📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ VRT_ 关于视频修复的模型
- 背景介绍:
- 重要性:
- VRT的重要性和研究背景
- VRT的背景:
- VRT的重要性:
- 视频修复概述
- 定义与目标
- 与单图像修复的区别
- 对时间信息利用的需求
- VRT模型详解
- 整体框架
- 多尺度设计和模块功能
- 关键创新点
- 实验结果
- VRT在不同视频修复任务上的表现
- 与其他模型性能对比
- 长视频序列和短视频序列的性能表现
- 创新性和实用性的强调
- VRT的优势与创新点
- VRT相对于现有方法的优势
- 并行计算、长时序依赖建模和多尺度设计的创新性
- VRT在不同任务上的性能提升
- VRT在实际场景中的应用潜力
- 视频修复领域未来研究的展望
- VRT技术革新对其他领域的启示
- 结论
- 部署过程
背景介绍:
随着数字媒体的广泛应用,视频内容的制作和传播变得越来越普遍。然而,由于各种原因,如传输、存储、录制设备等,视频中常常存在各种质量问题,包括模糊、噪音、低分辨率等。这些问题直接影响了用户体验和观看效果,因此视频修复技术变得至关重要。
重要性:
-
提升用户体验: 视频修复技术可以显著提升观众在观看视频时的视觉感受,使得视频内容更加清晰、锐利。
-
保护历史遗产: 对于古老的电影、录像等文化遗产,视频修复技术有助于保存和修复这些宝贵的历史文化资料。
-
视频内容分析: 在视频内容分析和计算机视觉领域,高质量的视频是实现准确分析和识别的基础。
VRT的重要性和研究背景
VRT的背景:
随着深度学习领域的持续进步,传统视频修复手段在应对复杂场景及长视频序列处理时遭遇了多重难题。单帧修复策略往往忽略了时间维度信息的充分利用,而既往采用的滑动窗口技术和循环架构则在构建长时依赖关系模型方面展现出局限性。
VRT的重要性:
-
并行计算: VRT 引入了并行帧预测的机制,使其能够更高效地处理视频序列,实现并行计算,提高修复效率。
-
长时序依赖建模: VRT 在设计上充分考虑了长时序依赖建模的需求,通过多尺度和自注意机制,使其在处理长视频序列时具备更强的建模能力。
-
多尺度设计: VRT 的多尺度设计有助于处理视频中的不同运动和细节,提高了模型对不同尺度信息的捕捉能力。
视频修复概述
定义与目标
视频修复的定义: 视频修复是一种通过应用计算机视觉和图像处理技术,从低质量的视频帧中重建高质量的视频序列的过程。其目标是改善视频质量,使得观众在观看时能够获得更清晰、更真实的视觉体验。
与单图像修复的区别
相较于单图像修复仅聚焦于从单一图像中恢复缺失或受损的信息,视频修复则是一个更为复杂的过程,它涵盖了整个视频序列的处理。视频修复特别关注帧与帧之间的时间顺序关系,旨在更有效地利用这些时间信息来执行修复工作。这种时间顺序关系可能涵盖相邻帧间的运动轨迹、变化模式等动态特征。
对时间信息利用的需求
时间信息在视频理解和修复过程中占据着举足轻重的地位。视频中的帧与帧之间的关联性、动态变迁以及运动轨迹等,均为修复工作提供了不可或缺的上下文背景。遗憾的是,传统的单图像修复手段难以捕捉并有效利用这些时序上的信息,而视频修复技术则力求通过整合多帧图像的信息,来优化和提升修复的质量。
然而,当涉及到多帧视频的处理时,一系列新的挑战也随之而来,比如帧与帧之间的精确对齐、动态场景中的信息快速更迭、以及长时间序列的依赖性等。因此,视频修复模型的设计必须能够巧妙地利用这些信息,从而确保修复结果的准确性和鲁棒性。
本文所涉及的所有资源的获取方式:这里
VRT模型详解
整体框架

