原文:https://zhuanlan.zhihu.com/p/4525257731
一、MHA结构优化(效果有损)
KV Cache的大小取决于模型大小(dim和layers) 和序列长度。为了尽可能的支持更大的模型、或者更长的序列,就需要对kv 进行压缩,下面列举一些方法对MHA的参数量进行压缩,从而对kv Cache进行压缩。

MQA(Multi-Query Attention)
多组Q,共享K、V,直接将KV Cache减少到了原来的1/h。
为了模型总参数量的不变,通常会相应地增大FFN/GLU的规模,这也能弥补一部分效果损失。
使用MQA的模型包括 PaLM、 Gemini 等。
示意图见下图右侧:

GQA(Grouped-Query Attention)
示意图见 上图 中。
是 MQA 和 MHA 的折中。
使用GQA的有LLaMA 2、Code LLaMA等。
MLA(Multi-head Latent Attention)
DeepSeek-V2 使用了低秩投影压缩 KV Cache 的大小,即 MLA 。
详见 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces[1]
示意图见下图右侧:

SWA(sliding window attention)
包括自己在内,每个位置只能往前看N个输入。实际上是一种sparse attention。
因此,kv cache和attention的计算量增大到一定程度后就不再增长(具体实现依靠Rolling Buffer Cache,实现一个滚动缓存区,将内存控制在一个稳定的数值)
因为有多层,其实能间接的融合 window_size 个输入以前的信息,而不仅仅是 window_size。(类似于多层的CNN网络,高层的卷积模板其实具有较大的感受野)
Mistral 7B就是使用SWA:Uses Sliding Window Attention (SWA) to handle longer sequences at smaller cost(在较少的显存代价上取得更长的序列长度)。Mistral 7B模型具有 4096 的 window_size:

线性attention
处理长序列时,具有线性的时间复杂度。
方案:softmax变成sim(q,k),用核函数,q和k变成phi(q)和phi(k),phi(x)=elu(x)+1,然后k和v先算。
备注:线性attention、包括下面的RWKV,并不是通用的做法,只是作为性能优化的一种方法,在这里引申一下。
RWKV:线性attention的一个变种。将历史信息压缩到了到一个向量中,类似RNN。

二、MHA工程优化(效果无损):
KV cache
因为Decoder only的特性,每次前向完,把 KV 都保留下来,用于之后计算。
#q、k、v 当前 timestep 的 query,key,value
# K_prev,V_prev 之前所有 timestep 的 key 和 value
for _ in range(time_step):...K = torch.cat([K_prev, k], dim=-2) #[b, h, n, d]V = torch.cat([V_prev, v], dim=-2) #[b, h, n, d]logits = torch.einsum("bhd,bhnd->bhn", q, K)weights = torch.softmax(logits/math.sqrt(d), dim=-1)outs = torch.einsum("bhn,bhnd->bhd", weights, V)...K_prev, V_prev = K, Vonline softmax
Safe softmax 和 online softmax:参考
陈star:Flash attention && flash decoding[2]

Flash attention
背景:
一旦模型规模很大长度很长时,QK根本就存不进缓存。将QK两个大的矩阵乘法,拆解为多次运算(平铺、重计算等),放入SRAM,减少HBM访问次数,利用SRAM的速度优势,显著提高计算速度。
比如 Llama 7B 模型,hidden size 是 4096,那么每个 timestep 需缓存参数量为 4096232=262144,假设半精度保存就是 512KB,1024 长度那就要 512MB. 而现在英伟达最好的卡 H100 的 SRAM 缓存大概是 50MB,而 A100 则是 40MB. 而 7B 模型都这样,175B 模型就更不用说了。
Flash Attention的主要改进点是(下面部分内容参考了 :极市开发者平台-计算机视觉算法开发落地平台-极市科技[3] 和 猛猿:图解大模型计算加速系列:Flash Attention V2,从原理到并行计算)[4]:
发现Transformer的计算瓶颈不在运算能力,而在读写速度上,因此着手降低了对显存数据的访问次数。
传统attention流程如下:
从显存中取QK计算->将结果S写回显存->从显存读S计算softmax->将结果P写回显存->从显存读取P和V进行计算->将结果O写回显存。
因此想办法进行分块计算,拆到足够小,就能全塞到L1缓存上(比如说A100的L1只有192KB)进行计算了,不需要将这些参数从显存反复的读入读出,只需要读L1缓存,就实现了加速。但是softmax是需要需要知道全局信息的,所以分块计算后,需要一些技巧对结果进行融合。
-
• FlashAttention是一种IO-aware算法,它通过tiling来减少对HBM的访存量,从而提高性能
-
• FlashAttention避免了从HBM读写一些中间结果,比如QK得到的相似度矩阵,以及基于相似度矩阵计算softmax得到的概率矩阵
FlashAttention对Transformer的加速原理简单,但因早期硬件限制未能及时出现,直到A100 GPU架构问世。
-
• 1.大幅度高速HBM2显存
-
• 2.新的异步拷贝指令,可以直接从HBM拷贝到SRAM
大幅度提高的显存、和显存的拷贝效率,使得FlashAttention的优势得以大幅发挥。因此 flashAttention 也依赖于GPU架构(A100以上)。




