1. 统一列表初始化
1.1 C++11 之前的初始化方式
在 C++11 标准中,引入了一个非常实用且强大的特性——统一列表初始化(Uniform Initialization),它为我们在初始化各种类型的对象时提供了一种统一且方便的语法形式,极大地改善了代码的可读性以及初始化操作的灵活性。
在 C++11 之前,初始化不同类型的对象往往有着不同的语法规则,例如:
- 对于普通内置类型,我们可以像这样初始化:
int a = 5; // 传统的赋值初始化方式
- 对于数组,可以使用如下方式:
int arr[3] = {1, 2, 3};
- 而对于类对象,如果有合适的构造函数,可能会通过构造函数来初始化,像:
class MyClass {
public:MyClass(int x, int y) : m_x(x), m_y(y) {}
private:int m_x;int m_y;
};MyClass obj(10, 20); // 通过构造函数初始化对象
这种多样化的初始化语法在复杂的代码环境中容易造成混淆,并且当涉及到更复杂的类型(比如 STL 容器等)时,初始化的方式可能不够直观。C++11 的统一列表初始化旨在解决这些问题,提供一种通用的、能适用于多种类型的初始化语法。
统一列表初始化使用花括号 {} 来进行初始化操作,以下是一些常见的示例展示其语法应用:
1.2 内置类型初始化
int num{10}; // 使用统一列表初始化语法初始化整型变量
double d = {3.14}; // 初始化双精度浮点型变量
这里不再局限于传统的 = 赋值初始化方式,通过花括号可以更直观地表示这是一个初始化操作。使用初始化列表时,可添加等号(=),也可不添加。
1.3 数组初始化
int arr[]{1, 2, 3}; // 省略数组大小,编译器会根据初始化列表中的元素个数自动推断数组大小
int anotherArr[5]{1, 2}; // 部分初始化,未指定的元素会被初始化为 0(对于基本数据类型而言)
int* pa = new int[4]{ 0 };//new表达式也可同时初始化
与之前的数组初始化语法相比,更加简洁明了,尤其是省略数组大小的情况,让代码更具灵活性。
1.4 类对象初始化
1.4.1 默认构造函数情况
如果类有默认构造函数,我们可以这样初始化对象:
class SimpleClass {
public:SimpleClass() {}
};SimpleClass sc{}; // 使用统一列表初始化调用默认构造函数
1.4.2 带参数构造函数情况
对于带有参数的构造函数的类,可以直接传递参数列表在花括号内进行初始化:
class Point {
public:Point(int x, int y) : m_x(x), m_y(y) {}
private:int m_x;int m_y;
};Point p{3, 5}; // 通过统一列表初始化调用带两个参数的构造函数
1.5 initializer_list 容器
initializer_list 是 C++11 一个标准库中的类模板。它的主要作用是用于表示一个特定类型的元素列表,旨在方便地处理那些能够以列表形式进行初始化的情况,比如在类的构造函数中接收一组初始化值,或者用于函数参数传递一组同类型的数据等。
1.5.1 初始化
要使用 initializer_list,首先需要包含对应的头文件 <initializer_list>,然后就可以像声明其他模板类型一样来声明它。例如,如果我们想创建一个用于存放整型数据的 initializer_list,可以这样写:
#include <initializer_list>
#include <iostream>int main() {std::initializer_list<int> my_list = {1, 2, 3};return 0;
}
在上述代码中,std::initializer_list<int> 声明了一个能够容纳整型元素的 initializer_list 类型的对象 my_list,并通过花括号 {} 初始化它,使其包含了 1、2、3 这三个整型元素。
1.5.2 访问元素
initializer_list 提供了类似于容器的访问方式,不过它相对来说比较简单,主要有两个常用的成员函数:begin() 和 end()。这两个函数返回的是指向列表中第一个元素和最后一个元素之后位置的迭代器(遵循 STL 容器迭代器的通用规则),我们可以利用这两个迭代器来遍历整个列表中的元素。示例如下:
#include <initializer_list>