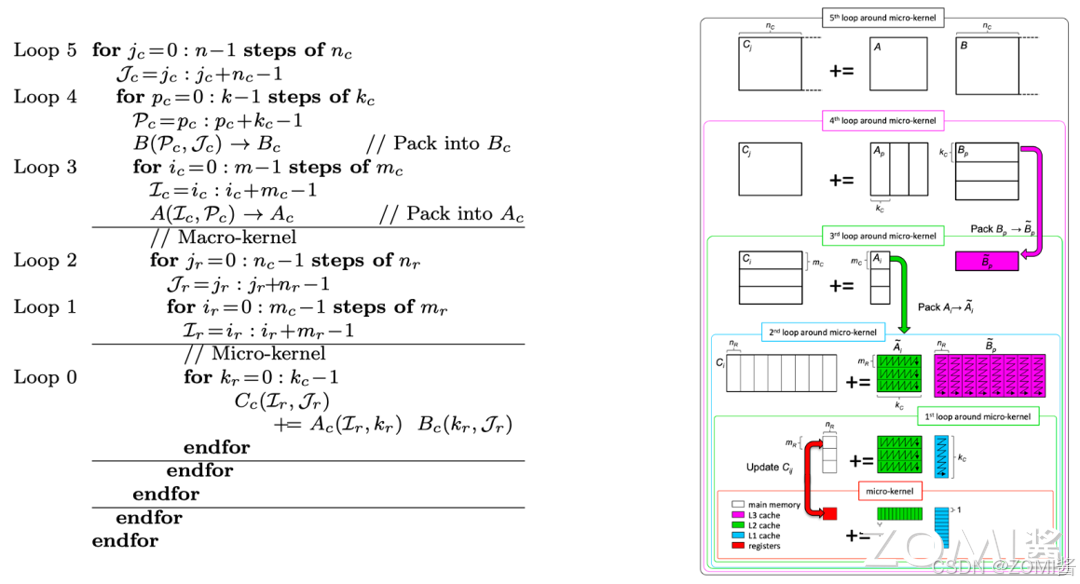
Figure 1. 绿色圆圈:低质量(LQ)输入帧;蓝色圆圈:高质量(HQ)输出帧。t - 1、t 和 t + 1 是帧序号;虚线表示不同帧之间的融合。
VRT整体框架: Video Restoration Transformer(VRT)是一个专注于视频修复任务的深度学习模型。其整体框架由多个尺度组成,每个尺度包含两个关键模块:Temporal Mutual Self Attention(TMSA)和Parallel Warping。VRT旨在通过并行帧预测和长时序依赖建模,充分利用多帧视频信息进行高效修复。
多尺度设计和模块功能

多尺度设计: VRT采用多尺度的结构,每个尺度内部包含TMSA和Parallel Warping两个模块。这种设计允许模型在不同分辨率的特征上进行操作,以更好地适应视频序列中的细节和动态变化。

TMSA模块: Temporal Mutual Self Attention模块负责将视频序列分割为小片段,在这些片段上应用互相注意力,用于联合运动估计、特征对齐和特征融合。同时,自注意力机制用于特征提取。这一设计使得模型能够对多帧信息进行联合处理,解决了长时序依赖性建模的问题。

Parallel Warping模块: Parallel Warping模块用于通过并行特征变形从相邻帧中进一步融合信息。它通过平行特征变形的方式,有效地将邻近帧的信息融入当前帧。这一步骤类似于特征的引导变形,进一步提高了模型对多帧时序信息的利用效率。
关键创新点
图2展示了提出的Video Restoration Transformer(VRT)的框架。给定T个低质量输入帧,VRT并行地重建T个高质量帧。它通过多尺度共同提取特征、处理对齐问题,并在不同尺度上融合时间信息。在每个尺度上,VRT具有两种模块:时间互相自注意力(TMSA,见第3.2节)和平行变形(见第3.3节)。为了清晰起见,图中省略了不同尺度之间的下采样和上采样操作。

