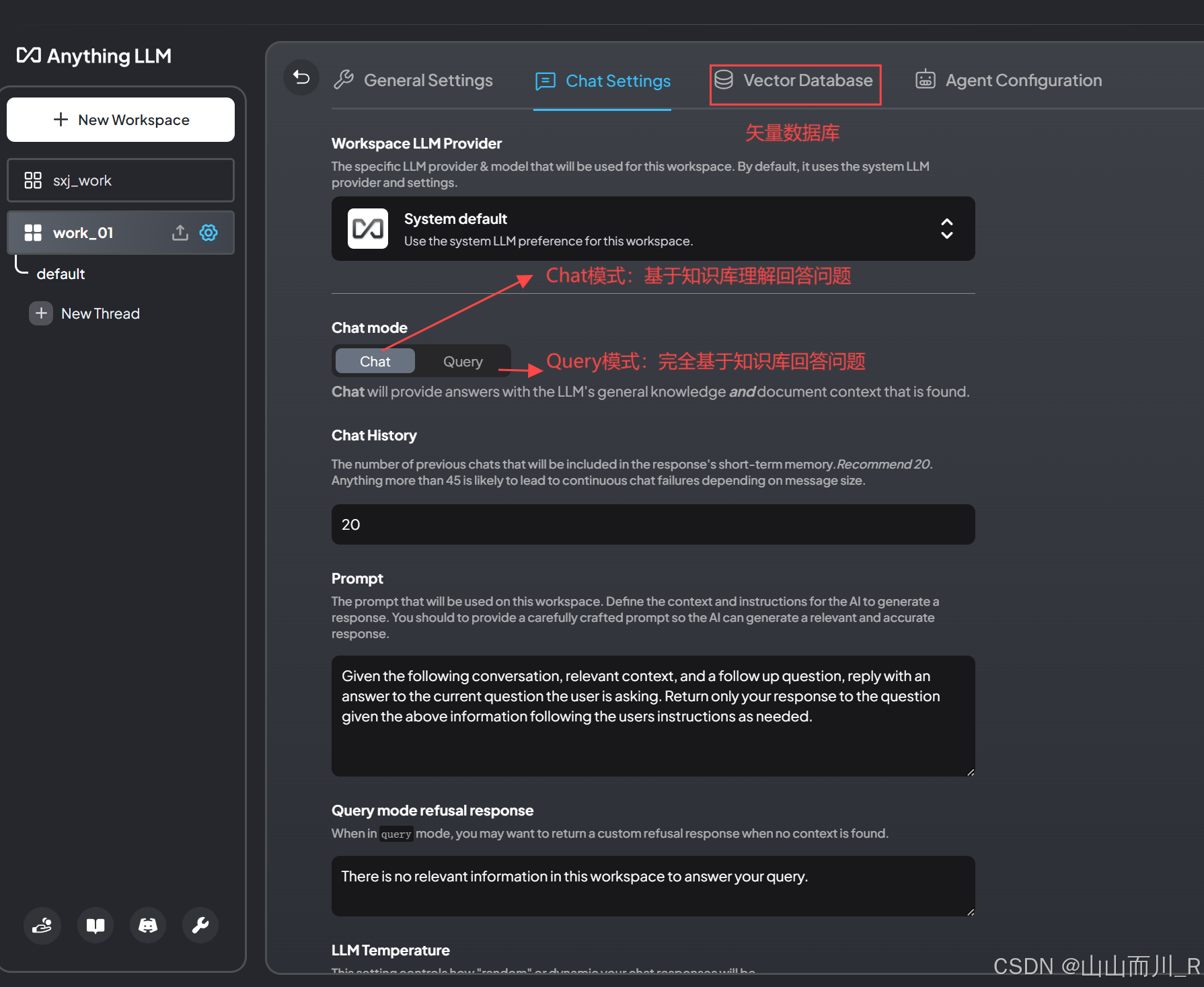
用Sklearn和Statsmodels来做linear_regression和Logistic_regression注意事项,区别。主要在于 intercept 项,和 regularization。
X = np.array([-1, 0, 1]) # 自变量
Y = np.array([-2, 0, 5]) # 因变量
一、Linear regression 的截距项
又叫 intercept, constant, bias
- 在使用 statsmodels 进行线性回归时,
(1) 通常需要手动添加常数项(即截距),因为 statsmodels 的 OLS 默认不包括截距。这可以通过使用 statsmodels.tools.add_constant 函数来实现。例如,如果你有一个因变量 y 和一个自变量 X,你可以这样添加常数项:
import statsmodels.api as smX = sm.add_constant(X) # 添加常数项
model = sm.OLS(Y, X).fit()
这样,X 中就会包含一个值全为 1 的列,它代表了截距项。在 statsmodels 中,add_constant 方法是添加常数项的标准做法 。
(2) 注意在计算 y_pred 时,必须要用 X_poly。建立方法如下:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
def my_use_linear_regres(X, Y): # 转换数据的形状X = X.reshape(-1, 1)# 创建一个PolynomialFeatures实例,degree指定多项式的度数poly = PolynomialFeatures(degree=1) # change this!!!!!!!!!!!!!!!# 转换XX_poly = poly.fit_transform(X)return X_poly
或者:
# 构建设计矩阵
# X_poly = np.vstack([np.ones(len(X)), X, X**2]).T # 对于二次多项式,我们需要添加X的平方项
X_poly = np.vstack([np.ones(len(X)), X]).T
print(X_poly)
X_poly = my_use_linear_regres(X, Y)
Y_pred = model_mine.predict(X_poly)
Y_pred
- 而在 scikit-learn 中,当你使用 LinearRegression 类时,
(1) 是否添加常数项(截距)是由类初始化时的 fit_intercept 参数决定的。如果 fit_intercept=True(默认值),则 scikit-learn 会自动为你的模型添加常数项:
from sklearn.linear_model import LinearRegression# 创建线性回归模型实例,自动添加常数项
model = LinearRegression(fit_intercept=True)
model.fit(X, y)
在这种情况下,你不需要手动添加常数项,因为 scikit-learn 已经为你处理了(我没试过) 。
或者,你自己加一个 X_poly:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
def my_use_linear_regres(X, Y): # 转换数据的形状X = X.reshape(-1, 1)# 创建一个PolynomialFeatures实例,degree指定多项式的度数poly = PolynomialFeatures(degree=1) # change this!!!!!!!!!!!!!!!# 转换XX_poly = poly.fit_transform(X)# 创建线性回归模型实例model = LinearRegression()# 拟合模型model.fit(X_poly, Y)return model
