作为 Python 和 ML 的初学者,我经常依赖 scikit-learn 来完成几乎所有的项目。它的简单性和多功能性使实现各种算法成为一种令人着迷的体验。
现在,令人兴奋的是,scikit-learn 通过Scikit-LLM引入了 LLM 功能,从而进一步发展。这种集成将 GPT、Vertex、Gemma、Mistral、Llama 等大型语言模型的强大功能带入了 scikit-learn 生态系统,使其成为机器学习爱好者和专业人士的更强大的工具。
根据该库的文档,“Scikit-LLM 允许你将强大的语言模型无缝集成到 scikit-learn 中,以增强文本分析任务。”
注意:本文中的所有代码示例均取自 Scikit-LLM 的文档

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
1、关于Scikit-LLM库
在 Scikit-LLM 中,估算器根据它们使用的语言模型 API 类型进行分组,这被称为“后端系列”。这种分组基于 API 格式,而不是语言模型的实际架构。例如,任何遵循 OpenAI API 格式的模型都归类为 GPT 系列,无论使用哪种提供商或模型架构。每个系列都有自己的一组估计器,位于特定的子模块中。
例如,零样本分类器在不同的后端系列下可用:GPT 系列中的 ZeroShotGPTClassifier 和 Vertex 系列中的 ZeroShotVertexClassifier。当不同的提供商为其模型添加其他提供商可能不支持的独特功能时,将这些后端系列分开可以提供灵活性。尽管如此,为了确保易用性,系列数量仍保持最少。
除非另有说明,否则将使用系列的默认后端。例如,OpenAI 后端是 GPT 系列的默认后端,但用户可以通过在模型设置中指定它来切换到 Azure 后端。但是,并非所有模型都支持每个后端。
2、GPT 系列
GPT 系列包括所有使用 OpenAI API 格式的后端,OpenAI 后端为默认后端。如果没有提及特定后端,则使用 OpenAI 后端。要启用它,只需设置你的 OpenAI API 密钥和组织 ID。
from skllm.config import SKLLMConfigSKLLMConfig.set_openai_key("<YOUR_KEY>")
SKLLMConfig.set_openai_org("<YOUR_ORGANIZATION_ID>")还可以通过 Azure OpenAI 服务访问 OpenAI 模型。要使用 Azure 后端,请提供你的 Azure API 密钥和终结点。
from skllm.config import SKLLMConfig
# Found under: Resource Management (Left Sidebar) -> Keys and Endpoint -> KEY 1
SKLLMConfig.set_gpt_key("<YOUR_KEY>")
# Found under: Resource Management (Left Sidebar) -> Keys and Endpoint -> Endpoint
SKLLMConfig.set_azure_api_base("<API_BASE>") # e.g. https://<YOUR_PROJECT_NAME>.openai.azure.com/使用 Azure 后端时,应将模型指定为 model ="azure::<model_deployment_name>"。例如,如果我们以名称 my-model 创建了 gpt-3.5 部署,则应使用 model ="azure::my-model"。
2.1 GGUF
GGUF 是一种用于存储量化模型权重和配置的开源格式。它主要用于 Llama CPP 项目,但也可以由其他运行时加载。要将 GGUF 模型与 scikit-llm 一起使用,请安装 llama-cpp 库及其 Python 绑定,安装命令因硬件而异。
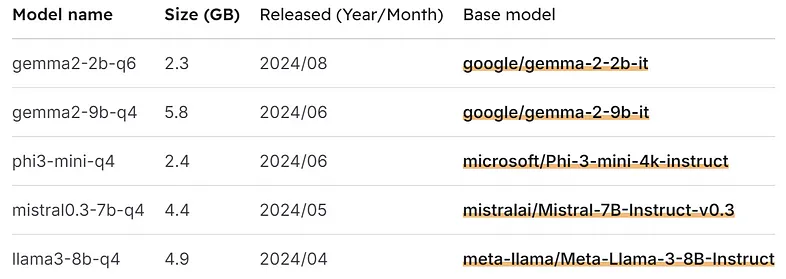
所有模型均使用量化版本,精度通过后缀表示(例如,q4 表示 4 位)。默认情况下,使用 4 位量化模型,但可能提供具有不同精度的模型。选择模型时,请考虑以下经验法则:
- q < 4:性能损失显著,尺寸较小
- q = 4:损失与尺寸之间的最佳平衡
- 4 < q < 8:性能损失最小,尺寸较大
- q = 8:几乎没有性能损失,尺寸非常大
2.2 GPU 加速
GGUF 模型可以全部或部分卸载到 GPU,使用命令设置最大 GPU 层数。
from skllm.config import SKLLMConfigSKLLMConfig.set_gguf_max_gpu_layers(-1)- 0:所有层都在 CPU 上
- -1:所有层都在 GPU 上
- n>0:n 层在 GPU 上,其余层在 CPU 上
请注意,更改此设置不会自动重新加载模型。要从内存中卸载模型,请使用以下命令:
from skllm.llm.gpt.clients.llama_cpp.handler import ModelCacheModelCache.clear()这在 Jupyter Notebook 等交互式环境中非常有用,因为模型会一直保留在内存中,直到流程结束。
2.3 自定义 URL
自定义 URL 后端支持使用任何 GPT 估算器和与 OpenAI 兼容的提供商,无论是本地还是基于云。设置全局自定义 URL 以使用此后端。
from skllm.config import SKLLMConfigSKLLMConfig.set_gpt_url("http://localhost:8000/")clf = ZeroShotGPTClassifier(model="custom_url::<custom_model_name>")注意,如果在同一脚本中同时使用自定义 URL 和 OpenAI 后端,请使用 SKLLMConfig.reset_gpt_url() 重置自定义 URL 配置。
