目录
1.基础的客户端
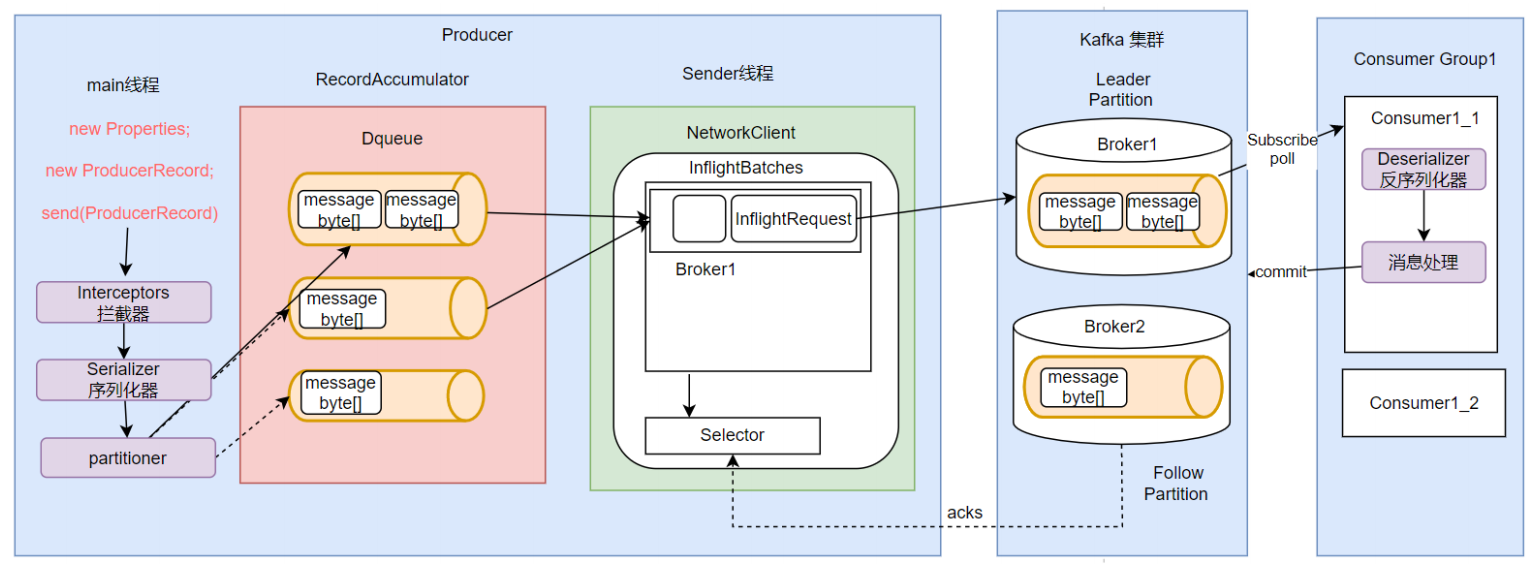
1.1消息发送者的主流程
1.2消息消费者主流程
2.客户端工作机制
2.1消费者分组消费机制
2.2生产者拦截器机制
2.3消息序列化机制
2.4消息分区路由机制
2.5生产者消息缓存机制
2.6发送应答机制
2.7生产者消息幂等性
(1)生产者消息幂等性介绍
(2)解决方案
2.8生产者消息事务机制
(1)事务引入原因
(2)具体流程
3.客户端流程总结
Kafka提供了两套客户端API,HighLevel API和LowLevel API。 HighLevel API封装了kafka的运行细节,使用起来比较简单,是企业开发过程中最常用的客户端API。 而LowLevel API则需要客户端自己管理Kafka的运行细节,Partition,Offset这些数据都由客户端自行管理。
1.基础的客户端
1.1消息发送者的主流程
- 设置Producer核心属性
- 构建消息:Kafka的消息是一个Key-Value结构的消息。其中,key和value都可以是任意对象类型。其中,key主要是用来进行Partition分区的,业务上更关心的是value。
- 使用Producer发送消息:通常用到的就是单向发送、同步发送和异步发送三种发送方式。
注意:
- 单向发送:不关心服务端的应答;
- 同步发送:获取到服务端应答消息前,会阻塞当前线程;
- 异步发送:消息发送后不阻塞,服务端有应答后会触发回调函数。
1.2消息消费者主流程
- 设置Consumer核心属性
- 拉取消息:Kafka采用Consumer主动拉取消息的Pull模式。consumer主动从Broker上拉取一批感兴趣的消息。
- 处理消息,提交位点:消费者将消息拉取完成后,就可以交由业务自行处理对应的这一批消息了。只是消费者需要向Broker提交偏移量offset。如果不提交Offset,Broker会认为消费者端消息处理失败了,还会重复进行推送。