(2) 预测 y_pred 的时候,自己写式子。
二、Logistic Regression 的截距项和L2 Regularization
在进行逻辑回归时,scikit-learn 和 statsmodels 这两个库有一些关键的区别,特别是在截距项和正则化方面。
截距项
• scikit-learn:默认情况下,scikit-learn 的 LogisticRegression 类会添加一个截距项。如果你想显式地控制是否添加截距项,可以通过设置 fit_intercept 参数为 True 或 False 来实现。(别用它,它自动加一个 L2,不好控制。)
• statsmodels:
使用 smf.glm (广义线性模型)时,是默认自动加一个截距项的! Logistic regression 是 GLM 的特例,其中响应变量是二元的,并且遵循二项分布。链接函数通常是 logit 函数。
naive_model = smf.glm('default~student+balance+income', data=train_default, family=sm.families.Binomial()).fit()
print(naive_model.summary())

(别的:在 statsmodels 中,当你使用 Logit 函数时,默认情况下不会包括截距项。如果你需要包括截距项,需要在模型公式中显式地包含它,例如使用 “y ~ x1 + x2 + const” 这样的公式,其中 const 就是截距项。这是 AI 说的,我没用过。)
正则化
• scikit-learn:scikit-learn 的 LogisticRegression 类支持 L1 和 L2 正则化,这可以通过设置 penalty 参数为 ‘l1’ 或 ‘l2’ 来实现。L1 正则化可以导致稀疏解,而 L2 正则化则不会。正则化的强度可以通过 C 参数来控制,C 的值越小,正则化强度越大。
在 scikit-learn 的 LogisticRegression 类中,默认的正则化是 L2 正则化 。这意味着它会使用一个正则化项,即系数的平方和,来防止模型过拟合。L2 正则化有助于处理特征多重共线性问题,并能够使模型参数更加平滑。
默认情况下,LogisticRegression 的 penalty 参数设置为 ‘l2’,同时 solver 参数默认为 ‘lbfgs’,它是一种优化算法,用于找到损失函数的最小值。C 参数控制正则化的强度,其默认值是 1.0,较小的 C 值意味着更强的正则化(即更平滑的模型),而较大的 C 值则意味着更弱的正则化(允许模型更复杂)。fit_intercept 参数默认为 True,表示模型会包含截距项。
如果你希望使用 L1 正则化或者不使用正则化,可以通过调整 penalty 参数来实现。例如,设置 penalty=‘l1’ 可以应用 L1 正则化,而设置 penalty=‘none’ 则不使用正则化。不过需要注意的是,当使用 liblinear 求解器时,不支持不使用正则化的情况。
此外,LogisticRegression 还支持弹性网正则化(‘elasticnet’),它是 L1 和 L2 正则化的组合,通过 l1_ratio 参数来控制两者的比例。
• statsmodels:statsmodels 的逻辑回归实现默认情况下不包括正则化。如果你需要应用正则化,可能需要通过手动修改设计矩阵或使用其他方法来实现。
·
如果你需要更多的自动化和快速原型设计,scikit-learn 可能是更好的选择。而如果你需要更深入地了解模型的细节和定制,statsmodels 可能更适合你的需求。