图2. Video Restoration Transformer(VRT)的框架
图2. VRT框架图说明:
- 输入帧序列: VRT接收T个低质量输入帧,这些帧构成了视频序列的初始状态。
- 特征提取: VRT通过多尺度网络对低质量输入帧进行特征提取,得到浅层特征ISF。
- 多尺度处理: VRT采用多尺度设计,通过下采样和上采样操作处理特征,以适应不同分辨率的信息。
Temporal Mutual Self Attention(TMSA): 在每个尺度上,VRT使用TMSA模块,实现了帧间的互相自注意力,用于处理对齐和融合问题。 - Parallel Warping: 平行变形模块用于进一步增强特征对齐和融合,处理特征之间的空间错位。
- 多尺度特征融合: VRT通过跳跃连接将同一尺度的特征进行融合,保留了多尺度信息。
- TMSA进一步提炼特征: 在多尺度处理后,VRT在每个尺度上添加了更多TMSA模块,用于进一步提炼特征。
重建: 最后,VRT通过对浅层特征ISF和深层特征IDF的加和进行重建,输出高质量的帧序列。
该框架的关键创新点在于多尺度设计、TMSA和平行变形的结合,使得VRT能够有效处理视频修复任务,包括超分辨率、去模糊、去噪等。
并行帧预测和长时序依赖建模: VRT的关键创新点之一是引入了并行帧预测和长时序依赖建模。通过并行处理多帧,模型能够更高效地利用时序信息,提高修复的准确性。长时序依赖建模则通过TMSA模块实现,使得模型能够更好地捕捉帧与帧之间的长期关系,从而更好地还原视频序列。
实验结果
VRT在不同视频修复任务上的表现

不同任务表现: VRT在视频超分辨率、视频去模糊、视频去噪、视频帧插值和时空视频超分辨率等五个任务上都进行了实验。通过对比实验结果,VRT展现了在各项任务中的优越性能,提供了高质量的修复效果。
与其他模型性能对比

性能对比: VRT与其他当前主流的视频修复模型进行了性能对比,涵盖了14个基准数据集。实验结果显示,VRT在各个数据集上都明显优于其他模型,表现出色。尤其在某些数据集上,VRT的性能提升高达2.16dB,凸显了其在视频修复领域的卓越性能。

