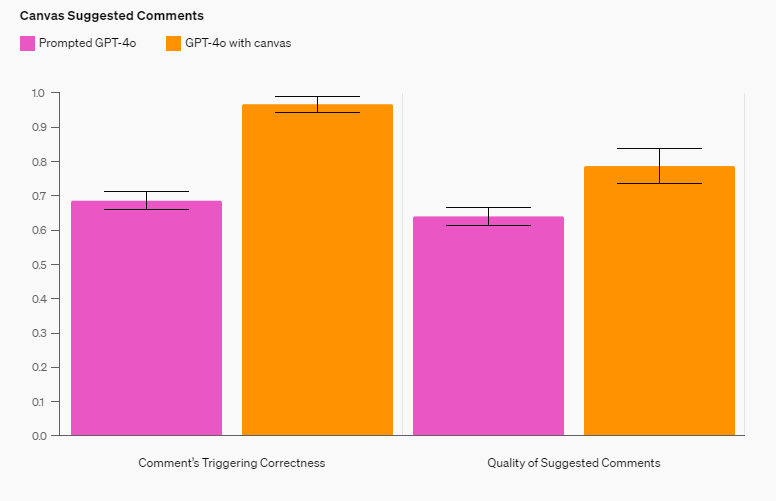
好的,为了编写一篇全面且详细的指南,涵盖 PyTorch 中张量的所有知识,并为学习机器学习和深度学习打好基础,我将会提供一个结构化的内容,包括基础知识、进阶知识、实际应用和一些优化技巧。这个文档大纲如下:
- 引言
- 张量的基础知识
- 张量的概念
- 张量的属性
- 张量的创建
- 张量的操作
- 基本运算
- 索引和切片
- 形状变换
- 自动微分
- 基本概念
- 停止梯度传播
- 张量的设备管理
- 检查和移动张量
- CUDA 张量
- 高级操作
- 张量的视图
- 广播机制
- 分块和拼接
- 张量的复制
- 内存优化和管理
- 稀疏张量
- 内存释放
- 应用实例
- 线性回归
- 神经网络基础
- 总结
1. 引言
在机器学习和深度学习中,张量(Tensor)是核心的数据结构。了解和掌握张量的操作是学习 PyTorch 和构建神经网络模型的必要基础。张量可以表示从标量到高维数组的数据结构,它在 PyTorch 的计算图中扮演着基础角色。本指南旨在全面介绍 PyTorch 中张量的相关知识,帮助读者从基础打好深度学习的基础。
2. 张量的基础知识
1. 张量的概念
张量是一个数组的通用化,可以表示标量(0维)、向量(1维)、矩阵(2维)及更高维的数组。通俗来说,张量是一种多维数据结构,其本质上是一个多维数组。
2. 张量的属性
张量有多个重要属性,用来描述其数据和结构:
- 形状(shape):描述张量的维度结构,例如
(2, 3)表示一个包含 2 行 3 列的矩阵。 - 数据类型(dtype):指定张量中元素的类型,例如
torch.float32,torch.int64等。 - 设备(device):指示张量存储的设备,可以是 CPU 或 GPU。
- 步幅(stride):步幅表示连续两个元素在各个维度上的步进距离。
import torchtensor = torch.tensor([[1., 2., 3.], [4., 5., 6.]])print(tensor.shape) # torch.Size([2, 3])
print(tensor.dtype) # torch.float32
print(tensor.device) # cpu
print(tensor.stride()) # (3, 1)
3. 张量的创建
可以通过多种方式创建张量,包括从已有数据创建、使用随机数生成和从其他张量创建。
# 从数据创建
scalar = torch.tensor(5.0) # 标量
vector = torch.tensor([1.0, 2.0, 3.0]) # 向量
matrix = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) # 矩阵# 使用随机数创建
rand_tensor = torch.rand(2, 3) # 均匀分布
randn_tensor = torch.randn(2, 3) # 标准正态分布# 从其他张量创建
zeros_tensor = torch.zeros_like(matrix) # 创建与 matrix 形状相同的全零张量
3. 张量的操作
1. 基本运算
张量支持基本的算术运算,包括加、减、乘、除。
a = torch.tensor([1.0, 2.0, 3.0])
b = torch.tensor([4.0, 5.0, 6.0])# 加法
c = a + b# 减法
d = a - b# 乘法
e = a * b# 除法
f = a / b# 点积
dot_prod = torch.dot(a, b) # 32.0# 矩阵乘法
matrix1 = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
matrix2 = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
matrix_mul = torch.mm(matrix1, matrix2) # [[19.0, 22.0], [43.0, 50.0]]
2. 索引和切片
张量支持多种索引和切片操作,类似于 NumPy。
tensor = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])# 索引
element = tensor[1, 2] # 6.0# 切片
subset = tensor[:, 1] # tensor([2.0, 5.0])
3. 形状变换
在不复制数据的情况下,PyTorch 支持多种形状变换操作。
# 重塑
reshaped = tensor.view(3, 2) # tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])# 转置
transposed = tensor.t() # tensor([[1.0, 4.0], [2.0, 5.0], [3.0, 6.0]])# 增加或减少维度
unsqueezed = tensor.unsqueeze(0) # 增加第0维
squeezed = tensor.squeeze() # 去除所有维度为1的维度
4. 自动微分
PyTorch 提供强大的自动微分功能,称为Autograd。它可以自动计算张量的梯度,适用于优化和训练神经网络。
1. 基本概念
张量可以设置 requires_grad=True 以启用自动微分。计算张量的梯度使用 backward() 方法。
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = x[0] ** 2 + x[1] ** 3
y.backward()
print(x.grad) # tensor([ 4.0, 27.0])
2. 停止梯度传播
在某些情况下,比如模型评估或推理时,需要停止梯度传播以提高性能并节省内存。
with torch.no_grad():y = x[0] ** 2 + x[1] ** 3# 使用 detach() 方法创建一个新的张量,该张量与原始张量共享数据,但不进行梯度追踪
detached_tensor = x.detach()
5. 张量的设备管理
1. 检查和移动张量
