基于q_learning的flappy bird AI
思路来自于这篇文章:机器学习玩转Flappy Bird全书:六大“流派”从原理到代码
有两种思路,一种是单步更新q values,一种是全局更新q values。单步更新就是最基础的q learning算法,在agent每产生一个action之后,根据state、action以及next state更新。全局更新是Flappy Bird Bot using Reinforcement Learning in Python这个作者的想法。
我用python实现了单步更新,但是在训练次数达到几百上千次后,发散了。
全局更新基本上属于将Flappy Bird Bot using Reinforcement Learning in Python的python代码用pandas重写了一下。区别之处可能就在于我没有先去生成一个全零的q矩阵。而是在每次碰到新的状态后再写入q矩阵中。最后的状态数量更少,也就是说明初始化的q阵中存在一些永远也用不上的状态。
作者的代码我跑出来的结果:

我的代码在 10×10 10 × 10 的网格下的结果:

在 5×5 5 × 5 的网格下的结果:

收敛速度变慢的情况下没有取得更好的成绩,可能是参数选取不当。以后有时间再调整参数跑一次。
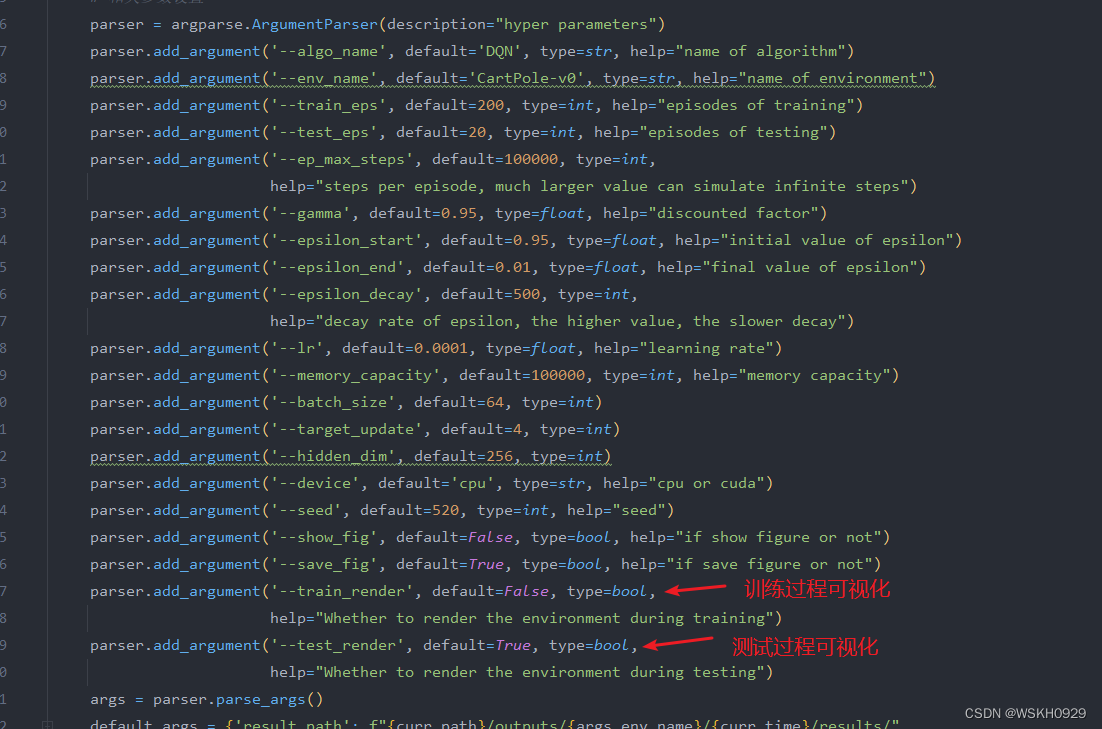
算法的代码如下:
# coding: utf-8
import numpy as np
import pandas as pdclass Bot(object):def __init__(self, rl=0.7, discount=1.0, greedy=1.0):self.rl = rl # alphaself.discount = discount # gammaself.greedy = greedy # epsilonself.reward = {'living': 1, 'dead': -1000}self.actions = ['0', '1'] # 1 代表clip, 0代表不动self.round = 0 # 玩的局数self.dump_num = 25 # 每dump_num局向csv存储一次q_valuesself.grid_size = 10 # 状态分割大小self.last_state = 'start_state' self.last_action = '0'self.track = [] # 鸟从开始到死亡的所有状态和行为self.q_values = Noneself.load_q_values()self.scores = Noneself.load_score()# choose actiondef choose_action(self, x_coord, y_coord, vel):state = self.add_state(x_coord, y_coord, vel)if np.random.uniform() > self.greedy:action = np.random.choice(self.actions)else:state_actions = self.q_values.loc[state, :]# state_actions = state_actions.reindex(np.random.permutation(state_actions.index)) # 如果权重一样,随机选择# 如果权重一样,选择不跳state_actions = state_actions.astype('int')# print(state_actions)action = state_actions.idxmax()self.track.append([self.last_state, self.last_action, state])self.last_state = stateself.last_action = actionreturn int(action)# 从csv文件中取出q表def load_q_values(self):self.q_values = pd.read_csv('qvalues.csv', index_col=0)# 将q表存入csv文件def dump_q_values(self):if self.round % self.dump_num == 0:self.q_values.to_csv('qvalues.csv')print('Q-values updated on local file.')