长视频序列和短视频序列的性能表现
处理长短序列的能力: VRT在长视频序列和短视频序列上都表现出色。相较于传统的循环模型,在短序列上VRT没有性能下降,并且在长序列上取得了更好的效果。这突显了VRT在处理不同长度视频序列时的灵活性和鲁棒性。
创新性和实用性的强调
VRT的创新性和实用性: 通过实验结果的分析,VRT的创新性主要体现在并行帧预测和长时序依赖建模。这两个关键创新点使得VRT能够更好地利用多帧信息,处理不同任务上的视频修复。定量和定性的结果展示表明,VRT在各个方面都取得了显著的进展,为视频修复领域带来了新的解决方案。
VRT的优势与创新点
VRT相对于现有方法的优势
多方面优势: VRT相较于现有的视频修复方法展现了明显的优势。首先,在多个视频修复任务上,VRT都实现了显著的性能提升,表现出色。其优势主要体现在高质量修复、更好的时序依赖建模和更灵活的处理长短序列的能力。
并行计算、长时序依赖建模和多尺度设计的创新性
并行处理能力:VRT模型的一大创新之处在于其并行帧预测机制。与传统的逐帧处理修复模型相比,VRT利用并行计算技术,实现了对多帧数据的高效整合与利用,从而显著提升了整体的修复质量。
长时依赖建模能力:VRT通过引入Temporal Mutual Self Attention(TMSA)机制,成功建立了对视频序列中长时依赖关系的模型。这一设计使得模型能够更精准地捕捉帧与帧之间的长期关联,进而在视频修复任务中展现出更强的性能。
多尺度适应性:VRT的多尺度设计赋予了模型处理不同分辨率和尺度视频信息的灵活性。这种设计使得模型能够更精细地捕捉视频序列中的细节特征和动态变化,从而在各类视频修复任务中都取得了优异的表现。
VRT在不同任务上的性能提升
任务通用性: VRT不仅在单一任务上有卓越表现,而且在涉及视频超分辨率、视频去模糊、视频去噪、视频帧插值和时空视频超分辨率等多个任务时都取得了显著的性能提升。这证明了VRT的通用性和适应性,使其成为一个全方位的视频修复解决方案。# 实际应用与未来展望
VRT在实际场景中的应用潜力
多领域应用: VRT作为视频修复领域的先进模型,具有广泛的实际应用潜力。在视频编辑、广告制作和媒体产业等领域,VRT的能力可以带来更高质量的视频修复效果,提升整体视觉体验。
医学影像处理: VRT的并行计算和长时序依赖建模等特性也为医学领域的视频处理提供了新的可能性。在医学影像恢复和分析中,VRT可以用于提高视频序列的清晰度和质量,有望在疾病诊断和治疗过程中发挥积极作用。
视频修复领域未来研究的展望
性能进一步提升: 未来的研究可以集中在进一步提升VRT在不同视频修复任务上的性能。通过引入更复杂的注意机制、更有效的特征提取方式,以及更智能的模型学习方法,可以进一步提高视频修复的效果。
多模态修复: 随着多模态数据的广泛应用,未来的研究还可以探索VRT在处理多模态视频修复任务上的潜力。通过结合图像、语音等多种模态信息,实现更全面的视频修复。
VRT技术革新对其他领域的启示
迁移学习和跨领域应用: VRT的技术革新对于其他领域的深度学习模型设计具有启示意义。在迁移学习和跨领域应用方面,VRT的多尺度设计和并行计算等特性可以为其他任务的模型设计提供有益启发。
结论
经过对VRT的全面审视与深入剖析,我们清晰地看到了它在视频修复领域的杰出成就。VRT凭借并行帧预测、长时序依赖关系的精确建模以及多尺度设计的巧妙运用,实现了视频修复性能的显著提升。其在多种任务上的出色表现以及在实际应用场景中的巨大潜力,已使VRT成为视频修复技术的前沿代表。
我们鼓励更多的研究者投身于视频修复领域的技术难题中,借鉴VRT的成功经验,为该领域的持续发展贡献力量。不仅如此,VRT所展现出的创新精神和通用性也为深度学习在其他研究领域的应用提供了宝贵的启示,进一步推动了整个人工智能领域的进步与发展。
部署过程
这段代码是一个视频恢复(Video Restoration)模型的测试脚本,用于在测试集上评估模型的性能。下面是对代码的详细解析:
python">import argparse
import cv2
import glob
import os
import torch
import requests
import numpy as np
from os import path as osp
from collections import OrderedDict
from torch.utils.data import DataLoaderfrom models.network_vrt import VRT as net
from utils import utils_image as util
from data.dataset_video_test import VideoRecurrentTestDataset, VideoTestVimeo90KDataset, \SingleVideoRecurrentTestDataset, VFI_DAVIS, VFI_UCF101, VFI_Vid4
argparse: 用于解析命令行参数的库。
cv2: OpenCV库,用于图像处理。
glob: 用于查找文件路径的模块。
os: 提供与操作系统交互的功能。
torch: PyTorch深度学习框架。
requests: 用于发送HTTP请求的库。
numpy: 用于科学计算的库。
OrderedDict: 有序字典,按照插入的顺序保持元素的顺序。
DataLoader: PyTorch的数据加载器,用于加载训练和测试数据。
python">def main():parser = argparse.ArgumentParser()# ...(解析命令行参数的设置)args = parser.parse_args()# 定义设备(使用GPU或CPU)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 准备模型model = prepare_model_dataset(args)model.eval()model = model.to(device)# ...(根据数据集类型准备测试集)# 定义保存结果的目录save_dir = f'results/{args.task}'if args.save_result:os.makedirs(save_dir, exist_ok=True)test_results = OrderedDict()# ...(初始化用于保存评估结果的数据结构)# 遍历测试集进行测试for idx, batch in enumerate(test_loader):# ...(加载测试数据)with torch.no_grad():output = test_video(lq, model, args)# ...(处理模型输出,保存结果,计算评估指标)# 输出最终评估结果# ...
准备模型和数据集的函数 prepare_model_dataset(args):
python">def prepare_model_dataset(args):# ...(根据任务类型选择合适的模型和数据集)return model
根据命令行参数 args.task 的不同值,选择对应的视频恢复模型。
下载并加载预训练模型权重。
下载并准备测试数据集。
测试视频的函数 test_video(lq, model, args):
python">def test_video(lq, model, args):# ...(根据需求测试整个视频或分割成多个片段进行测试)return output
根据命令行参数 args.tile 和 args.tile_overlap 的设置,选择将视频分割成片段进行测试或测试整个视频。
调用 test_clip() 函数测试每个片段。
测试视频片段的函数 test_clip(lq, model, args):
python">def test_clip(lq, model, args):# ...(根据需求测试整个片段或分割成多个子区域进行测试)return output
根据命令行参数 args.tile 和 args.tile_overlap 的设置,选择将视频片段分割成子区域进行测试或测试整个片段。
返回测试结果。
主函数入口:
python">if __name__ == '__main__':main()编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里