Spark与Iceberg集成落地实践(一)
文章目录
- Spark与Iceberg集成落地实践(一)
- 清理快照与元数据
- 配置表维度自动清理元数据文件属性
- SPARK DDL语句
- 作用
- 手动清理
- 清理孤岛文件
- 合并数据文件
- 可用配置
- rewriteDataFiles核心类图
清理快照与元数据
配置表维度自动清理元数据文件属性
快照默认保留5天,最少保留一个版本
history.expire.max-snapshot-age-ms : 432000000, 5天,快照过期时,在表及其所有分支上保留快照的默认最大时间
history.expire.min-snapshots-to-keep: 1 在快照过期时,在表及其所有分支上保留快照的默认最小数量
每一次写入数据和表变更都会进行一次元数据的版本迭代,默认保存所有。
| Property | Description |
|---|---|
write.metadata.delete-after-commit.enabled | 每次表提交后是否删除旧的跟踪的元数据文件 |
write.metadata.previous-versions-max | 要保留的旧元数据文件的数量 |
SPARK DDL语句
建表时确认metadata生命周期
sparkSession.sql("CREATE TABLE local.iceberg_db.table2( id bigint, data string, ts timestamp) USING iceberg PARTITIONED BY (day(ts)) TBLPROPERTIES('write.metadata.delete-after-commit.enabled'='true','write.metadata.previous-versions-max'='3')");
更改表的metadata生命周期
sparkSession.sql("ALTER TABLE local.iceberg_db.table2 SET TBLPROPERTIES(" +"'write.metadata.delete-after-commit.enabled'='true'," +"'write.metadata.previous-versions-max'='3'" +")");
作用
这只会删除元数据日志中跟踪的元数据文件,而不会删除孤立的元数据文件。
清理从metadata.json链路开始的至data的所有文件,如下图:
手动清理
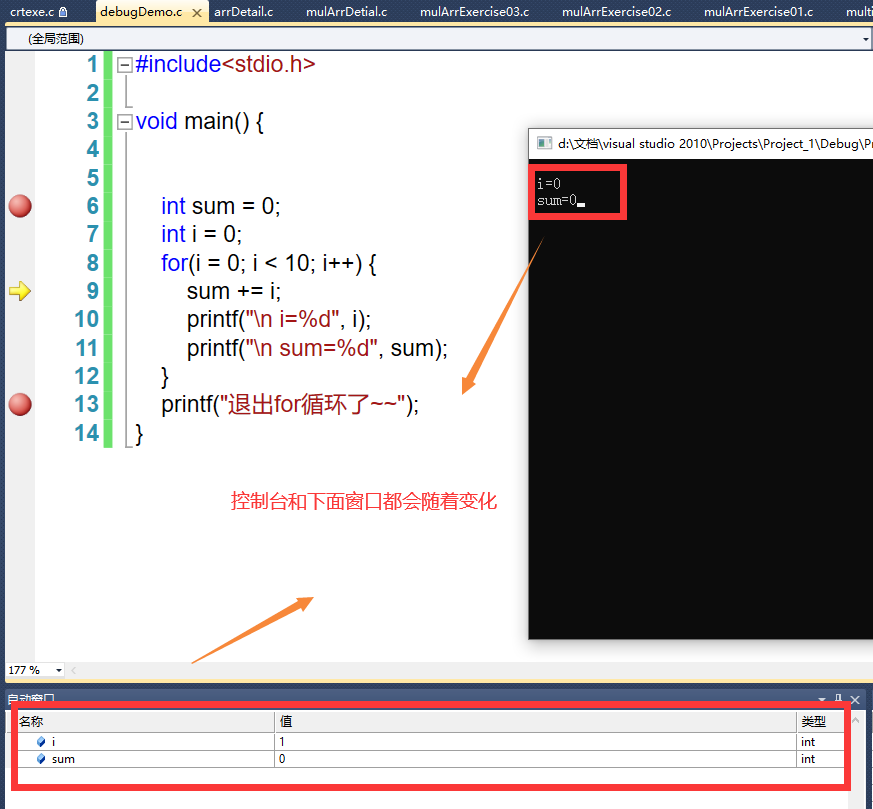
org.apache.iceberg.Table table = org.apache.iceberg.spark.Spark3Util.loadIcebergTable(spark, "local.iceberg_db.table2");long tsToExpire = System.currentTimeMillis() - (1000 * 60 * 60 * 24); // 保留一天org.apache.iceberg.spark.actions.SparkActions.get().expireSnapshots(table).expireOlderThan(tsToExpire).execute();
清理孤岛文件
孤岛文件的产生:
在 Spark 和其他分布式处理引擎中,任务或作业失败可能会留下未被表元数据引用的文件,在某些情况下,正常快照过期可能无法确定文件不再需要并将其删除。任务失败之后,最好进行一次清理表孤岛文件,若表相关任务成功,则不需要进行清理孤岛文件操作。
org.apache.iceberg.Table table = org.apache.iceberg.spark.Spark3Util.loadIcebergTable(spark, "local.iceberg_db.table2");org.apache.iceberg.spark.actions.SparkActions.get().deleteOrphanFiles(table).execute();
合并数据文件
尝试调用rewriteDataFiles进行文件合并。
org.apache.iceberg.Table table = org.apache.iceberg.spark.Spark3Util.loadIcebergTable(spark, "local.iceberg_db.table2");org.apache.iceberg.spark.actions.SparkActions.get().rewriteDataFiles(table).execute();
执行后,实验中的分区中的小文件并没有合并。对于存在小文件的分区并没有进行合并,像这种分区类的小文件实在是太小KB级别的,直接可以配置rewrite-all为true。进行文件合并。合并后,之前的小文件还是存在的,其会根据快照保存逻辑,需要在快照迭代中进行删除。如果需要立即清理,则需要变更快照与源文件清理规则。
