写作前面

之前一个相关的工作需要解析Himawari-8/9 Standard Data文件,因为他是二进制的,之前没有处理过,导致完全摸不着头脑。在网上找了中英文搜索找了好久,虽然也找到了公开的解析代码,但是放在自己的数据这感觉总是有点问题。直到我点进了它的官网,发现官方早就给你提供了解决方案。这波属于是自己给自己上强度了,下面我来分享具体的解析过程。
注意:
- 该过程在linux系统上实现,因为需要编译
- 需要提前安装好netcdf库
示例数据为:
- HS_H09_20240823_1420_B13_FLDK_R20_S0710.DAT.bz2
编译
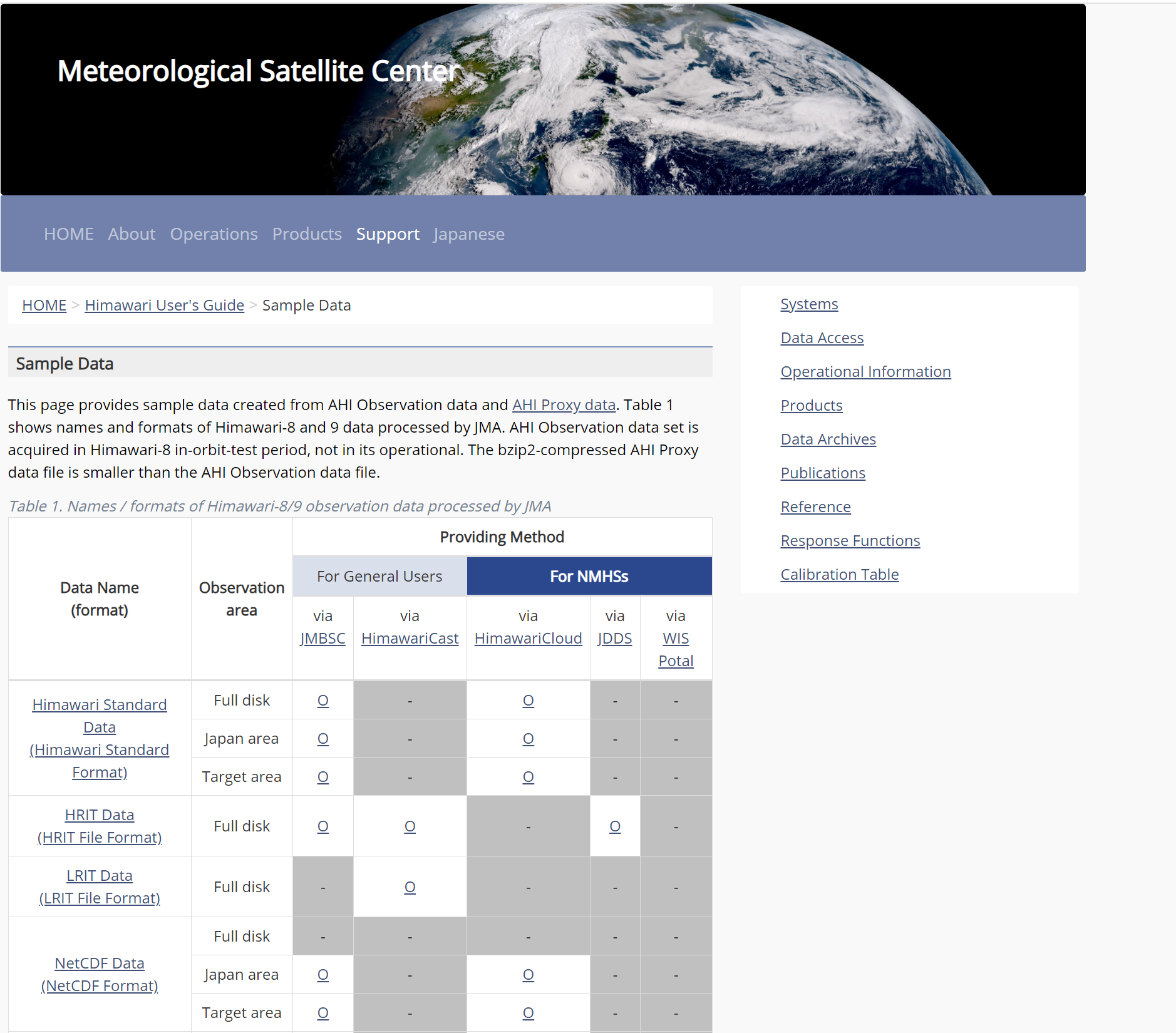
打开以下网址,拉到最下面,
- https://www.data.jma.go.jp/mscweb/en/himawari89/space_segment/spsg_sample.html
看见一个关于c语言的相关信息,根据自己的数据类型下载相关的工具,我这里选择第一个 Standard data

使用wget命令下载到服务器上,再使用unzip对文件进行解压,得到下面的内容:
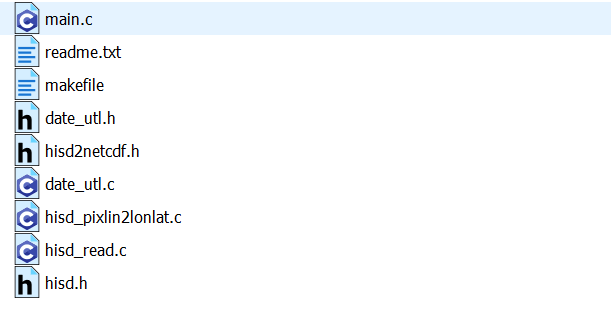
其实里面的readme也给了具体的编译过程,不过下面我还是仔细讲一下
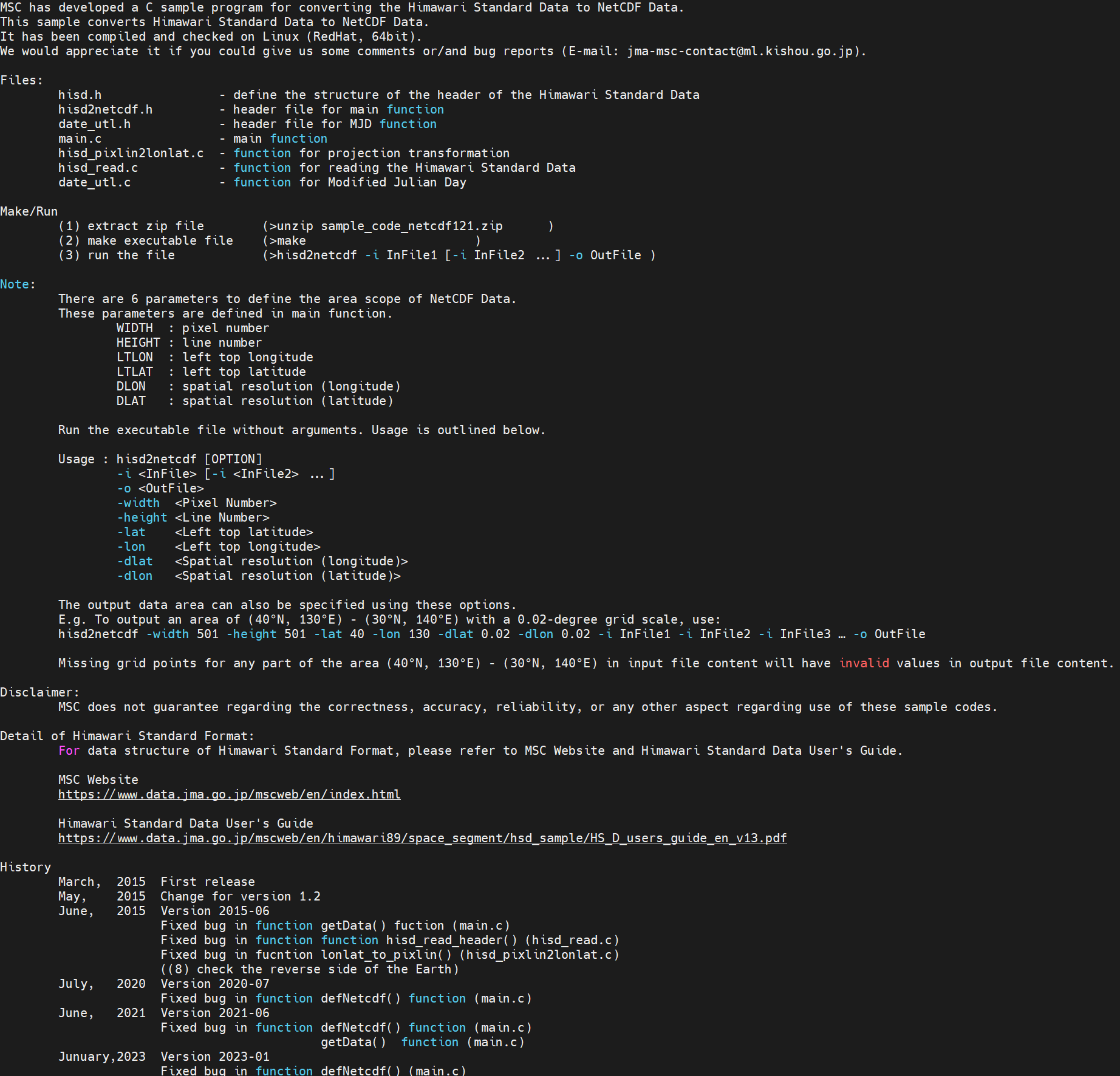
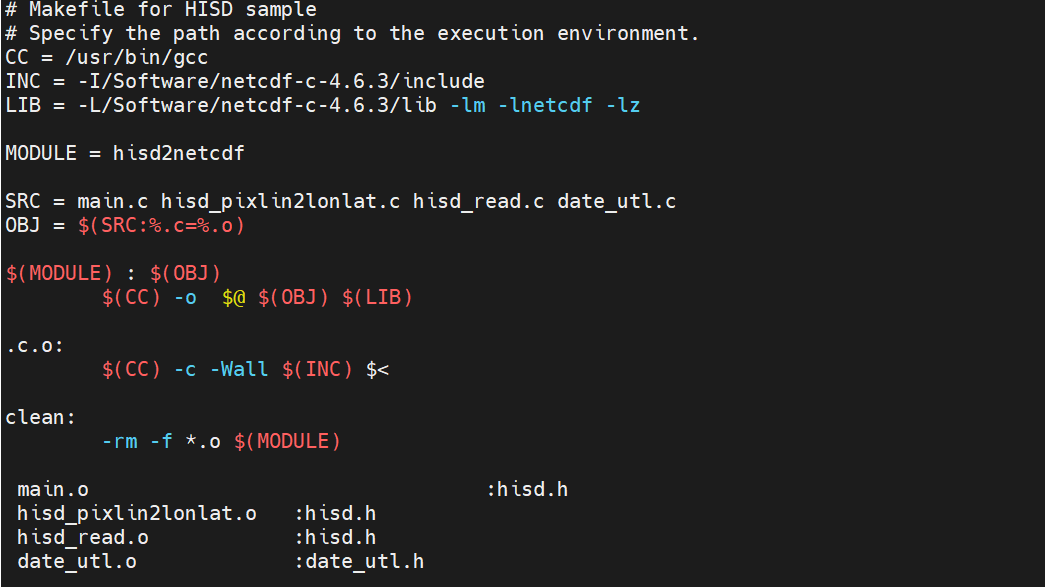
首先打开makefile文件
大致是下面的内容:

这里需要修改的地方为:
- CC
- INC
- LIB