# 添加状态def add_state(self, x_coord, y_coord, vel):state = self.dif2state(x_coord, y_coord, vel)if state not in self.q_values.index:self.q_values = self.q_values.append(pd.Series([0] * len(self.actions),index=self.q_values.columns,name=state))return state# 将x_coord, y_coord, vel转换成statedef dif2state(self, x_coord, y_coord, vel):if x_coord < 140:x_coord = int(x_coord) - int(x_coord) % self.grid_sizeelse:x_coord = int(x_coord) - int(x_coord) % 70if y_coord < 180:y_coord = int(y_coord) - int(y_coord) % self.grid_sizeelse:y_coord = int(y_coord) - int(y_coord) % 60return str(x_coord) + '_' + str(y_coord) + '_' + str(vel)def update_q_values(self, score):rev_track = list(reversed(self.track))high_dead_flag = True if int(rev_track[0][2].split('_')[1]) > 120 else Falseflag = 1for step in rev_track:if step[0] == 'start_state':continuestate = step[0]action = step[1]next_state = step[2]# print('state:{};action:{}'.format(state, action))# print(self.q_values.loc[state, str(action)])q_predict = self.q_values.loc[state, str(action)]# print(type(q_predict))if flag == 1 or flag == 2:q_target = self.reward['dead'] + self.discount * self.q_values.loc[next_state, :].max()elif high_dead_flag and int(action):q_target = self.reward['dead'] + self.discount * self.q_values.loc[next_state, :].max()high_dead_flag = Falseelse:q_target = self.reward['living'] + self.discount * self.q_values.loc[next_state, :].max()self.q_values.loc[state, action] = q_predict + self.rl * (q_target - q_predict)flag += 1self.round += 1# print('q-val: {}'.format(self.round))self.dump_q_values()self.add_score(score)self.track = []def add_score(self, score):self.scores.loc[self.scores.shape[0]] = scoreself.dump_score()def load_score(self):self.scores = pd.read_csv('scores.csv', index_col=0)# print(self.scores)def dump_score(self):# print('score: {}'.format(self.round))if self.round % self.dump_num == 0:self.scores.to_csv('scores.csv')print('scores updated on local file.')if __name__ == '__main__':bot = Bot()bot.dump_q_values()学习过程中碰到的好的博客:
A Painless Q-learning Tutorial (一个 Q-learning 算法的简明教程)