目录
20.1 自动回归
20.2 自动分类
20.3 自动聚类
20.4 AutoARIMA
20.5 自动数据准备
【第二十章:Sentosa_DSML社区版-机器学习之自动建模】
20.1 自动回归
1.算子介绍
为了方便用户在不了解每个具体回归算法原理,及每个算法参数设置具体含义的情况下,仍能得到一个较优的回归模型。我们实现了一个自动回归算子。自动回归模型用户需要指定模型评价标准,然后利用自动调参来训练多个模型。得到排名靠前的几个模型,然后各个模型计算平均值决定最后回归结果。
2.算子类型
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| measure_type | 评价参数 | 单选 | String | mse | 单选,选择范围:[r2,mae,mse,rmse] | rmse:均方根 mse:均方误差 mae:平均绝对误差 r2:绝对系数R2((R-Square) |
| validation_mode | 验证模式 | 单选 | String | 固定划分 | 固定划分、交叉验证 | TrainValidationSplit: 固定划分,CrossValidator:交叉验证 |
| select_mode | 参数选择模式 | 单选 | String | 随机搜索 | 网格搜索、随机搜索、贝叶斯优化、粒子群算法、模拟退火、进化算法、TPE | GridSearch:网格搜索, RandomSearch:随机搜索, BayesianOptimization:贝叶斯优化 TPE,SimulateAnneal:模拟退火 |
| auto_ml_split_ratio | 训练集占比 | 输入 | Double | 0.7 | (0-1) | 验证模式为固定划分时有效:训练集占比 |
| auto_ml_num_folds | K | 输入 | Integer | 5 | >=1 | 验证模式为交叉验证时有效:交叉验证模式的K折 |
| auto_ml_iter | 迭代次数 | 输入 | Integer | 20 | >=1 | 参数选择模式为随机搜索和贝叶斯优化时有效:迭代次数 |
| top_n | 生成模型数 | 用户 输入 | Integer | 1 | >=1,<=最大分类算法个数 | "生成的所有模型中取前top_n个模型" |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| Calculate_actual_predicted_scatter_plot | 是否计算实际值-预测值散点图 | 必填 | Boolean | 否 | 单选:是,否 | 是否计算实际值-预测值散点图 |
| calculate_residual_histogram | 是否计算残差直方图 | 必填 | Boolean | 否 | 单选:是,否 | 是否计算残差直方图 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
自动回归的属性设置如图所示

自动回归属性设置示例
前端可配置属性如图所示,参数有:
1) 评价参数即算法的评价标准,回归评价标准有r2,mse, rmse, mae四种;
2) 验证模式,当选择固定划分时,会出来训练集占比选项,当选择交叉验证时,会出来K选项;
3) 参数选择模式,除网格搜索外,设置成其他任意模式都会出现迭代次数选项;
4) 选择回归算法,可以选择需要自动建模的算法,以及设置每个算法自动调参的参数

算法的属性设置示例
5) 提取模型个数,可以指定提取自动建模生成模型的前top_n的模型;
6) 是否计算特征重要性;
7) 是否计算实际值-预测值散点图;
8) 是否计算残差直方图;
9) 是否跳过空值。
(3)算子的运行
自动回归为自动建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接自动回归算子,右击算子,点击运行,得到自动分类模型。

运行自动回归算子获得自动分类模型示例
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

自动回归模型算子流示例
右击模型,查看模型的模型信息

自动回归模型信息示例
点击生成模型栏,可以查看生成的top_n的模型列表,并且可以查看模型的详细参数如图所示。

自动回归生成模型列表示例
点击对应模型,查看模型参数如图所示

生成模型的模型参数示例
输出的表格结果以及评估结果都是经过生成模型一起投票出来的结果如图

最终的输出结果示例

最终评估结果示例
20.2 自动分类
1.算子介绍
为了方便用户在不了解每个具体分类算法原理,及每个算法参数设置具体含义的情况下,仍能得到一个较优的分类模型。我们实现了一个自动分类算子。自动分类模型用户需要指定模型评价标准,然后利用自动调参来训练多个模型。得到排名靠前的几个模型,然后各个模型投票决定最后分类结果。
2.算子类型
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| measure_type | 评价参数 | 单选 | String | f1 | [f1,weightedPrecision,weightedRecall,accuracy] | f1: 基于召回率和精确率计算出来的F1- score, weightedPrecision:精确率,weightedRecall:召回率, accuracy:准确率 |
| validation_mode | 验证模式 | 单选 | String | 固定划分 | 固定划分,交叉验证 | TrainValidationSplit: 固定划分,CrossValidator:交叉验证 |
| select_mode | 参数选择模式 | 单选 | String | 随机搜索 | 网格搜索、随机搜索、贝叶斯优化、粒子群算法、模拟退火、进化算法、TPE | GridSearch:网格搜索, RandomSearch:随机搜索, BayesianOptimization:贝叶斯优化 TPE,SimulateAnneal:模拟退火 |
| auto_ml_split_ratio | 训练集占比 | 输入 | Double | 0.7 | (0-1) | 验证模式为固定划分时有效:训练集占比 |
| auto_ml_num_folds | K | 输入 | Integer | 5 | >=1 | 验证模式为交叉验证时有效:交叉验证模式的K折 |
| auto_ml_iter | 迭代次数 | 输入 | Integer | 20 | >=1 | 参数选择模式为随机搜索和贝叶斯优化时有效:迭代次数 |
| top_n | 生成模型数 | 用户 输入 | Integer | 1 | >=1,<=最大分类算法个数 | "生成的所有模型中取前top_n个模型" |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
自动分类的属性设置如图所示