Page attention
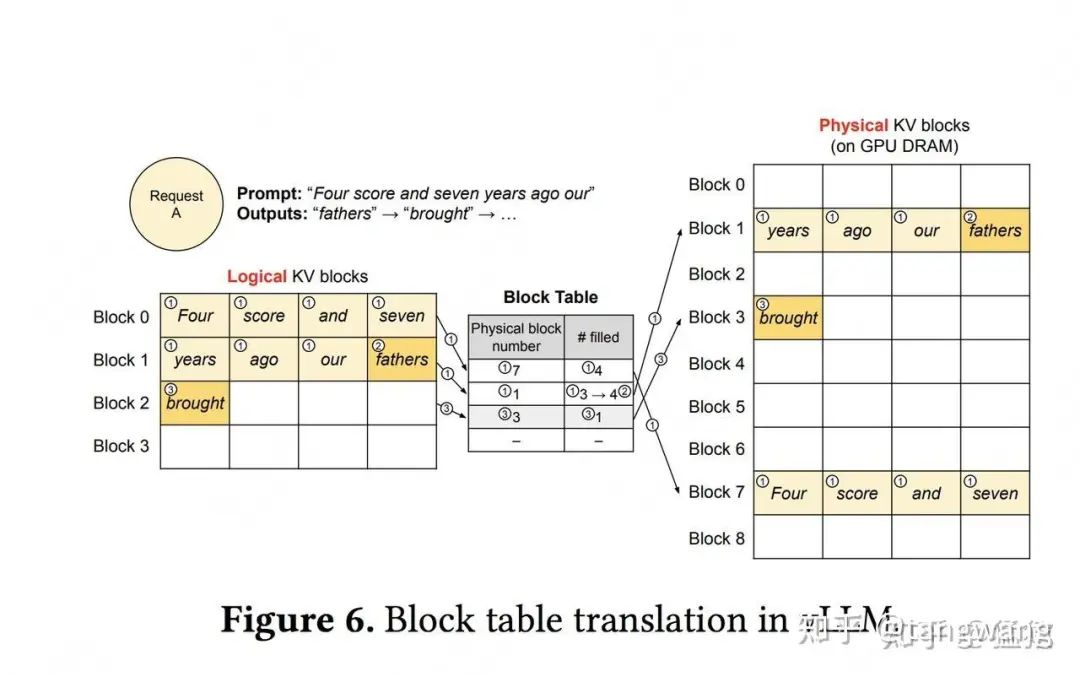
-
• 每个block类比于虚拟内存中的一个page。每个block的大小是固定的,在vLLM中默认大小为16,即可装16个token的K/V值
-
• Shared prefix:在某些大模型中,所有请求可能都会共享一个前置信息(比如system message: “假设你是一个有帮助的AI助手...."),这些前置信息没有必要重复存储KV cache
-
• Beam Search、并行采样(Parallel Sampling)中有大量的KV cache是重复的。内存使用量降低 55%。
-
• 对物理块的引用计数进行跟踪,并实现写时复制(Copy-on-Write)机制。
vLLM 主要用于快速 LLM 推理和服务,其核心是 PagedAttention,它将在操作系统的虚拟内存中分页的经典思想引入到 LLM 服务中。在无需任何模型架构修改的情况下,可以做到比 HuggingFace Transformers 提供高达 24 倍的 Throughput。而 PagedAttention 核心则是 attention_ops.single_query_cached_kv_attention
参考:
https://zhuanlan.zhihu.com/p/69...[5]
https://zhuanlan.zhihu.com/p/63...[6]
Ring attention
旨在解决处理长序列时面临内存限制问题。
参考:
ring attention + flash attention:超长上下文之路[7]
我们只需要把 seq_eln分为卡数那么多份(n = num_gpu),每张卡计算一个 block,只存储一份 Qi,K,И,通过跨卡的 p2p 通信互相传递 K,V,来实现迭代计算,就可以实现多卡的超长 context length
striped attention
-
• Striped Attention是Ring Attention的一个简单扩展,它通过改变设备间分配工作的方式来解决ring attention的工作负载不平衡的问题。
三、FFN部分的优化
MoE
参数量方面:近2/3的参数集中在FFN结构中。
计算量方面:如果不是超长序列,也是FFN结构占大头,序列越短,FFN计算量的占比越大。
通常认为FFN中的MLP压缩了大量的知识,有一些观点将这个MLP看成存储了大量具体知识的Key-Value存储器,那么也有利用让模型学习到在不同的context中访问不同的知识。MLP相对于transformer中的其他结构来讲,也更容易做稀疏化。
因此有充分的动机对FFN中的MLP进行稀疏化。