张量可以在 CPU 或 GPU 上进行计算。PyTorch 提供了简单的方法来检查和移动张量到不同的设备。
tensor = torch.tensor([1.0, 2.0, 3.0])# 检查是否有可用的 GPU
if torch.cuda.is_available():tensor = tensor.to('cuda')print(tensor.device) # cuda:0# 将张量移动回 CPU
tensor = tensor.to('cpu')
print(tensor.device) # cpu
2. CUDA 张量
使用 CUDA 张量可以显著提高计算速度,特别是在深度学习中。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tensor = torch.tensor([1.0, 2.0, 3.0], device=device)
6. 高级操作
1. 张量的视图
视图允许我们在不复制数据的情况下,改变张量的形状。
original_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
view_tensor = original_tensor.view(6) # tensor([1, 2, 3, 4, 5, 6])# 修改视图
view_tensor[0] = 10
print(original_tensor) # tensor([[10, 2, 3], [ 4, 5, 6]])
2. 广播机制
广播机制使得不同形状的张量能够进行相同大小的运算。
a = torch.tensor([1, 2, 3])
b = torch.tensor([[1], [2], [3]])
result = a + b
# result: tensor([[2, 3, 4],
# [3, 4, 5],
# [4, 5, 6]])
3. 分块和拼接
可以使用 split() 和 cat() 等函数进行分块和拼接。
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 分割张量
split_tensors = torch.split(tensor, split_size_or_sections=2, dim=1)# 拼接张量
tensor_a = torch.tensor([[1, 2], [3, 4]])
tensor_b = torch.tensor([[5, 6], [7, 8]])
concat_tensor = torch.cat((tensor_a, tensor_b), dim=1)
4. 张量的复制
用于创建独立副本,clone() 和 detach() 是常用方法。
tensor = torch.tensor([1, 2, 3], requires_grad=True)
cloned_tensor = tensor.clone()
detached_tensor = tensor.detach()
7. 内存优化和管理
1. 稀疏张量
对于稀疏矩阵和张量,PyTorch 提供了稀疏张量表示,以便节省内存和计算资源。
indices = torch.tensor([[0, 1, 1], [2, 0, 2]])
values = torch.tensor([3, 4, 5], dtype=torch.float32)
sparse_tensor = torch.sparse_coo_tensor(indices, values, [2, 3])
print(sparse_tensor)
2. 内存释放
为了在训练和评估期间节省内存,可以释放不再需要的张量。
# 使用 del 语句手动删除对象
del tensor# 清空 GPU 切实可行的张量以释放内存
torch.cuda.empty_cache()
8. 应用实例
通过实际应用实例,可以更好地理解和掌握 PyTorch 张量的使用方式。
1. 线性回归
利用 PyTorch 张量实现简单的线性回归模型。
# 数据集
x_train = torch.tensor([[1.0], [2.0], [3.0]])
y_train = torch.tensor([[2.0], [4.0], [6.0]])# 初始化参数
w = torch.randn(1, requires_grad=True)
b = torch.randn(1, requires_grad=True)def model(x):return w * x + b# 损失函数
def loss_fn(y_pred, y):return ((y_pred - y) ** 2).mean()# 训练模型
learning_rate = 0.01
for epoch in range(1000):y_pred = model(x_train)loss = loss_fn(y_pred, y_train)loss.backward()with torch.no_grad():w -= learning_rate * w.gradb -= learning_rate * b.gradw.grad.zero_()b.grad.zero_()print(f'w: {w}, b: {b}')
2. 神经网络基础
张量在神经网络中的应用,是构建复杂模型的基础。
import torch.nn as nn# 简单的神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(1, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 1)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return outmodel = SimpleNN()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(1000):y_pred = model(x_train)loss = criterion(y_pred, y_train)optimizer.zero_grad()loss.backward()optimizer.step()print(list(model.parameters()))