自动分类属性设置示例
前端可配置属性如图所示,参数有:
1) 评价参数即算法的评价标准,分类评价标准有f1,weightedPrecision, weightedRecall, accuracy四种;
2) 验证模式,当选择固定划分时,会出来训练集占比选项,当选择交叉验证时,会出来K选项;
3) 参数选择模式,除网格搜索外,设置成其他任意模式都会出现迭代次数选项;
4) 选择分类算法,可以选择需要自动建模的算法,以及设置每个算法自动调参的参数

算法的属性设置示例
5) 提取模型个数,可以指定提取自动建模生成模型的前top_n的模型;
6) 是否计算特征重要性;
7) 是否显示训练数据的混淆矩阵。
(3)算子的运行
自动分类为自动建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接自动分类算子,右击算子,点击运行,得到自动分类模型。

运行自动分类算子获得自动分类模型示例
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

自动分类模型算子流示例
右击模型,查看模型的模型信息

自动分类模型信息示例
点击生成模型栏,可以查看生成的top_n的模型列表,并且可以查看模型的详细参数如图所示。

自动分类生成模型列表示例
点击对应模型,查看模型参数如图所示。

生成模型的模型参数示例
输出的表格结果以及评估结果都是经过生成模型一起投票出来的结果如图

最终的输出结果示例

最终评估结果示例
20.3 自动聚类
1.算子介绍
为了方便用户在不了解每个具体聚类算法原理,及每个算法参数设置具体含义的情况下,仍能得到一个较优的聚类模型,我们实现了一个自动聚类算子。
2.算子类型
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| measure_type | 评价参数 | 单选 | String | silhouette | [silhouette] | 评价参数-轮廓 |
| validation_mode | 验证模式 | 单选 | String | 固定划分 | 固定划分,交叉验证 | TrainValidationSplit: 固定划分,CrossValidator:交叉验证 |
| select_mode | 参数选择模式 | 单选 | String | 随机搜索 | 网格搜索、随机搜索、贝叶斯优化、粒子群算法、模拟退火、进化算法、TPE | GridSearch:网格搜索, RandomSearch:随机搜索, BayesianOptimization:贝叶斯优化 TPE,SimulateAnneal:模拟退火 |
| auto_ml_split_ratio | 训练集占比 | 输入 | Double | 0.7 | (0-1) | 验证模式为固定划分时有效:训练集占比 |
| auto_ml_num_folds | K | 输入 | Integer | 5 | >=1 | 验证模式为交叉验证时有效:交叉验证模式的K折 |
| auto_ml_iter | 迭代次数 | 输入 | Integer | 20 | >=1 | 参数选择模式为随机搜索和贝叶斯优化时有效:迭代次数 |
| top_n | 生成模型数 | 用户 输入 | Integer | 1 | >=1,<=最大聚类算法个数 | "生成的所有模型中取前top_n个模型" |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_pie_chart | 是否显示聚类大小饼状图 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示聚类大小饼状图 |
| show_distribution_mpa | 是否显示聚类分布图 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示聚类分布图 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
自动聚类的属性设置如图所示

自动聚类属性设置示例
前端可配置属性如图所示,参数有:
1) 评价参数即算法的评价标准,聚类评价标准为silhouette;
2) 验证模式,当选择固定划分时,会出来训练集占比选项,当选择交叉验证时,会出来K选项;
3) 参数选择模式,除网格搜索外,设置成其他任意模式都会出现迭代次数选项;
4) 选择聚类算法,可以选择需要自动建模的算法,以及设置每个算法自动调参的参数

算法的属性设置示例
5) 提取模型个数,可以指定提取自动建模生成模型的前top_n的模型;
6) 是否计算特征重要性;
7) 是否显示聚类大小饼状图;
8) 是否显示聚类分布图,参数的具体意义参考算子属性说明表格。
(3)算子的运行
自动聚类为自动建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接自动聚类算子,右击算子,点击运行,得到自动聚类模型。

