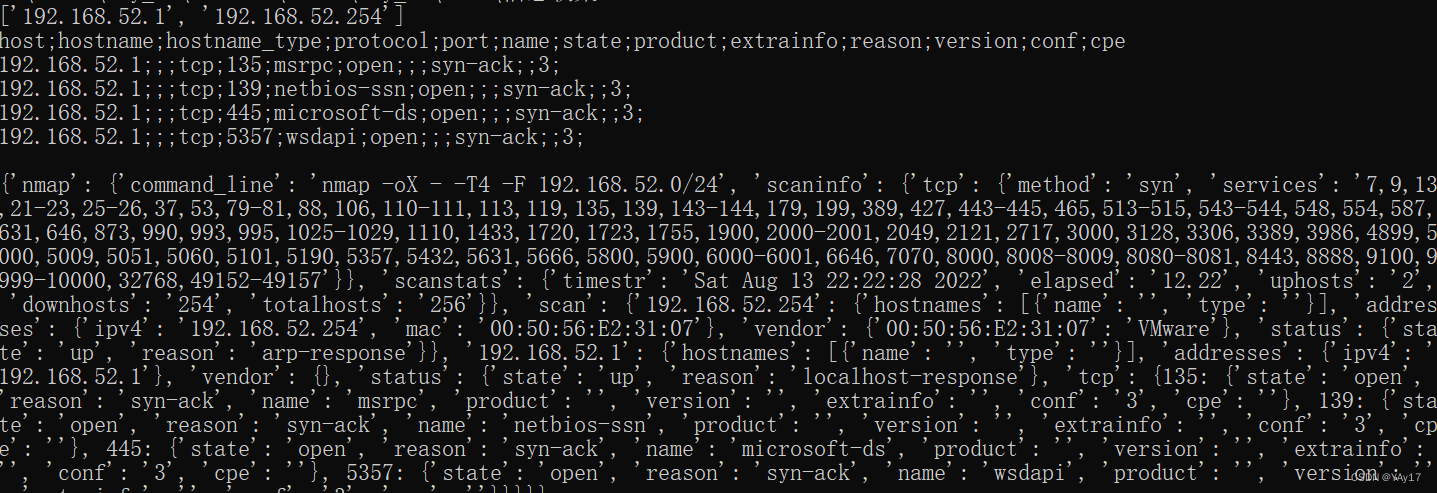
妙趣横生大数据 Day1
- [妙趣横生大数据 Juicy Big Data](https://datawhalechina.github.io/juicy-bigdata/#/?id=妙趣横生大数据-juicy-big-data)
- 一、大数据概述
- 大数据——第三次信息化浪潮
- 大数据概念
- 大数据应用
- 大数据关键技术
- 二、Hadoop
- 背景
- 介绍
- 特性
- 项目架构
- 实验
- 1. 准备工作
- 2. 安装jdk
- 3. 安装 openssh
- 4. 安装 hadoop
- 一、伪分布式安装
- 1. 修改`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`这4个文件
- 2. 格式化分布式文件系统
- 3. 测试
- 二、集群模式安装
- 1. 修改、`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`这4个文件
- 2. hadoop workers文件配置,编辑/etc/hosts文件,创建公钥并拷贝公钥
- 3. 格式化分布式文件系统
- 4. 测试
妙趣横生大数据 Juicy Big Data
Datawhale![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oJrzSM8H-1676443816587)(null)]](https://img-blog.csdnimg.cn/3aab0c279d0f4c5485ac0acd9527b378.png) 大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data Day1
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data Day1
一、大数据概述
大数据——第三次信息化浪潮
| 信息化浪潮 | 时间 | 标志 | 解决的问题 |
|---|---|---|---|
| 第一次浪潮 | 1980 | 个人计算机 | 信息处理 |
| 第二次浪潮 | 1995 | 互联网 | 信息传输 |
| 第三次浪潮 | 2010 | 物联网、云计算和大数据 | 信息爆炸 |
-
大数据的价值不在于数据本身,而在于数据所反映问题的真实性和科学性。
-
数据的采集存储只是大数据运用的第一阶段,更关键的是对数据的分析、利用,达到发现新知识、创造新价值的效果。
大数据概念
4V
- 数据量大(Volume) :物联网普及,传感器、摄像头产生的海量数据
- 数据类型多(Variety):生物大数据、交通大数据、医疗大数据、电信大数据、电力大数据、金融大数据等;结构化数据(10%)和非结构化数据(90%)
- 处理速度快(Velocity):为快速分析海量数据,新兴的大数据分析技术通常采用集群处理和独特的内部设计
- 价值密度低(Value):价值密度却远远低于传统关系数据库中已经有的数据
大数据应用
| 领域 | 大数据的应用 |
|---|---|
| 金融行业 | 大数据在高频交易、社交情绪分析和信贷风险分析三大金融创新领域发挥重要作用 |
| 互联网行业 | 借助于大数据技术,可以分析客户行为,进行商品推荐和有针对性的广告投放 |
| 餐饮行业 | 利用大数据实现餐饮O2O模式,彻底改变传统餐饮的经营方式 |
| 生物医学 | 大数据可以帮助我们实现流行病预测、智慧医疗、健康管理,同时还可以帮助我们解读DNA,了解更多的生命奥秘 |
| … | … |
大数据关键技术
-
大数据是数据和大数据技术这二者的综合。
-
大数据技术,是指伴随着大数据的采集、传输、处理和应用的相关技术,是一系列使用非传统的工具来对大量的结构化、半结构化和非结构化数据进行处理,从而获得分析和预测结果的一系列数据处理和分析技术。
-
从数据分析全流程的角度,大数据技术主要包括数据采集、数据存储和管理、数据处理与分析、数据安全和隐私保护等几个层面的内容。
二、Hadoop
背景
搜索:
-
Lucene:工具包,在目标系统中实现全文检索的功能
-
Nutch:建立在Lucene核心之上的网页搜索应用程序,开箱即用。站内检索–>全球网络搜索
搜索对象“体积”不断增大:
-
分布式文件存储系统(NDFS,Nutch Distributed File System):为了存储海量搜索数据而设计的专用文件系统,基于google的GFS
-
MapReduce编程模型:大规模数据集(大于1TB)的并行分析运算
介绍
Hadoop:HDFS(Hadoop Distributed File System) + MapReduce
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
特性
- 高可靠性、高容错性:冗余数据存储方式
- 高效性分布式存储和分布式处理两大核心技术,高效地处理PB级数据
- 高可扩展性
- 成本低:廉价的计算机集群
- 运行在Linux平台上
- 支持多种编程语言
项目架构
- Common:为其他子项目提供支持的常用工具,它主要包括FileSystem、RPC和串行化库
- Avro:用于数据库序列化的系统
- HDFS:分布式文件系统
- HBase:列式数据库,一般采用HDFS作为其底层数据存储
- Pig:一种数据流语言和运行环境
