面的配置来设置非临时实例
spring:cloud:nacos:discovery:ephemeral: false # 设置为⾮临时实例把 order-service 设置为非临时实例之后,Nacos 检测到 order-service 状态异常,就会把它的健康状态设置为 false

在设置实例类型的时候可能会出现报错:

这是因为 Nacos 会记录每一个服务实例的 IP 和端口号,当发现 IP 和端口号都没有发生变化时,Nacos 不允许一个服务实例类型发生变化
解决办法就是先停止 Nacos 的服务,然后删除 Nacos 目录下 /data/protocol/raft 中的信息,再重启服务
2.6. 环境隔离
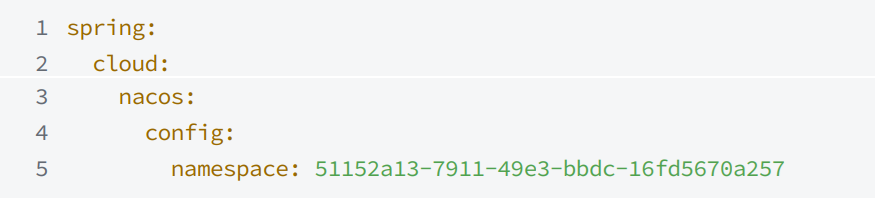
Nacos 提供了 namespace(命名空间)来实现环境的隔离,不同的命名空间的服务不可见,通过以下方式在 Nacos 上创建命名空间


spring:cloud:nacos:discovery:namespace: 51152a13-7911-49e3-bbdc-16fd5670a257通过命名空间 ID 来配置属于哪个环境


此时只有 order-service 在 dev 环境下,所以再去访问 product-service 是会报错的,处于同一个环境下才能访问到
3. Nacos 配置中心
除了注册中心之外,Nacos 还是一个配置中心,具备配置管理的功能,当前项目的配置都在代码中,就会存在一些问题:
- 配置文件修改时,服务需要重新部署,在微服务架构中,一个服务有很多个实例,一个一个的部署比较麻烦,并且也容易出错
- 多人开发时,配置文件可能需要经常修改,使用同一个配置文件容易出现冲突
配置中心就是对这些配置项进行统一管理,通过配置中心,可以集中查看,修改和删除配置,不用再逐个修改配置文件了
先分别创建 public 和 dev 环境下的配置


之后在 product-service 导入依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- SpringCloud 2020.*之后版本需要引⼊bootstrap-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>微服务启动前需要获取 Nacos 中的配置,并与 application.tml 配置合并,需要使用 bootstrap.properties 或者 bootstrap.yml 配置文件来配置 Nacos Server 地址
spring:application:name: product-servicecloud:nacos:config:server-addr: 127.0.0.1:8848接下来尝试获取 Nacos 中的配置内容
@RestController
public class NacosController {@Value("${nacos.config}")private String nacosConfig;@RequestMapping("/getConfig")public String getConfig() {return "从nacos获取配置项nacos.config: " + nacosConfig;}
}${nacos.config} 要和配置中的配置项保持一致

不过此时如果修改 Nacos 配置中心的配置,再次获取还是修改前的,如果要实现实时更新还需要加上 @RefreshScope注解

Nacos 配置中心的命名空间和注册中心的命名空间是分别设置的,默认都是 public,所以 bootstrap.yml 中也需要配置一下命名空间
‘
配置之后再访问就是对应配置好的命名空间的配置:

接下来看关于 Data ID 的介绍

在开始之前配置的是 product-service,完整的格式应该是:
![]()

刚开始添加配置时就选择的配置文件类型为 properties,所以这里可以不用再配置了,接下来把 active 配置为 dev

在日志中可以看出是监听了三个类型的文件配置,如果这三个类型配置都配置上的话它们的一个优先级如下;


4. 部署到云服务器
这次部署和之前有些不一样,由于 product-service 中多了一个 bootstrap.yml 配置文件,其中已经配置好了 profiles.active,所以可以直接改成 @profile.name@,然后只需要分别配置 dev 和 prod 下的配置


除此之外还需要加上以下配置,使用过滤功能将环境相关的信息注入到配置文件中

5. Nacos 和 Eureka 的区别
共同点:都支持服务注册和服务拉取
区别:
功能上:Nacos 提供了更丰富的功能,除了服务发现和注册之外,还包括配置管理(配置中心)、流量管理、DNS服务等。这使得Nacos可以作为微服务架构中的一个更全面的解决方案。Eureka 主要专注于服务发现和注册,没有Nacos那么丰富的功能。
CAP 理论:Eureka 遵循 AP(可用性-分区容错性)原则,Nacos 可以灵活地在 AP 和 CP(一致性-分区容错性)模式之间切换,默认情况下是 AP 模式,也可以根据需要配置为 CP 模式。
服务发现:Eureka 采用基于拉(Pull)模式的服务发现机制。Eureka客户端(Eureka Client)会定期从Eureka服务器(Eureka Server)拉取服务信息,并且会缓存这些信息,默认每30秒更新一次。Nacos 采用基于推(Push)模式的服务发现机制。当服务列表发生变化时,Nacos服务器会实时推送这些变化给所有订阅了该服务的客户端,同时服务端和客户端之间会保持心跳连接,以确保服务信息的实时性和准确性。