第一个cc指定你的编译器,可能是gcc也可能是icc,可以使用which命令查看路径,我这里是gcc
python">
which gcc第二和第三个替换为你的netcdf中的include和lib的安装路径,意思就是告诉系统你的netcdf库安装的位置。
如果已经成功安装上了netcdf,使用命令 nc-config --all,应该能看到你的安装路径:
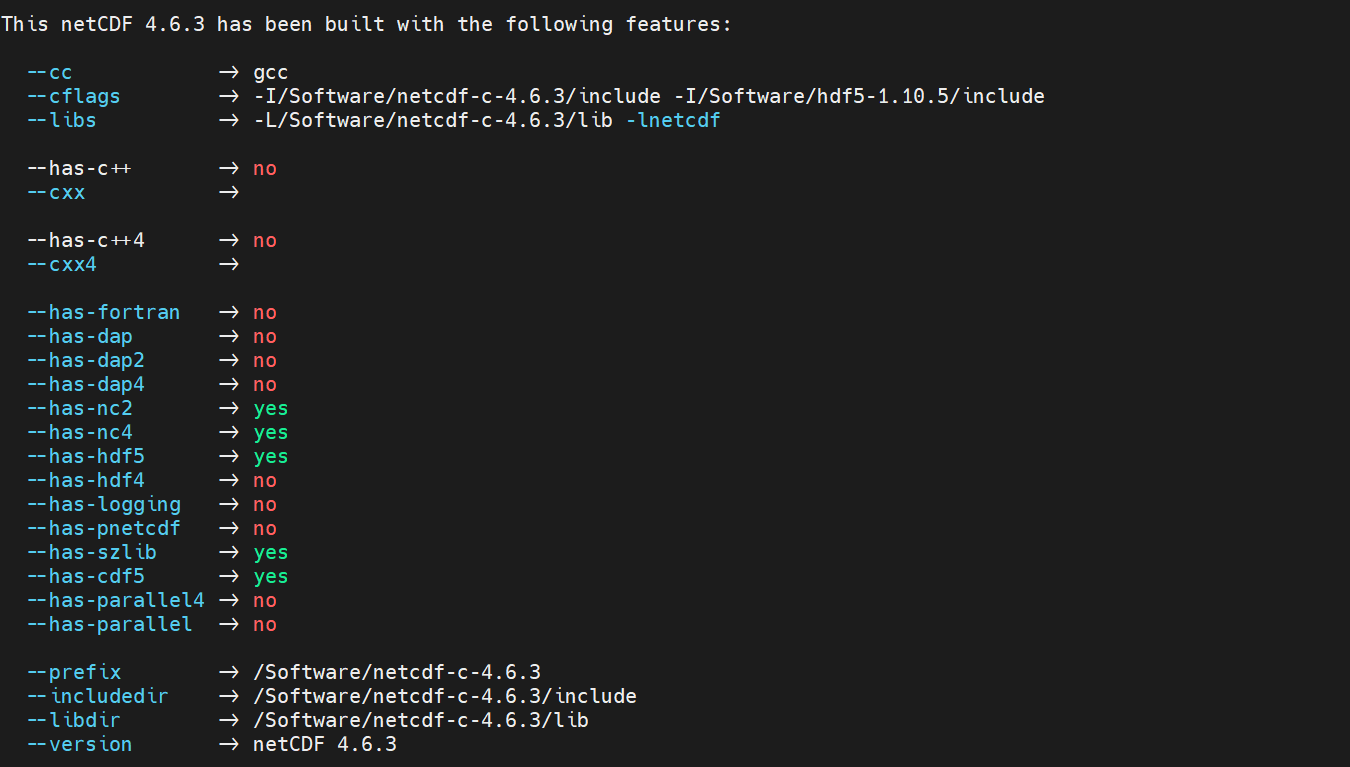
所以我这里替换最终在为:
使用命令make进行编译,下面是编译过程中的日子:

很快,大概几秒钟后,得到下面的内容:
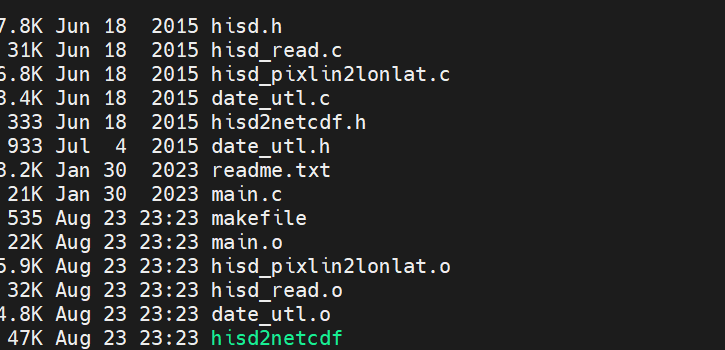
发现相比刚解压完,多出了一个hisd2netcdf的绿色的程序,说明编译成功了
运行找个程序,他会提醒你输入对应的参数:
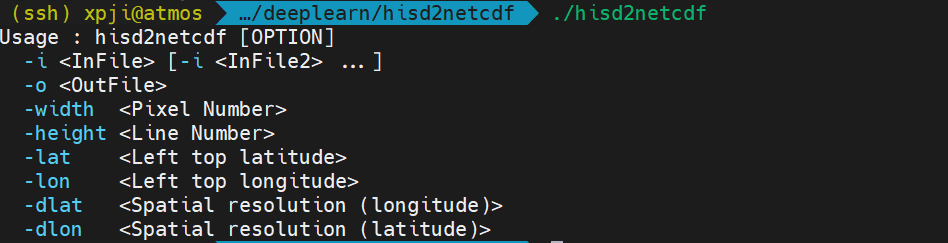
这边这个程序就搞定了
示例
下面找一个具体的数据进行测试,这部分的代码我通过python来实现,在python中调用刚刚编译的程序
由于下载的 Himawari-8/9 | Standard 是一个压缩的 .bz2文件,需要将其先进行解压,可以使用python中的bz2解压库,
- https://docs.python.org/zh-cn/3/library/bz2.html
我这里为了高效直接选择调用Linux 上的bzip2命令