3、Vertex 系列
Vertex 系列有一个后端,即 Google Vertex AI。要使用它,请配置你的 Google Cloud 凭据:
- 在 Google Cloud Console 中创建一个 Google Cloud 项目。
- 从列表中选择该项目。
- 搜索并选择 Vertex AI。
- 安装 Google Cloud CLI 并使用官方文档中的命令设置默认凭据。
gcloud auth application-default login- 使用你的项目 ID 配置 Scikit-LLM:
from skllm.config import SKLLMConfigSKLLMConfig.set_google_project("<YOUR_PROJECT_ID>")要在 Vertex 中调整 LLM,需要 64 个 TPU v3 pod 核心,默认值为 0。要增加此配额:
- 转到配额并过滤“每个区域受限的图像训练 TPU V3 pod 核心”。
- 选择“europe-west4”区域。
- 单击“编辑配额”,将限制设置为 64,然后提交请求。批准可能需要几小时到几天的时间。
4、文本分类
Scikit-LLM支持零样本、小样本、动态小样本、思维链等多种方式的文本分类。
4.1 零样本文本分类
LLM 的一个关键特性是,只要标签具有描述性,它们就可以对文本进行分类而无需重新训练。例如,要将文本分类为 [正面、负面、中性] 等类别,我们可以将 ZeroShotGPTClassifier 与常规 scikit-learn API 结合使用。
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
from skllm.datasets import get_classification_dataset# demo sentiment analysis dataset
# labels: positive, negative, neutral
X, y = get_classification_dataset()clf = ZeroShotGPTClassifier(model="gpt-3.5-turbo")
clf.fit(X,y)
labels = clf.predict(X)在零样本(zero-shot)设置中,不需要训练数据;你只需提供候选标签列表:
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
from skllm.datasets import get_classification_datasetX, _ = get_classification_dataset()clf = ZeroShotGPTClassifier()
clf.fit(None, ["positive", "negative", "neutral"])
labels = clf.predict(X)你还可以执行多标签分类,为单个文本分配多个标签:
from skllm.models.gpt.classification.zero_shot import MultiLabelZeroShotGPTClassifier
from skllm.datasets import get_multilabel_classification_datasetX, _ = get_multilabel_classification_dataset()
candidate_labels = ["Quality","Price","Delivery","Service","Product Variety","Customer Support","Packaging","User Experience","Return Policy","Product Information",
]
clf = MultiLabelZeroShotGPTClassifier(max_labels=3)
clf.fit(None, [candidate_labels])
labels = clf.predict(X)注意:零样本分类器的性能在很大程度上取决于标签的描述性和清晰度。例如,不要使用“语义”,而要使用更自然的短语,如“所提供文本的语义是<<语义>>”。
API 参考:
# Zero Shot GPT Classifier
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier# Multi Label Zero Shot GPT Classifier
from skllm.models.gpt.classification.zero_shot import MultiLabelZeroShotGPTClassifer# Zero Shot Vertex Classifier
from skllm.models.vertex.classification.zero_shot import ZeroShotVertexClassifier# Multi Label Zero Shot Vertex Classifier
from skllm.models.vertex.classification.zero_shot import MultiLabelZeroShotVertexClassif4.2 小样本文本分类