- Sqoop:改进数据的互操作性,主要用来在Hadoop和关系数据库之间交换数据
- Chukwa:数据收集系统
- Zookeeper:一个为分布式应用所涉及的开源协调服务
实验
1. 准备工作
# 创建容器
docker run --name=hadoop ubuntu /bin/bash
# 添加用户,赋予权限
useradd zym -m -d /home/zym -s /bin/bash
passwd zym
usermod -aG sudo zym
2. 安装jdk
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
sudo tar -xzvf /data/hadoop/jdk-8u131-linux-x64.tar.gz -C /opt

sudo mv /opt/jdk1.8.0_131/ /opt/java
sudo chown -R zym:zym /opt/java

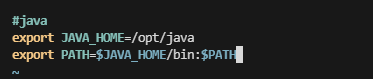
修改系统环境变量
sudo vim /etc/profile
# 1. 添加java环境变量
# 2. 激活使环境变量生效
source /etc/profile
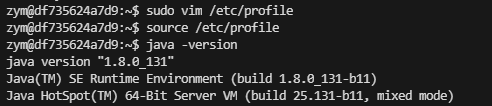
# 3. 查看版本
java -version
3. 安装 openssh
# 更新apt,并安装文本编辑器、SSH服务和screen服务
apt-get update && apt-get install -y vim openssh-server screen && rm -rf /var/lib/apt/lists/*
查看是否安装成功
service ssh start
# 设置 ssh 服务开机自启
echo 'service ssh start'>>~/.bashrc
SSH登录权限设置
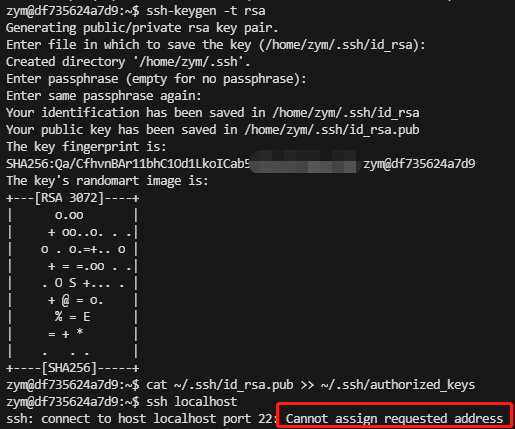
解决方法:将容器内22端口和宿主机内端口完成映射即可。
教你如何修改运行中的docker容器的端口映射的三种方式_docker修改端口映射_是阿俏同学吖的博客-CSDN博客
4. 安装 hadoop
hadoop国内镜像站点:Index of /apache/hadoop/common/hadoop-3.3.1 (tsinghua.edu.cn)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
sudo tar -xzvf hadoop-3.3.1.tar.gz -C /opt/
sudo mv /opt/hadoop-3.3.1/ /opt/hadoop
sudo chown -R zym:zym /opt/hadoop
sudo vim /etc/profile
1. 添加以下内容
#hadoop
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
2. 激活,查看版本
source /etc/profile
hadoop version
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cJZVaiCm-1676443808236)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230213161119633.png)]](https://img-blog.csdnimg.cn/780a0dbbddaf4644b58a2108be3eb800.png)
修改hadoop-env.sh文件配置
vim etc/hadoop/hadoop-env.sh
# 追加
export JAVA_HOME=/opt/java/
测试
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep input output 'dfs[a-z.]+'
cat output/*
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y1NtDreq-1676443808237)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230213161542965.png)]](https://img-blog.csdnimg.cn/8f988ecb597c4f498a83c29206c8b8a0.png)
一、伪分布式安装
1. 修改core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml这4个文件
详细见 [第二章:Hadoop (datawhalechina.github.io)](https://datawhalechina.github.io/juicy-bigdata/#/ch2 Hadoop?id=_2335-hadoop伪分布式安装)
2. 格式化分布式文件系统
hdfs namenode -format
/opt/hadoop/sbin/start-all.sh
3. 测试