#include <iostream>int main() {std::initializer_list<int> my_list = {4, 5, 6};for (auto it = my_list.begin(); it!= my_list.end(); ++it) {std::cout << *it << " ";}return 0;
}
在这个示例中,通过迭代器遍历 initializer_list 中的元素,并将每个元素输出到控制台,最终会打印出 4 5 6。

此外,由于 initializer_list 支持基于范围的 for 循环,所以我们也可以更简洁地遍历它,如下所示:
#include <initializer_list>
#include <iostream>int main() {std::initializer_list<int> my_list = {7, 8, 9};for (int element : my_list) {std::cout << element << " ";}return 0;
}
同样,这段代码也能正确地将 7、8、9 依次打印出来,基于范围的 for 循环在内部其实也是利用了 begin() 和 end() 这两个迭代器来实现元素的遍历。
需要注意的是,initializer_list 所表示的元素列表是不可变的,也就是说一旦创建了 initializer_list 对象,就不能修改其内部的元素了。例如,下面这样尝试修改元素的代码是无法通过编译的:
#include <initializer_list>
#include <iostream>int main() {std::initializer_list<int> my_list = {10, 11, 12};// 以下代码会编译出错,因为不能修改 initializer_list 中的元素*(my_list.begin()) = 13;return 0;
}
这种不可变的特性符合它通常用于初始化操作的设计初衷,确保传递进来的初始化数据在初始化过程中不会被意外更改。
1.5.3 应用
当一个类存在多个构造函数时,包含接收 initializer_list 的构造函数会参与到构造函数的重载决议中。通常情况下,如果调用构造函数时传递的参数形式符合 initializer_list 的初始化列表形式,那么编译器会优先调用对应的接收 initializer_list 的构造函数。例如:
class MyClass {
public:MyClass(int value) {std::cout << "Constructor with single int parameter called." << std::endl;}MyClass(std::initializer_list<int> list) {std::cout << "Constructor with initializer_list parameter called." << std::endl;}
};int main() {MyClass obj1(5); // 调用单个整型参数的构造函数MyClass obj2({5}); // 调用接收 initializer_list 的构造函数MyClass obj3{5}; // 同样调用接收 initializer_list 的构造函数return 0;
}

在这个例子中,obj1 的初始化调用了普通的带单个整型参数的构造函数,而 obj2 和 obj3 的初始化由于传递参数的形式是花括号包裹的单个元素,符合 initializer_list 的语法特征,所以编译器会调用接收 initializer_list 的构造函数。
所以说 initializer_list为一些不定参数的类,提供了一种更加方便的初始化方式。
class ComplexClass {
public:ComplexClass(std::initializer_list<int> list) {for (auto element : list) {// 进行一些基于初始化列表元素的操作}}
};ComplexClass cc{1, 2, 3}; // 调用接受初始化列表的构造函数
特别是对于标准模板库(STL)中的容器,如 vector、list、map 等,这一点得到了很好的应用。
vector<int> v = { 1,2,3,4 };
list<int> lt = { 1,2 };
// 这里{"sort", "排序"}会先初始化构造一个pair对象
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
// 使用大括号对容器赋值
v = {10, 20, 30};
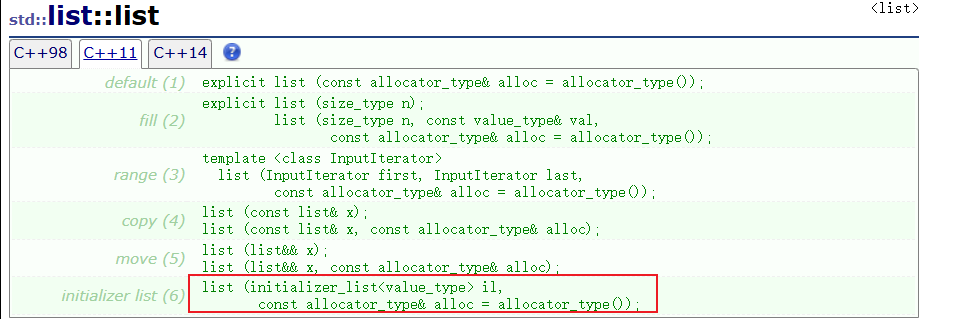