小样本(few-shot)文本分类涉及根据每个类别的几个示例将文本分类为预定义类别(例如,正面、负面、中性)。Scikit-LLM 估算器使用整个训练集来创建示例,因此如果您的数据集很大,请考虑将其拆分为较小的训练和验证集。建议每个类别保留不超过 10 个示例,并对数据进行混洗以避免近期偏差。
from skllm.models.gpt.classification.few_shot import (
FewShotGPTClassifier,
MultiLabelFewShotGPTClassifier,
)
from skllm.datasets import (get_classification_dataset,get_multilabel_classification_dataset,
)# single label
X, y = get_classification_dataset()
clf = FewShotGPTClassifier(model="gpt-4o")
clf.fit(X,y)
labels = clf.predict(X)# multi-label
X, y = get_multilabel_classification_dataset()
clf = MultiLabelFewShotGPTClassifier(max_labels=2, model="gpt-4o")
clf.fit(X,y)
labels = clf.predict(X)API参考:
# Few Shot GPT Classifier
from skllm.models.gpt.classification.few_shot import FewShotGPTClassifier# Multi Label Few Shot GPT
from skllm.models.gpt.classification.few_shot import MultiLabelFewShotGPTClassifier4.3 动态小样本文本分类
动态小样本(dynamic few-shot)分类扩展了少量样本文本分类,使其更适合处理较大的数据集。它不使用固定的示例集,而是动态地为每个样本选择一个子集,从而优化模型的上下文窗口并保存标记。
例如,如果目标是将评论分类为关于书籍或电影,则训练集可能包含 6 个样本,每个类别 3 个。
X = ["I love reading science fiction novels, they transport me to other worlds.", # example 1 - book - sci-fi"A good mystery novel keeps me guessing until the very end.", # example 2 - book - mystery"Historical novels give me a sense of different times and places.", # example 3 - book - historical"I love watching science fiction movies, they transport me to other galaxies.", # example 4 - movie - sci-fi"A good mystery movie keeps me on the edge of my seat.", # example 5 - movie - mystery"Historical movies offer a glimpse into the past.", # example 6 - movie - historical
]y = ["books", "books", "books", "movies", "movies", "movies"]现在我们需要对这条评论进行分类,“我深深地爱上了这本科幻小说;它独特的科学与虚构的融合让我着迷。”由于查询是关于科幻小说的,我们希望使用最相关的示例 1 和 4 进行分类。当使用每个类别 1 个示例的动态少样本分类器时,模型正确地选择示例 1 和 4 作为最相关的示例。
from skllm.models.gpt.classification.few_shot import DynamicFewShotGPTClassifierquery = "I have fallen deeply in love with this sci-fi book; its unique blend of science and fiction has me spellbound."clf = DynamicFewShotGPTClassifier(n_examples=1).fit(X,y)prompt = clf._get_prompt(query)
print(prompt)输出如下:
...Sample input:
"I love reading science fiction novels, they transport me to other worlds."Sample target: booksSample input:
"I love watching science fiction movies, they transport me to other galaxies."Sample target: movies...此过程使用 KNN 搜索算法作为预处理器。首先,使用嵌入模型对训练集进行矢量化。然后,使用 Scikit-Learn KNN 或 Annoy 等算法构建最近邻索引,以高效查找相关示例。为了确保类别平衡,训练数据按类别划分,允许在少样本提示期间从每个类别中平等采样 N 个示例。
API 参考:
# Dynamic Few Shot GPT Classifier
from skllm.models.gpt.classification.few_shot import DynamicFewShotGPTClassifier4.4 思维链文本分类