输入jps命令可以查看Java进程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Ag6ejr3-1676443808237)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230213164451118.png)]](https://img-blog.csdnimg.cn/b135972ae0934ebeb000b6efc9e71f02.png)
执行wordcount程序, 测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6JwXlFUp-1676443808238)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230213164927253.png)]](https://img-blog.csdnimg.cn/7c73fcbfeefc42dabdbe39c6b3eb0ed8.png)
二、集群模式安装
此处我将实验一伪分布式安装的docker容器commit为了镜像,用来构建子节点。 还可以直接search有Hadoop的镜像,或者直接编写dockerfile Task01 详读第1、2章Hadoop内容 (plutos.org.cn)
1. 修改、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml这4个文件
详细见 [第二章:Hadoop (datawhalechina.github.io)](https://datawhalechina.github.io/juicy-bigdata/#/ch2 Hadoop?id=_2335-hadoop伪分布式安装)
2. hadoop workers文件配置,编辑/etc/hosts文件,创建公钥并拷贝公钥
# 1. 修改hadoop workers文件配置
vim /opt/hadoop/etc/hadoop/workers
# 2. 编辑/etc/hosts文件
sudo vim /etc/hosts
# 3. 创建公钥并拷贝公钥
ssh-keygen -t rsa
ssh-copy-id master
# 4. 修改文件权限
chmod 700 /home/zym/.ssh
chmod 700 /home/datawhale/.ssh/*
3. 格式化分布式文件系统
hdfs namenode -format
/opt/hadoop/sbin/start-all.sh
4. 测试
输入jps命令可以查看主节点和两个从节点的Java进程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tqLhDOq2-1676443808238)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230215135803073.png)]](https://img-blog.csdnimg.cn/f413c1ee7cb1437e88f8b05166d390d7.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1urxGPFP-1676443808239)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230215135829861.png)]](https://img-blog.csdnimg.cn/06f13a78110641e1957485ab81d783d0.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IG5aAGlr-1676443808239)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230215135849535.png)]](https://img-blog.csdnimg.cn/7aba121599f34652af43848324d46838.png)
执行wordcount程序, 测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ciSn2epR-1676443808239)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230215140200578.png)]](https://img-blog.csdnimg.cn/2b9f486d7a184b94ab628feddd953e79.png)
遇到的问题汇总:
-
Docker内22端口无法访问:
解决方法:将容器内22端口和宿主机内端口完成映射即可。
教你如何修改运行中的docker容器的端口映射的三种方式_docker修改端口映射_是阿俏同学吖的博客-CSDN博客
-
安装 hadoop 太慢
hadoop国内镜像站点:Index of /apache/hadoop/common/hadoop-3.3.1 (tsinghua.edu.cn)
-
DataNode 不显示
Hadoop中DataNode没有启动log目录:/opt/hadoop/logs/hadoop-zym-datanode-df735624a7d9.log
VERSION参考查询目录:/tmp/hadoop-datawhale/dfs/data/current/VERSION
Datawhale大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data