目录
简介
左值和右值
左值
右值
右值引用
生命周期
引用折叠
实际应用
移动语义
移动构造函数
移动赋值运算符
完美转发
简介
之前我们曾学习过引用叫左值引用,但那是C++98的,在C++11中新增了一种引用叫右值引用。右值引用主要用于支持移动语义和完美转发。从而可以更高效地管理资源,减少不必要的复制操作。
左值和右值
左值
左值是指可以取地址的表达式。它通常出现在赋值操作符左侧。
下面是它的几个特性:
- 可寻址性:左值在内存中有明确的地址,即可以取地址。
- 持久性:左值通常指向内存中的持久对象,这些对象在表达式结束后仍然存在。
- 可变性:左值可以被重新赋值,即可以改变其存储的值。
例:
int a = 0;
int* p = new int[10];上面的a就是左值 ,因为它有持久的内存地址,并且可以被后续的代码访问和修改。*p同理。
右值
右值是指不可以取地址的临时对象,它通常出现在表达式的结果。
下面是它的几个特性:
- 不可寻址性:右值通常没有持久的内存地址,即不可以取地址。
- 短暂性:右值通常表示的是一些临时的值,这些值在表达式结束后就会被销毁。
例:
int a = 0;
int b = 1;
int c = a + b;上面的0,1就是右值 ,因为它是一个字面常量,没有持久的内存地址。a + b也是右值,因为它是表达式的结果,没有持久的内存地址。
常见的右值有:
- 字面常量,如整数常量(如
42)、字符常量('a')等。- 无引用的函数返回值。
- 表达式的结果,如算术表达式(如1+1)、逻辑表达式(如a||b)、关系表达式(如a>b)。
想区分它们也很简单只要能取地址就是左值,不能取地址就是右值。
右值引用
右值引用的表示如下:
int&& a = 1;右值引用和左值引用没有什么区别都是起别名,从汇编层来看它们都是用指针来实现的。只不过一个是给右值起别名一个给左值。
虽然说右值引用不能引用左值,但是可以通过move函数来实现。该函数可以让左值变右值,本质上是通过强制类型转换(使用该函数要小心原对象会变成不确定状态,原因一会儿在解答)。
int a = 1;
int&& ra = move(a);同样的左值引用也可以引用右值在前面加const,即const左值引用。当const左值引用绑定右值时,编译器通常会创建一个临时对象,并将右值的内容复制到该临时对象中。又因为临时对象有只读性,被const修饰后的对象也只具有只读性。这是权限的平移,所以可以这样是OK的。
const int& a = 1;注意:一个右值被右值引用绑定后,右值引用变量表达式的属性是左值!就像上面的ra虽然它是一个右值引用,但它自身作为一个变量是左值。
生命周期
大家可能发现了当一个临时的或匿名的对象被右值引用后,它好像不仅仅可以出现在该行,其它行好像也可以出现。事实上当一个对象被右值引用后它的生命周期就被延长了。不仅仅是右值引用,const左值引用的对象也是可以实现的只不过内容无法修改。例如:
int main()
{string&& str1 = string("ha");str1 += "ha";cout << "str1: " << str1 << endl;const string& str2 = string("xi");cout << "str2: " << str2 << endl;return 0;
}
引用折叠
它的规则是:右值引用的右值引用折叠成右值引用,其他组合均折叠成左值引用。简单来说如果是两个都是右值引用那就折叠成右值引用,其他就都是左值引用。这主要是为了实现万能引用。示例:
template<class T>
void Test(T&& x)
{//...
}注意上面的参数虽然是通过右值引用传递的,因为它是一个模板所以这是一个万能引用。不太懂的可以先往下看。当用下面代码调用时:
Test(10);
由于Test函数模板的参数是T&&,这里发生了模板参数推导即转发引用。简单来说当传递一个左值给接受T&&参数的函数模板时,编译器会推导T为左值引用类型;右值即非引用类型。
在这种情况下,编译器会T推导为int(因为10是int类型),并且由于10是右值,T&&在这里实际上变成了int&&,即一个对int类型的右值引用。这其实并没有用引用折叠。
用下面的代码调用时:
int a = 10;
Test(a);
调用 Test 函数并将a作为参数传递进去。由于传递的是左值, T会被推导为int&,这就变为了int& && 然后根据引用折叠规则最后就变为了int&,即一个对int类型的左值引用。
这样一份代码就可以实现左值引用和右值引用,是不是方便了不少。
实际应用
移动语义
移动语义指的是通过移动构造函数和移动赋值运算符,将资源的所有权从一个对象转移到另一个对象,即新对象直接管理原对象的内存资源,原对象仍然处于有效状态,但不再持有任何资源。它们的主要目的是优化资源管理和提升程序性能。
移动构造函数
可以简单认为移动构造函数的实现是通过下面的方式:
void swap(string& s)
{std::swap(_str, s._str);//首元素地址std::swap(_size, s._size);//字符串长度std::swap(_capacity, s._capacity);//容量
}
// 移动构造
string(string&& rs)
{swap(rs);
}rs是右值引用但它的属性是左值,所以在swap()里用的是左值引用。
示例:
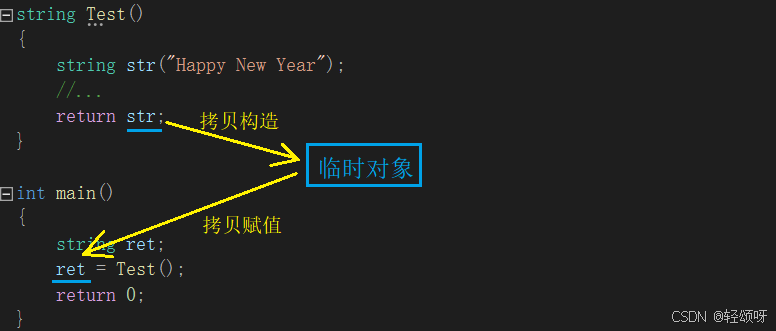
string Test()
{string str("Happy New Year");//...return str;
}int main()
{string ret = Test();return 0;
}不需要关心上面的函数是用来做什么的,这里我就只拿关键的部分。之前要想把str的值传给ret就要先创建一个临时对象,然后把str里的值拷贝构造给临时对象,然后临时对象在拷贝构造给ret。