思维链(chain of thought)文本分类与零样本分类类似,但该模型还会生成标签选择背后的推理。这可以提高性能,但会增加 token 消耗。
from skllm.models.gpt.classification.zero_shot import CoTGPTClassifier
from skllm.datasets import get_classification_dataset# demo sentiment analysis dataset
# labels: positive, negative, neutral
X, y = get_classification_dataset()clf = CoTGPTClassifier(model="gpt-4o")
clf.fit(X,y)
predictions = clf.predict(X)
labels, reasoning = predictions[:, 0], predictions[:, 1]API参考:
# CoT GPT Classifier
from skllm.models.gpt.classification.zero_shot import CoTGPTClassifier4.5 可调文本分类
可调估算器(tunable estimator)可让你微调底层 LLM 以完成分类任务,这些任务通常在云端执行(如 OpenAI 或 Vertex),因此无需本地 GPU。但是,调整可能既昂贵又耗时。建议首先尝试上下文学习估算器,并且仅在必要时使用可调估算器。
from skllm.models.gpt.classification.tunable import GPTClassifierX, y = get_classification_dataset()
clf = GPTClassifier(n_epochs=1)
clf.fit(X,y)
clf.predict(X)API参考:
# GPT Classifier
from skllm.models.gpt.classification.tunable import GPTClassifier# Multi Label GPT Classifier
from skllm.models.gpt.classification.tunable import MultiLabelGPTClassifier# Vertex Classifier
from skllm.models.vertex.classification.tunable import VertexClassifier5、文本到文本建模
包括文本摘要等
5.1 文本摘要
LLM 非常适合摘要任务。Scikit-LLM 提供了一个摘要器,可以用作独立的估计器或预处理器,类似于降维。
from skllm.models.gpt.text2text.summarization import GPTSummarizer
from skllm.datasets import get_summarization_datasetX = get_summarization_dataset()
summarizer = GPTSummarizer(model="gpt-3.5-turbo", max_words=15)
X_summarized = summarizer.fit_transform(X)max_words 超参数设置了字数的软限制,但实际数量可能略微超过此限制。您还可以使用可选的 focus 参数生成专注于特定概念的摘要。
summarizer = GPTSummarizer(model="gpt-3.5-turbo", max_words=15, focus="apples")API参考:
# GPT Summarizer
from skllm.models.gpt.text2text.summarization import GPTSummarizer5.2 文本翻译
LLM 擅长翻译任务。Scikit-LLM 包含一个 Translator 模块,用于将文本翻译成目标语言。
from skllm.models.gpt.text2text.translation import GPTTranslator
from skllm.datasets import get_translation_datasetX = get_translation_dataset()
t = GPTTranslator(model="gpt-3.5-turbo", output_language="English")
translated_text = t.fit_transform(X)API参考:
# GPT Translator
from skllm.models.gpt.text2text.translation import GPTTranslator5.3 可调文本转文本
可调文本转文本估算器可针对摘要、问答和翻译等任务进行定制。它们按原样使用数据,无需额外的预处理或提示构造,因此用户必须确保数据格式正确。
from skllm.models.gpt.text2text.tunable import TunableGPTText2Textmodel = TunableGPTText2Text(base_model = "gpt-3.5-turbo-0613",n_epochs = None, # int or None. When None, will be determined automatically by OpenAIsystem_msg = "You are a text processing model."