之所以能够这样使用的原因就是 STL 容器在实现时提供了对应的 initializer_list构造对应对象的构造函数与赋值重载。比如说,以下是 list的构造函数:
2. 变量类型推导
auto_209">2.1 auto
auto__210">2.1.1 auto 的使用
在传统的 C++ 编程中,声明变量时需要明确指定变量的类型,例如:
int num = 10;
double pi = 3.14;
std::string str = "Hello, World!";
然而,随着 C++ 语言的发展以及模板编程、STL(标准模板库)等复杂特性的广泛应用,类型的书写有时候会变得非常冗长和繁琐,尤其是涉及到一些复杂的模板类型或者函数返回值类型难以直接明确表述时。auto 关键字就是为了解决这个问题而诞生的,它能够让编译器根据变量的初始值自动推导出变量的类型。
简单来说,使用 auto 关键字,我们可以在声明变量时省略具体的类型声明部分,让编译器帮我们去确定这个变量实际应该是什么类型,代码的书写也就变得更加简洁。例如:
auto num = 10; // 编译器自动推导出 num 为 int 类型
auto pi = 3.14; // 编译器自动推导出 pi 为 double 类型
auto str = std::string("Hello, World!"); // 编译器自动推导出 str 为 std::string 类型
2.1.2 注意事项
如果初始化表达式带有顶层 const(即修饰变量本身,表示变量的值不能被修改),使用 auto 推导时,顶层 const 会被忽略,变量本身不会成为 const 类型。例如:
const int num = 10;
auto var = num; // var 的类型为 int,顶层 const 被忽略,var 可以被重新赋值
但是,如果想要保留顶层 const 属性,可以使用 const auto 的形式来声明变量,如下所示:
const int num = 10;
const auto var = num; // var 的类型为 const int,不能被重新赋值
对于底层 const(即修饰指针或引用所指向的对象,表示不能通过该指针或引用修改所指向的对象),auto 关键字会正确地推导并保留底层 const 属性。例如:
const int num = 10;
const int* ptr = #
auto new_ptr = ptr; // new_ptr 的类型为 const int*,保留了底层 const,不能通过 new_ptr 修改所指向的对象
decltype_252">2.2 decltype
decltype的主要作用是用于查询表达式的类型,编译器会根据给定表达式的实际类型来推导出对应的类型,然后可以用这个推导出的类型去定义变量、作为函数返回值类型等。
简单来说,就是让编译器帮你自动确定某个表达式的类型是什么,而不需要你显式地去指定类型。
2.2.1 语法形式
decltype(表达式)就是其基本语法结构,例如:
int num = 10;
decltype(num) anotherNum; // anotherNum被推导为int类型,因为num是int类型
这样,当你已经有了一个确定类型的变量,又想定义同类型的其他变量时,decltype就很方便,不需要重复写具体的类型(尤其是对于复杂类型,比如自定义结构体指针类型等情况,使用decltype能避免手动书写复杂类型名时出错)。
2.2.2 函数返回值类型的推导
在C++11 之前,函数返回值类型需要在函数声明时就明确写出来,但是有些复杂情况很难提前确定具体类型,这时decltype就可以帮忙了。例如:
template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) { // 根据a+b表达式的类型来确定函数返回值类型return a + b;
}
上述代码定义了一个函数模板add,它可以接受不同类型的参数(T1和T2类型),然后通过decltype(a + b)来让编译器自动推导a + b运算结果的类型,并将这个类型作为函数add的返回值类型。这样函数就能灵活地适应各种支持+运算的不同类型参数组合了,比如int和double相加、两个自定义类对象(如果重载了+运算符)相加等情况。
2.2.3 配合typedef或using
int arr[5];
using ArrayType = decltype(arr); // 使用decltype推导arr的类型(在这里是int[5],即包含5个元素的int数组类型),并定义别名ArrayType
ArrayType anotherArr; // 相当于定义了int[5]类型的anotherArr数组