四、微调
有多种微调方式。Freeze-tuning,Adapter Tuning,Prefix-Tuning,P-Tuning,LoRA 等。
lora用的比较多。比如 72B微调,可以选择量化4bit、lora_dim = 64,具有较高的性价比。

五、训练相关
混合精度
直接使用float16的问题:
-
• 精度溢出:gradient×lr超出float16的精度,为0。
-
• 舍入误差:权重和梯度差异大,相加的时候被舍弃。
-
• 原因是:由于浮点数的特性,FP16 在两个相邻的,能够被 FP16 表达的数值之间存在一定的间隔,当计算数值存在于间隔之中时,运算将会出现舍入误差。
-
• 具体例子:在FP16中 与 完全一样,就是因为 的最小间隔为 ,因此 将在这次相加中丢失(未被丢失)。
-
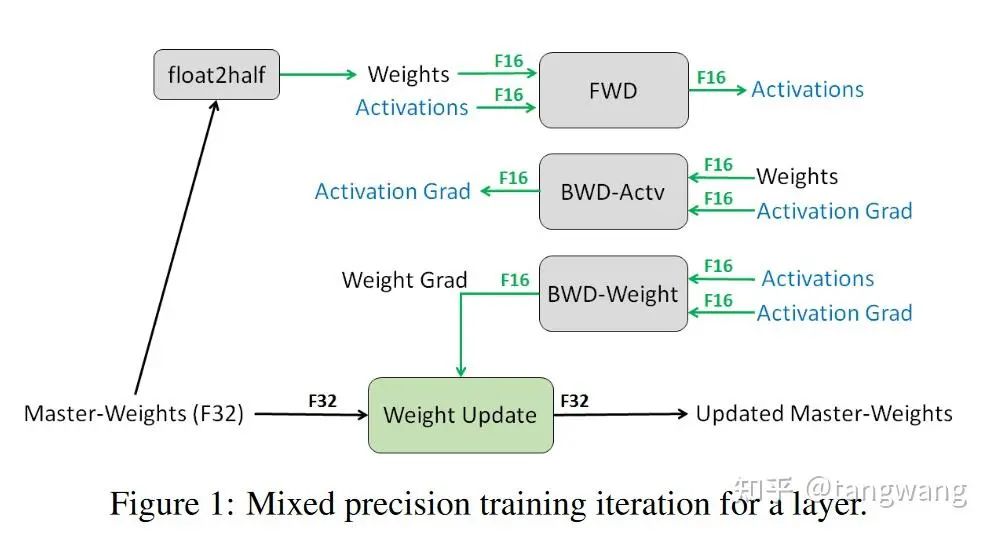
混合精度训练:
在传导过程中使用 FP16(一份权重一份梯度,即2份FP16),然后使用 FP32 接受更新的梯度以及保存模型(即优化器参数为FP32。对于adam来说,保存1份权重+2份辅助变量,即3份FP32)。
混合精度训练能够极大的提高模型训练速度,同时保留几乎 99%的训练精度。
具体过程:
使用float16权重进行前向传播、并反向传播得到float16的梯度;
通过优化器计算出float32精度的权重更新量并更新float32权重;
将float32权重转换为float16;
细节说明:
前向传播时,数据精度是 fp16。但根据 Hugging Face 源码[8]、 LLaMA 官方实现[9],在自注意力层有一个细节:算 softmax 之前,需要把数据精度转换成 fp32;softmax 算完后再转换回 fp16。
为什么保存两份权重反而显存占用降低?
训练的时候,前向+反向所占用的显存减半了,只是权重更新的时候使用了FP32,因此,总体上显存占用会显著减小。
看下面这张图可以比较清晰,为什么保存了多份权重,训练时候显存占用反而降低。
并行、调度、训练框架
数据并行、模型并行、流水线并行、张量并行
3D 并行:3D 并行实际上是三种常用并行训练技术的组合, 即数据并行、流水线并行和张量并行
相关的框架:
Huggingface Transformer
deepspeed
megatron
Megatron LM
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 使用的是模型并行(把一个层中间切开)