)model.fit(X_train, y_train) # y_train is any desired output text
out = model.transform(X_test)API参考:
# unable GPT Text2Text
from skllm.models.gpt.text2text.tunable import TunableGPTText2Text# Tunable Vertex Text2Text
from skllm.models.vertex.text2text.tunable import TunableVertexText2Text6、其他任务
Scikit-LLM支持的其他任务包括
6.1文本矢量化
LLM 可以通过将文本转换为固定维度的向量来预处理数据,然后可以将其用于各种模型(例如分类、回归、聚类)。
# Embedding the text
from skllm.models.gpt.vectorization import GPTVectorizervectorizer = GPTVectorizer(batch_size=2)
X = vectorizer.fit_transform(["This is a text", "This is another text"])# Combining the vectorizer with the XGBoost classifier in a sklearn pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifierle = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)steps = [("GPT", GPTVectorizer()), ("Clf", XGBClassifier())]
clf = Pipeline(steps)
clf.fit(X_train, y_train_encoded)
yh = clf.predict(X_test)API参考:
# GPT Vectorizer
from skllm.models.gpt.vectorization import GPTVectorizer6.2 标记
Scikit-LLM 中的标记可以是一项任意任务,它获取原始文本并返回带有插入的类似 XML 的标记的相同文本。
# Input
I love my new phone, but I am disappointed with the battery life.# Output
<positive>I love my new phone,</positive> <negative>but I am disappointed with the battery life.</negative>在理想情况下,这种标记过程应该是可逆的,因此始终可以从标记文本中重建原始文本。但是,这并不总是可行的,因此不被视为强制性要求。
6.3 命名实体识别
NER 是 Scikit-LLM 中的一项实验性功能,可能不稳定。NER 涉及在文本中定位和分类命名实体。目前,Scikit-LLM 提供了一个 NER 估计器“可解释 NER”,仅适用于 GPT 系列。
from skllm.models.gpt.tagging.ner import GPTExplainableNER as NERentities = {"PERSON": "A name of an individual.","ORGANIZATION": "A name of a company.","DATE": "A specific time reference."
}data = ["Tim Cook announced new Apple products in San Francisco on June 3, 2022.","Elon Musk visited the Tesla factory in Austin on January 10, 2021.","Mark Zuckerberg introduced Facebook Metaverse in Silicon Valley on May 5, 2023."
]ner = NER(entities=entities, display_predictions=True)
tagged = ner.fit_transform(data)该模型会标记实体并为每个实体提供简要的推理。如果将 display_predictions 设置为 True,则会自动解析输出并以可读格式显示:突出显示实体,并将鼠标悬停在实体上时显示解释。
生成 NER 预测有两种模式:稀疏和密集。
密集模式:立即生成完全标记的输出。在使用较大的模型(例如 GPT-4)或文本中有多个词汇歧义词实例时很有用。例如,区分句子“Apple 是 Apple 首席执行官最喜欢的水果”中“Apple”的不同实例。
稀疏模式:生成通过正则表达式映射到文本的实体列表。它通常是首选,因为:
- 输出标记更少(具有成本效益)。
- 保证可逆性和特定于实体的输出。
- 较小模型的准确率更高。
通常建议使用稀疏模式,除非特定条件下需要密集模式。
API 参考:
# GPT ExplainableNER
from skllm.models.gpt.tagging.ner import GPTExplainableNER7、结束语
Scikit-LLM 通过集成用于各种 NLP 任务(包括文本分类、摘要和翻译)的高级语言模型来增强 scikit-learn。它支持零样本和少样本学习、动态示例选择和可自定义的后端。
虽然它提供了灵活性和效率,但用户应该考虑潜在的成本和性能影响,尤其是动态和可调功能。总体而言,Scikit-LLM 是一种将最先进的语言模型纳入机器学习工作流程的强大工具。
原文链接:Scikit-LLM - BimAnt