这种方式可以方便地给一些复杂的、通过表达式才能确定的类型创建一个更简洁易懂的别名,便于后续代码中使用该类型进行变量定义等操作。
2.2.4 注意实现
decltype在推导类型时,括号的存在与否可能会导致不同的结果。例如:
int num = 10;
decltype((num)) refToNum = num; // 这里推导的是int&类型,是num的引用,因为(num)是一个左值表达式
decltype(num) anotherNum = num; // 这里推导的是int类型,anotherNum是一个新的int变量
在使用时要特别留意,如果想推导得到引用类型,通常可以使用带括号的表达式形式(前提是该表达式本身对应的是一个左值)。
auto_299">2.2.5 与auto的区别
虽然auto和decltype都和类型推导相关,但它们有明显不同:
2.3 nullptr
在C++早期版本中,通常使用NULL来表示空指针。然而,NULL实际上是一个宏定义,在C语言中它一般被定义为(void *)0,但在C++中,为了保持类型安全(因为 C++ 中不能直接将void *类型隐式转换为其他指针类型),它被定义为整数类型的0。
/* Define NULL pointer value */
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else /* __cplusplus */
#define NULL ((void *)0)
#endif /* __cplusplus */
#endif /* NULL */
这就可能导致一些混淆和潜在的类型不匹配问题,特别是在函数重载等场景下。例如:
void func(int i) {std::cout << "Called func(int)" << std::endl;
}void func(void *p) {std::cout << "Called func(void *)" << std::endl;
}int main() {func(NULL); // 在C++中,会调用func(int),而不是期望中的func(void *),因为NULL被当作整数0处理了return 0;
}
为了解决这类问题,C++11引入了nullptr关键字来明确地表示空指针,它具有更好的类型安全性
- 类型特性:
nullptr的类型是std::nullptr_t,这是一种特殊的类型。所有的指针类型都可以隐式转换为std::nullptr_t类型,反过来,std::nullptr_t类型也可以隐式转换为所有的指针类型,这使得它能很自然地在各种涉及指针的场景中表示空指针的情况。例如:
int *ptr1 = nullptr; // 正确,将nullptr赋值给int指针类型
double *ptr2 = nullptr; // 同样正确,用于double指针类型
- 语法使用:在代码中,当你需要将一个指针初始化为空指针状态,或者将一个指针赋值为空指针时,就可以直接使用
nullptr。比如:
class MyClass {// 类的定义相关内容
};MyClass *objPtr = nullptr; // 初始化一个指向MyClass对象的空指针
if (objPtr == nullptr) {// 执行相关逻辑,判断指针是否为空
}
3. 范围 for
C++11 中的范围 for 循环(也称作基于范围的 for 循环,Range-based for loop)是一种语法糖,它提供了一种简洁且方便的方式来遍历容器(如数组、vector、list 等)或其他可迭代对象中的元素。以下是关于它的详细介绍:
范围 for 循环的基本语法格式如下:
for ( decltype(容器)::value_type& 元素变量名 : 容器对象 ) {// 循环体,在这里可以对元素变量名所代表的元素进行操作
}
不过在实际使用中,更常见、更简洁的写法是(编译器会自动进行合适的类型推导等处理):
for ( auto& 元素变量名 : 容器对象 ) {// 循环体,对元素进行操作
}
例如,下面分别是使用传统 for 循环和范围 for 循环遍历 vector 容器的示例对比:
传统 for 循环遍历 vector:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};for (size_t i = 0; i < vec.size(); ++i) {std::cout << vec[i] << " ";}std::cout << std::endl;return 0;
}