运行自动聚类算子获得自动聚类模型示例
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的聚类结果进行评估。

自动聚类模型算子流示例
右击模型,查看模型的模型信息

自动聚类模型信息示例
点击生成模型栏,可以查看生成的top_n的模型列表,并且可以查看模型的详细参数如图所示。

自动聚类生成模型列表示例
点击对应模型,查看模型参数如图所示。

生成模型的模型参数示例
输出的表格结果以及评估结果是最优聚类算法的结果如图

最终的输出结果示例

最终评估结果示例
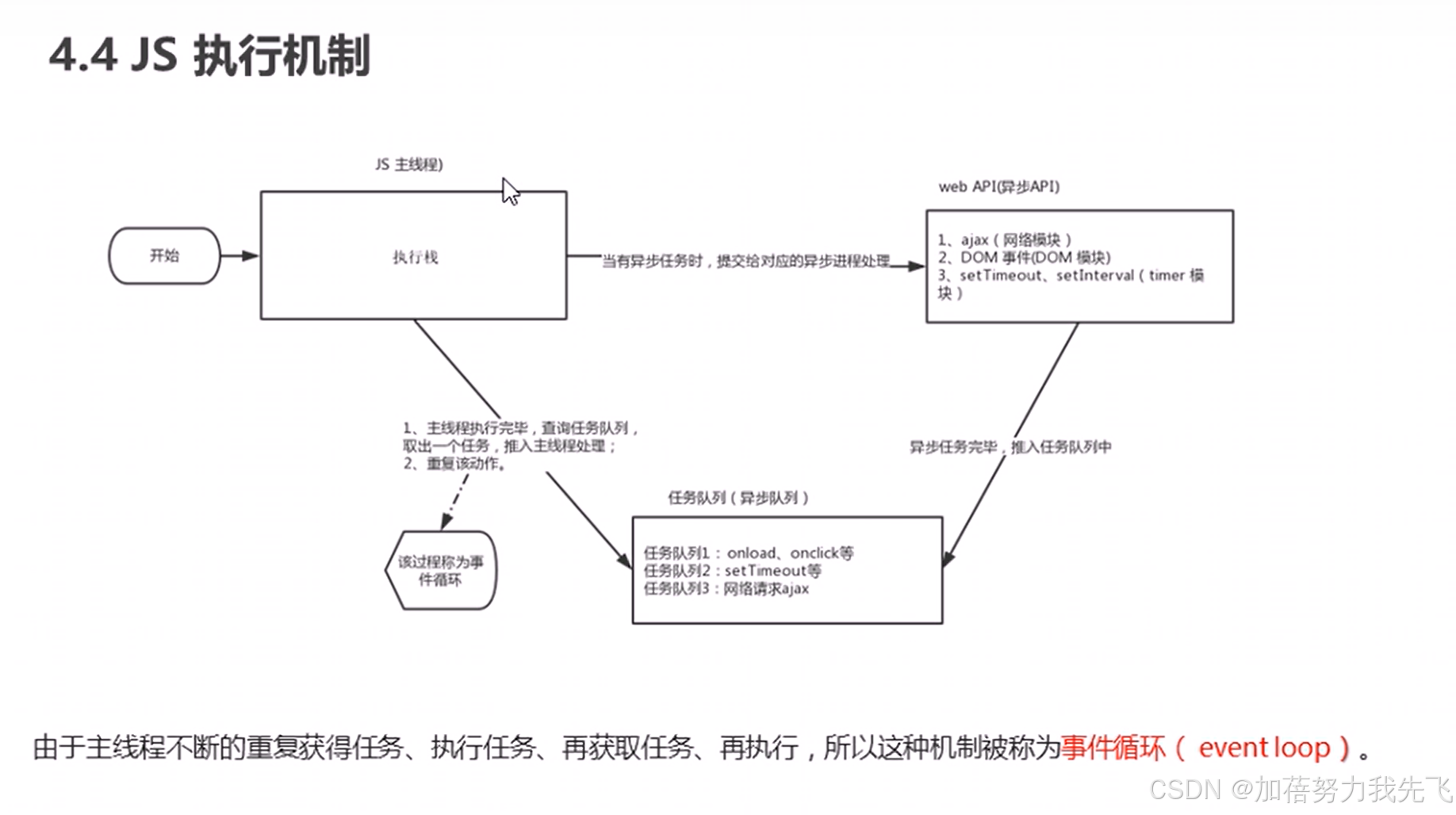
20.4 AutoARIMA
1.算子介绍
常用时间序列模型中的一种,如果只是根据单一目标变量的历史数据预测未来数据,可以使用ARIMA算法。AutoARIMA算法基于ARIMA算法,在给定p,d,q的范围内,查找最优参数p,d,q,再进行ARIMA预测。
2.算子类型
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| time_col | 时间列 | 必填 | String | null | 必须为时间格式 | 时间列 |
| value_col | 预测列 | 必填 | String | null | 数据列 | |
| key_col | key键列 | 非必填 | String | null | key键列 | |
| predictedN | 预测数量 | 必填 | Integer | 10 | 大于0 | 预测数量 |
| analyze_frequency | 分析频率 | 必填 | String | minute | 选项有"year",“month”, “day”, “hour”, “minute”,“second” | |
| analyze_time_span | 分析时间间隔 | 必填 | Integer | 5 | 大于0 | 分析时间间隔 |
| maxP | 自回归项数p上限 | 必填 | Integer | 5 | 大于0 | 自回归项数最大值限制 |
| maxD | 差分阶数d上限 | 必填 | Integer | 3 | 大于0 | 时间序列成为平稳时所做的差分次数的最大值限制 |
| maxQ | 移动平均项数q上限 | 必填 | Integer | 5 | 大于0 | 移动平均项数最大值限制 |
| alpha | 显著性水平 | 必填 | Double | 0.05 | 大于0且小于1 | 显著性水平 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化算子
(2)算子属性设置
AutoARIMA算子根据现有的时间序列对应的数据,预测未来时间的数据。AutoARIMA算子的输入数据建议是时序数据清洗算子处理后的数据。时间列必须为DataTime/Data类型。时间序列预测算子的分析频率应与时序数据清洗算子的采样频率一致,且分析时间间隔需大于等于时序数据清洗算子的采样时间间隔。