使用两次拷贝构造这代价可不小,要是使用移动语义的话可就不一样了。移动语义相当于“掠夺”并不进行拷贝,这代价就很小了。

移动赋值运算符
它的简单实现和移动构造函数可以说是一样的。
// 移动赋值
string& operator=(string&& s)
{swap(s);return *this;
}示例:
string Test()
{string str("Happy New Year");//...return str;
}int main()
{string ret;ret = Test();return 0;
}之前要想把str的值传给ret就要先创建一个临时对象,然后把str里的值拷贝构造给临时对象,然后临时对象在拷贝赋值给ret。
当有了移动语义后就只是进行简单交换。

上面我所介绍的str值传给ret的过程,是编译器没有进行任何优化。我在这里就不介绍编译器具体怎么优化它们了,大家感兴趣可以自己上网查查。
现在我解答一下为什么使用move()后,原对象通常处于不确定状态。这是因为当move()把对象转换为右值后,会自动调用移动语义而造成的。例如:
int main()
{string s("haha");cout << "s:" << s << endl;string rs = move(s);cout << "s:" << s << endl;return 0;
}
完美转发
完美转发在C++编程中具有重要意义,它提高了代码的复用性、性能和可维护性。先看如下代码:
void Fun(int&& x)
{cout << "右值引用" << endl;
}void Fun(int& x)
{cout << "左值引用" << endl;
}template<class T>
void Test(T&& x)
{Fun(x);
}int main()
{int a = 1;Test(a);Test(1);return 0;
}这是运行结果:

为什么第二个也是左值引用?我在上面提到过右值引用它自身作为一个变量是左值,所以这里就是左值引用。但是这样会降低运行效率,其解决方案就是用完美转发forward函数,它能够保持参数的左、右值属性不变,并将其转发给目标函数。具体使用方法如下:
template<class T>
void Test(T&& x)
{Fun(forward<T>(x));
}修改后的结果:

完美转发forward本质是⼀个函数模板,他主要还是通过引用折叠的方式实现,上面示例中传递给Func的实参是右值,T被推导为int,没有折叠,forward内部 x 被强转为右值引用返回。当传递给Func的实参是左值,T被推导为int&,引用折叠为左值引用,forward内部 x 被强转为左值引用返回。