使用范围 for 循环遍历 vector:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};for (auto& element : vec) {std::cout << element << " ";}std::cout << std::endl;return 0;
}
可以看到,范围 for 循环的代码更加简洁直观,无需手动去管理索引、判断边界等操作。

当使用范围 for 循环时,编译器实际上会将其展开为类似传统 for 循环的代码形式,它会自动获取容器的开始迭代器和结束迭代器(通过调用容器的 begin() 和 end() 方法,如果容器不支持这两个方法则无法使用范围 for 循环进行遍历),然后按照迭代器的顺序依次访问容器中的每个元素,每次将当前元素绑定到循环中定义的变量上,使得在循环体中可以方便地对元素进行操作。
4. STL 的变化
4.1 新增的容器
首先 C++11中新增了四个容器,分别是 array,forward_list,unordered_map 和 unordered_set。其中 unordered_map与 unordered_set在前面我们已经介绍过了,接下来我们来简要介绍一下 array与 forword_list。
4.1.1 array 容器
array是C++11引入的一个固定大小的数组容器,它位于<array>头文件中。它封装了C++中内置的普通数组,提供了更符合现代C++编程风格的接口以及一些额外的便利性和安全性保障,在行为表现上更像是一个“智能数组”。
特点及优势:
- 固定大小:与普通的C风格数组一样,在定义时就确定了其大小,后续不能动态改变。例如:
std::array<int, 5> myArray;就定义了一个能容纳5个int类型元素的std::array,这个大小在编译时就固定下来了。- 安全性提升:它避免了普通数组常见的一些越界访问等问题,因为它重载了
[]运算符等操作,并且会在编译阶段对一些非法访问进行检查。例如,当你试图访问超出其大小范围的元素时,编译器会报错,而不像普通数组那样可能在运行时产生难以察觉的错误(比如访问了未初始化的内存区域等情况)。
例如:
#include <iostream>
#include <array>int main() {std::array<int, 4> arr = {1, 2, 3, 4};for (size_t i = 0; i < arr.size(); ++i) {std::cout << arr[i] << " ";}std::cout << std::endl;return 0;
}
4.1.2 forward_list
forward_list是C++11引入的一个单向链表容器,定义在<forward_list>头文件中。它只支持单向的遍历,即只能从链表头开始依次向后访问节点,每个节点包含数据以及指向下一个节点的指针,与双向链表(如std::list)相比,它的空间开销更小,因为不需要额外存储指向前一个节点的指针。
特点及优势:
- 空间效率:由于没有前向指针,对于内存空间比较敏感且只需要单向顺序访问的应用场景来说,它能节省一定的内存空间,在存储大量节点时这种空间优势可能会比较明显。
- 插入和删除操作高效(在特定位置):在链表头部进行元素的插入和删除操作非常高效,时间复杂度为常数级别
O(1),因为只需要简单地调整指针指向即可。
例如:
#include <iostream>
#include <forward_list>int main() {std::forward_list<int> flist;flist.push_front(1); // 在链表头部插入元素1,效率很高flist.push_front(2); // 再插入元素2for (auto& element : flist) {std::cout << element << " ";}std::cout << std::endl;return 0;
}
4.2 字符串转换函数
C++11也提供了各种内置类型与 string 之 间相互转换的函数,比如 to_string、stoi、stol、stod 等函数。


除此之外C++11 也为每个容器都增加了一些新方法,比如:
- 提供了一个以
initializer_list作为参数的构造函数,用于支持列表初始化。- 提供了
cbegin和cend方法,用于返回const迭代器。- 提供了
emplace系列方法,并在容器原有插入方法的基础上重载了一个右值引用版本的插入函数,用于提高向容器中插入元素的效率。


![[AI] 人工智能会导致大规模失业吗?——技术发展与就业关系的深度解析](/images/no-images.jpg)