python">def decompress_file(self, source_path, unzip_file_path):"""Decompresses a .bz2 file to a target path.Parameters:source_path (str): Path to the source .bz2 file.unzip_file_path (str): Path to the target decompressed file."""try:with open(unzip_file_path, 'wb') as output_file:subprocess.run([os.path.join(self.bin_path.strip(), 'bzip2'), '-d', '-k', '-c', source_path],check=True, shell=False, stdout=output_file)except subprocess.CalledProcessError as e:print(f"Error decompressing {source_path}: {e}")对于解压后的数据,调用hist工具包进行数据解码:
需要提供几个信息:
- 1、.bz文件的路径
- 2、解压后的路径
- 3、解析后的nc名称路径
- 4、hisd2netcdf的完整路径
- 5、经纬度区间以及分辨率,这是hisd2netcdf命令需要的参数
- 6、 需要读取的波段名称,这个可有可无
python">import os
import re
import subprocessdef decompress_file(source_path: str, unzip_file_path: str) -> None:"""Decompresses a .bz2 file to a target path.Parameters:source_path (str): Path to the source .bz2 file.unzip_file_path (str): Path to the target decompressed file."""try:# Use subprocess to call bzip2 for decompressionsubprocess.run(["bzip2", "-d", "-k", "-c", source_path],check=True,stdout=open(unzip_file_path, 'wb'))except subprocess.CalledProcessError as e:print(f"Error decompressing {source_path}: {e}")def run_conversion_command(cmd: list[str]) -> None:"""Runs a conversion command using subprocess.Parameters:cmd (list): List containing the command and arguments."""try:subprocess.run(cmd, check=True)except subprocess.CalledProcessError:print(f"Error running command: {' '.join(cmd)}")def main():# Paths and parametersfile_path = r"/Datadisk/hia9/20230621/0000/Z_SATE_C_RJTD_20230621001239_HS_H09_20230621_0000_B01_FLDK_R10_S0110.DAT.bz2"unzip_file_path = r"/Datadisk/hia9/20230621/0000/Z_SATE_C_RJTD_20230621001239_HS_H09_20230621_0000_B01_FLDK_R10_S0110.DAT"output_file_path = r"/Datadisk/HS_H09_20230621_0000_B01_FLDK_R10_S0110.nc"# Decompress the filedecompress_file(file_path, unzip_file_path)# Determine output file name and extract band numberfile_basename = os.path.basename(unzip_file_path)output_file_name = re.search(r"HS_(.*)", file_basename).group(0).replace(".DAT", ".nc")band_number = re.search(r"B(\d{2})", output_file_name).group(0)# Define conversion parametersbands = ["B08", "B09", "B10", "B11", "B13", "B14", "B16"]lat_start = 0lat_end = 45lon_start = 100lon_end = 145grid_scale = 0.1# Conversion commandcmd = ["/Datadisk/code/bin/hisd2/hisd2netcdf","-width", "451","-height", "451","-lat", str(lat_end),"-lon", str(lon_start),"-dlat", str(grid_scale),"-dlon", str(grid_scale),"-i", unzip_file_path,"-o", output_file_path]# Run conversion commandrun_conversion_command(cmd)if __name__ == "__main__":main()下面是解析的过程
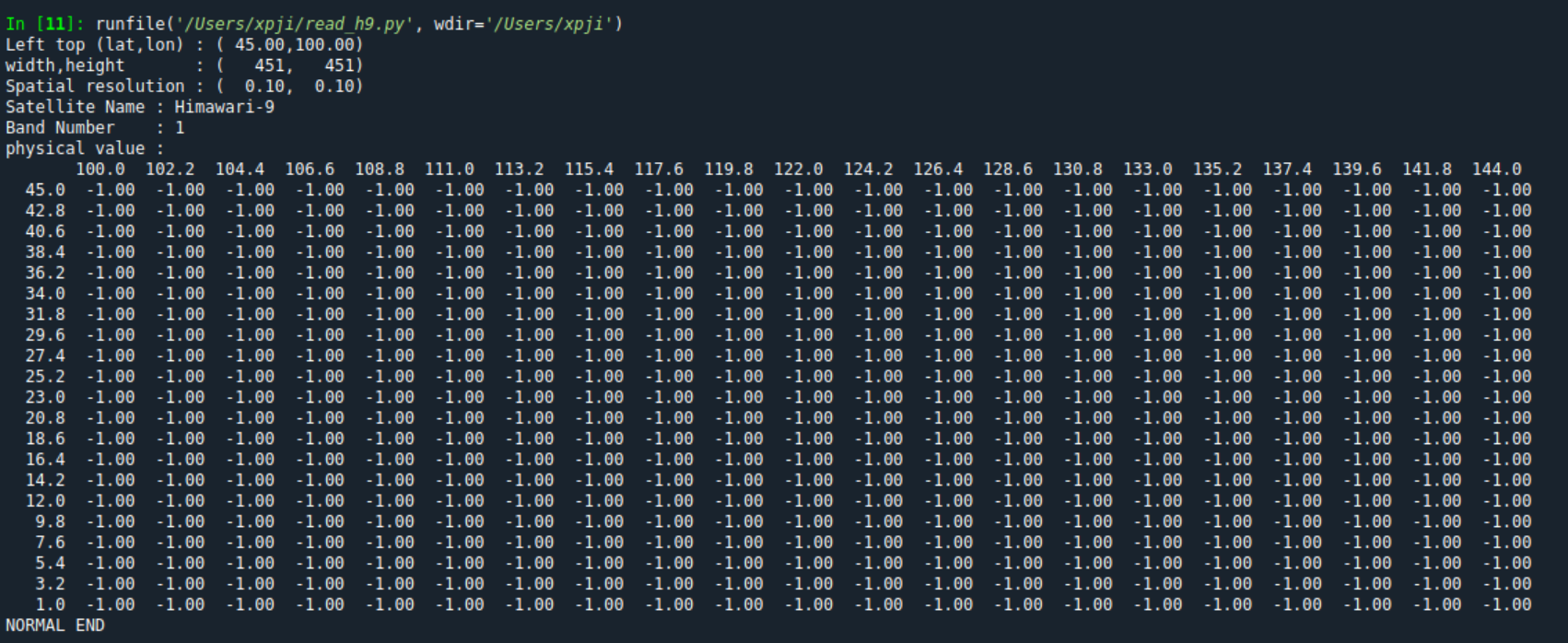
解析后就是netcdf格式的文件,后续就可以正常读取了。
但是需要注意的是,一个时刻的文件包含的信息可能比较少,需要同时读取多个时刻的文件合成的nc文件才能获得有效的结果。说的比较含糊,总之是谁用谁知道。
以后推送的相关代码也会放到GitHub上:
- https://github.com/Blissful-Jasper/jianpu_record
附上我曾搜到的一些其他解析方法:
https://github.com/ZPYin/Himawari-8_Visualizer
https://docs.com-swirls.org/auto_examples/read_h8.html
https://www.data.jma.go.jp/mscweb/en/himawari89/space_segment/spsg_sample.html