AutoARIMANode属性参数设置
(3)算子的运行
时间序列预测算子的输入数据要求是经过时序数据清洗的数据。算子后可接任意个数据处理算子,再接表格算子或数据写出算子,形成算子流执行。

AutoARIMA算子预测算子流
算子的运行结果如图所示

算子流预测结果
结果说明:结果中有时间列,key列(如果源数据没有key列则不会输出),要预测的列value列, predicted列表示是否为预测行,当predicted为false时,predicted_value1表示是历史数据的拟合值,当predicted为true时,predicted_value1表示预测值,lower confidence limit 和upper confidence limit分别为置信区间的上限和下限。
20.5 自动数据准备
1.算子介绍
自动数据准备算子,可以自动对数据进行特征工程和数据预处理。该算子是一个建模算子,可以针对相同数据集进行建模修改。
2.算子类型
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| Filter_different_values | 过滤不同类别过多列 | 必填 | Continuous | 100 | (1,infinte] | 过滤不同值过多的离散列 |
| Outlier_filter | 过滤异常系数 | 必填 | Continuous | 3 | (1,infinte] | 对异常值进行过滤 |
| Column_pca | PCA降维原始列 | 必填 | Continuous | 20 | (0,infinte] | 对列特征进行降维 |
| Column_pca_ | 降维目标列数 | 必填 | Continuous | 10 | (0,infinte] | 将维后的列数 |
| Label_handle | 数据平衡列处理 | 必填 | Categorical | 下采样 | 无 | 对不平衡数据进行数据平衡 |
| Miss_Value_percentage | 过滤缺失值比例过高列填充比例过低列 | 必填 | Categorical | 0.5 | (0,1) | 过滤缺失值比例过高列,填充缺失值比例过低列 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作如图所示
(2)算子属性设置
自动数据准备的属性设置如图所示

自动数据准备设置示例
前端可配置属性如图所示,参数有:
1) 过滤不同类别过多列,既离散列类别数大于用户设置的该值则过滤掉该列;
2) 过滤缺失值比例过高列填充比例过低列:判断缺失值是否过超过用户设置的比例,超过用户设置的比例过滤掉;低于用户设置的离散列用众数填充,连续列用平均数进行填充;
3) 对异常值进行过滤,过滤条件为用户设置的方差倍数;
4) 针对数据不平衡的数据进行上采样增加少类别的样本,或者下采样减少类别样本多的样本;
5) 针对连续数据进行降维,用户设置大于需要的特征列和降维后的列数对已有数据进行降维操作。
(3)算子的运行
自动数据准备为自动建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接自动数据准备算子,右击算子,点击运行,得到自动数据准备模型。

运行自动数据准备算子获得模型示例
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。算子流如图所示。

自动数据准备算子流示例
右击模型,查看模型的模型信息

自动数据准备模型信息示例
输出的表格结果图

最终的输出结果示例
为了非商业用途的科研学者、研究人员及开发者提供学习、交流及实践机器学习技术,推出了一款轻量化且完全免费的Sentosa_DSML社区版。以轻量化一键安装、平台免费使用、视频教学和社区论坛服务为主要特点,能够与其他数据科学家和机器学习爱好者交流心得,分享经验和解决问题。文章最后附上官网链接,感兴趣工具的可以直接下载使用
Sentosa_DSML社区版官网

Sentosa_DSML算子流开发视频