
需要Stable Diffusion整合包可以扫描下方,免费获取

01
引言
这是我在学习StableDiffusion (稳定扩散模型 简称SD)的第一篇入门文章,主要用于介绍稳定扩散模型和该领域的其他研究。在本文中,我想简要介绍一下如何使用Diffusers 扩散库,来创建自己生成图像。下一篇文章,我们将深入研究这个库的各级组件。
闲话少说,我们直接开始吧!
02
*SD功能介绍*
简单来说,稳定扩散模型是一种可以在给定文本提示词的情况下生成图像的深度学习模型。将其进行抽象,其主要实现的功能如下:
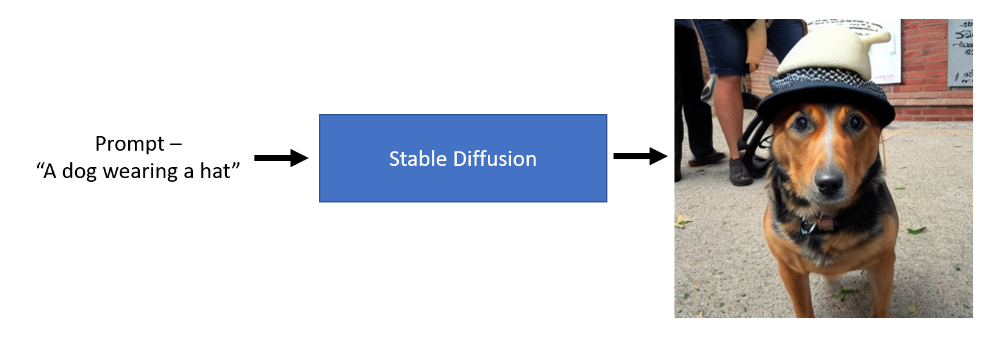
正如我们从上面的图像中看到的那样,我们可以传递一个输入的文本提示,如“戴帽子的狗”,此时稳定的扩散模型可以生成代表文本语义的图像。是不是很神奇?
03
*准备工作*
在开始之前,我们首先来安装我们必要的python库,使用以下命令进行安装:
pip install --upgrade diffusers transformers
如果联网环境下,一般使用huggingface_hub来在线下载相应的模型权重,考虑到受限于网络原因、,加之这些生成式模型又多又大,不绿色上网的话,速度超级感人,不得不吐槽下。基于上述原因,建议将其下载到本地进行操作,同时推荐一个国内的镜像源网站,速度嘎嘎快,网址链接:
https://hf-mirror.com/
这里我们下载模型 CompVis/stable-diffusion-v1-4 ,如下:
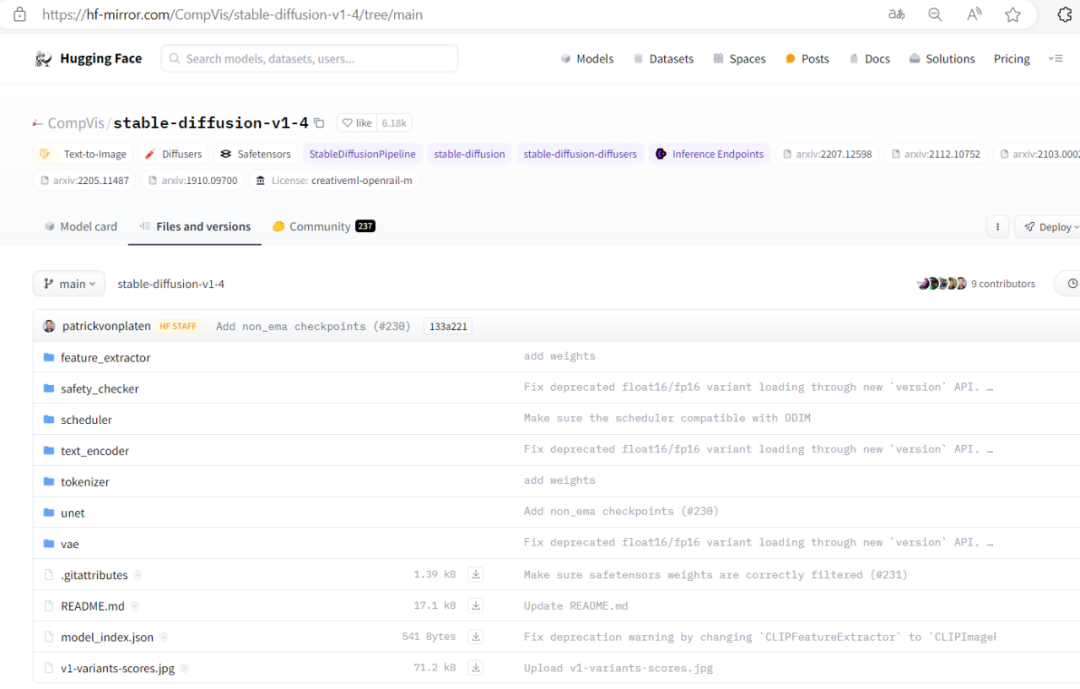
下载上述文件到本地任意目录即可,当然也可以下载最火的runwayml/stable-diffusion-v1-5,原理类似,不在累述。
04
*运行DEMO*
首先第一步工作就是从Diffusers 库中,导入我们文生图的Pipeline,代码如下:
from diffusers import StableDiffusionPipeline
接下来我们来初始化我们的Pipeline。由于之前我们已经将模型从线上服务器下载到本地机器。此时我们需要一台GPU机器来能运行以下初始化代码。
sd_path = r'/media/stable_diffusion/CompVis/stable-diffusion-v1-4'pipe = StableDiffusionPipeline.from_pretrained(sd_path, local_files_only=True, torch_dtype=torch.float16).to('cuda')
由于我们是加载本地模型,所以我们将参数local_files_only设置为True。代码如下:
prompt = 'a dog wearing hat'img = pipe(prompt).images[0]plt.imshow(img)plt.show()
得到结果如下:

可以看到,生成的图像还是很逼真的。
05
*总结*
**
**
本文重点介绍了StableDiffusion的相关功能介绍以及如何使用diffusers库来进行相应的文生图的实现,同时介绍了如何离线跑SD模型。在接下来的文章里,我们会将重点放在将SD模型拆成各个组件,来依次介绍每个组件的核心原理和具体功能。
嗯嗯,您学废了嘛?
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】