SparkActions.get().rewriteDataFiles(table).option("rewrite-all", Boolean.toString(true)).execute();
可用配置
org.apache.iceberg.actions.RewriteDataFiles中发现配置项:
-
partial-progress.enabled是否启用分步提交,默认值
false。启用在整个重写完成前提交文件组(参考
max-file-group-size-bytes)。这将产生额外的提交,但即使某些文件组未能提交,也能取得进展。此设置不会改变重写操作的正确性,因为文件组可以独立压缩。
默认值为 false,即在整个作业完成后产生一次提交。 -
partial-progress.max-commits默认值
10在启用部分进度的情况下,允许此重写产生的最大 Iceberg 提交次数。如果禁用了
partial-progress,则此设置无效。 -
partial-progress.max-failed-commits如果启用了部分进度,此重写允许的最大失败提交次数。默认情况下,允许所有提交失败。如果禁用了部分进度,则此设置无效。
-
max-file-group-size-bytes默认值
1024L * 1024L * 1024L * 100L, 意为100GB整个重写操作根据分区分成若干块,并在分区内根据大小分成若干组。这些重写的子单元被称为文件组。单个组中应压缩的最大数据量由
MAX_FILE_GROUP_SIZE_BYTES控制。这有助于分解超大分区的重写,否则由于集群资源限制,这些分区可能无法重写。例如,基于排序的重写可能无法扩展到 TB 大小的分区,这些分区需要分小节处理,以避免资源耗尽。
在对文件进行分组时,底层重写策略将使用该值来限制单个文件组中包含的文件。一个文件组将由一个框架 “action”处理。例如,在 Spark 中,这意味着每个文件组都将在自己的 Spark 操作中进行重写。一个文件组绝不会包含多个输出分区的文件。
-
max-concurrent-file-group-rewrites默认值
5重写时,可以同时重写的文件组的最大数量。文件组的结构和内容由重写策略决定。每个文件组都将以异步方式独立重写。
-
target-file-size-bytes重写文件时,此重写策略将控制生成的输出文件大小。默认情况下,这将使用被更新表的表属性中
write.target-file-size-bytes的值。 -
use-starting-sequence-number默认值
true对于新数据文件,压缩是否应使用压缩开始时快照的序列号,而不是使用新生成快照的序列号。
这样可以避免与在较高序列号上添加较新平等删除的更新发生提交冲突。
-
rewrite-job-order默认值
none。取值范围,none,bytes-asc,bytes-desc,files-asc,files-desc。强制重写作业顺序:
- 如果 rewrite-job-order=bytes-asc,则先重写最小的作业组。
- 如果 rewrite-job-order=bytes-desc,则先重写最大的作业组。
- 如果 rewrite-job-order=files-asc,则先重写文件最少的作业组。
- 如果 rewrite-job-order=files-desc,则先重写文件数最多的作业组。
- 如果 rewrite-job-order=none,则按计划顺序重写作业组(无特定顺序)。
-
output-spec-id默认为当前表规范。用于重写文件的分区规范 ID 。
用于文件重写器在重写操作中识别特定的输出分区规范。数据将在重写过程中进行重组,以便与输出分区保持一致。
org.apache.iceberg.actions.SizeBasedFileRewriter中支持的配置项:
target-file-size-bytes:此文件重写器将尝试控制生成的输出文件的大小。默认取write.target-file-size-bytes的值。默认值512 * 1024 * 1024min-file-size-bytes:控制将考虑重写哪些文件。大小低于此阈值的文件将被考虑重写,而不考虑任何其他标准。如果不主动配置此项,则值为target-file-size-bytes的75%。max-file-size-bytes:控制将考虑重写哪些文件。大小超过此阈值的文件将被考虑重写,而不考虑任何其他标准。
默认为target-file-size-bytes的180%。min-input-files:默认值5。任何超过这个数目的文件组都将被重写,不管其他标准如何。此配置确保包含许多文件的文件组被压缩,即使该组的总大小小于目标文件大小。这也可以被认为是重写分区后可能保留的错误大小文件的最大数量。rewrite-all:覆盖其他选项并强制重写所有提供的文件。默认值false。max-file-group-size-bytes:此选项控制在单个文件组中应重写的最大数据量。默认值100L * 1024 * 1024 * 1024,此为100GB。