与gpipline(按层切开) 方式是正交、互补的
优点:在原始代码的基础上修改简单,不需要编译器,只需要改pytorch代码
通用性:只适用于transformers
把MLP 和attention拆开
MLP输入:b*l
ZeRO
超线性的加速,100B模型。
背景:
模型大了,一个卡放不下。模型并行(这里特指张量并行):垂直切开,每个层以内都要做通讯,通讯量太大,单机内多卡还行,多机器就不好(大概做到8卡,多了的话计算通讯比差)。内存花在什么地方:1. 参数的值 梯度 优化器的状态(冲量 variance等)。2. 中间值 临时的buffer。
-
• Optimizer->ZeRO1
-
• 将optimizer state分成若干份,每块GPU上各自维护一份
-
• 每块GPU上存一份完整的参数W,做完一轮foward和backward后,各得一份梯度,对梯度做一次 AllReduce(reduce-scatter + all-gather) , 得到完整的梯度G,由于每块GPU上只保管部分optimizer states,因此只能将相应的W进行更新,对W做一次All-Gather
-
-
• Gradient+Optimzer->ZeRO2
-
• 每个GPU维护一块梯度
-
• 每块GPU上存一份完整的参数W,做完一轮foward和backward后, 算得一份完整的梯度,对梯度做一次Reduce-Scatter,保证每个GPU上所维持的那块梯度是聚合梯度,每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次All-Gather,将别的GPU算好的W同步到自己这来
-
-
• Parameter+Gradient+Optimizer->ZeRO3
-
• 每个GPU维护一块模型状态
-
• 每块GPU上只保存部分参数W,做forward时,对W做一次 All-Gather ,取回分布在别的GPU上的W,得到一份完整的W, forward做完,立刻把不是自己维护的W抛弃,做backward时,对W做一次All-Gather,取回完整的W,backward做完,立刻把不是自己维护的W抛弃. 做完backward,算得一份完整的梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度,聚合操作结束后,立刻把不是自己维护的G抛弃。用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何AllReduce操作
-
-
• ZeRO-Offload
-
• forward和backward计算量高 ,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU
-
• update的部分计算量低 ,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等
-
• ZeRO-Offload 分为 Offload Strategy 和 Offload Schedule 两部分,前者解决如何在 GPU 和 CPU 间划分模型的问题,后者解决如何调度计算和通信的问题
-
offload
-
• ZeRO-Offload
-
• forward和backward计算量高 ,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU
-
• update的部分计算量低 ,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等
-
• ZeRO-Offload 分为 Offload Strategy 和 Offload Schedule 两部分,前者解决如何在 GPU 和 CPU 间划分模型的问题,后者解决如何调度计算和通信的问题
-
-
• ZeRO-Infinity
-
• 一是将offload和 ZeRO 的结合从 ZeRO-2 延伸到了 ZeRO-3,解决了模型参数受限于单张 GPU 内存的问题
-
• 二是解决了 ZeRO-Offload 在训练 batch size 较小的时候效率较低的问题
-
• 三是除 CPU 内存外,进一步尝试利用 NVMe 的空间
-
引用链接
[1] 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces: https://kexue.fm/archives/10091/comment-page-2[2] 陈star:Flash attention && flash decoding: https://zhuanlan.zhihu.com/p/691623115[3] 极市开发者平台-计算机视觉算法开发落地平台-极市科技: https://www.cvmart.net/community/detail/8302[4] 猛猿:图解大模型计算加速系列:Flash Attention V2,从原理到并行计算): https://zhuanlan.zhihu.com/p/691067658[5] https://zhuanlan.zhihu.com/p/69...: https://zhuanlan.zhihu.com/p/691038809[6] https://zhuanlan.zhihu.com/p/63...: https://zhuanlan.zhihu.com/p/638468472[7] ring attention + flash attention:超长上下文之路: https://zhuanlan.zhihu.com/p/683714620[8] Hugging Face 源码: https://github.com/huggingface/transformers/blob/ee4250a35f3bd5e9a4379b4907b3d8f9d5d9523f/src/transformers/models/llama/modeling_llama.py#L350C8-L351C111[9] LLaMA 官方实现: https://github.com/meta-llama/llama/blob/6c7fe276574e78057f917549435a2554000a876d/llama/model.py#L180C17-L180C42





![[HNCTF 2022 Week1]你知道什么是Py嘛?](https://i-blog.csdnimg.cn/direct/d51a133306fe482d9c97a904ce527aa3.png)