2.客户端工作机制
2.1消费者分组消费机制
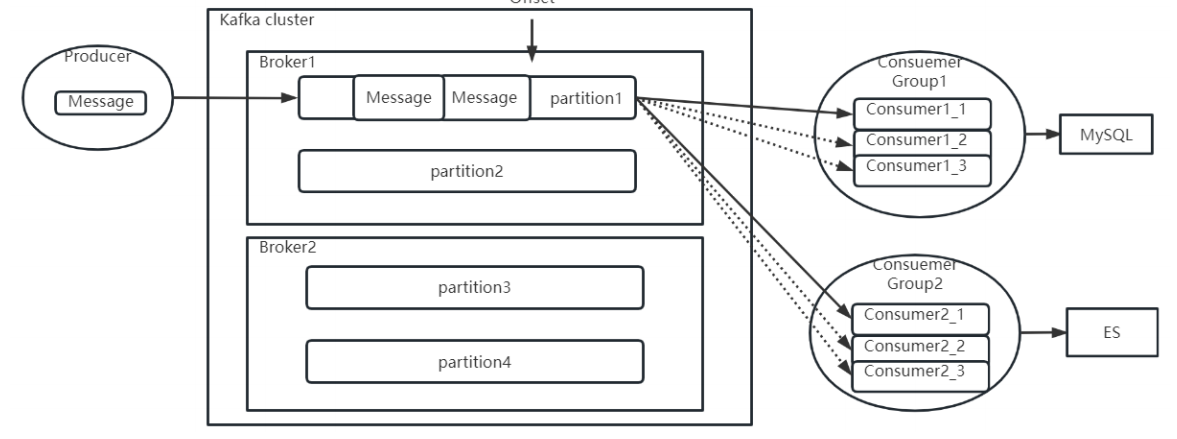
offset偏移量表示每个消费者组在每个Partiton中已经消费处理的进度。在Kafka中,可以看到消费者组的Offset记录情况。

个Offset偏移量,需要消费者处理完成后主动向Kafka的Broker提交。提交完成后,Broker就会更新消费进度,表示这个消息已经被这个消费者组处理完了。但是如果消费者没有提交Offset,Broker就会认为这个消息还没有被处理过,就会重新往对应的消费者组进行推送,不过这次,一般会尽量推送给同一个消费者组当中的其他消费者实例。
在示例当中,是通过业务端主动调用Consumer的commitAsync(异步)方法或者commitSync(同步)方法主动提交的,Kafka中自然也提供了自动提交Offset的方式。使用自动提交,只需要在Comsumer中配置ENABLE_AUTO_COMMIT_CONFIG属性即可。
(1)Offset是Kafka进行消息推送控制的关键之处
- Offset是根据Group、Partition分开记录的。消费者如果一个Partition对应多个Consumer消费者实例,那么每个Consumer实例都会往Broker提交同一个Partition的不同Offset,这时候Broker要听谁的?所以一个Partition最多只能同时被一个Consumer消费。也就是说,示例中四个Partition的Topic,那么同一个消费者组中最多就只能配置四个消费者实例。
- 这么关键的Offset数据,保存在Broker端,但是却是由"不靠谱"的消费者主导推进,这显然是不够安全的。那么应该如何提高Offset数据的安全性呢?如果你有兴趣自己观察,会发现在Consumer中,实际上也提供了AUTO_OFFSET_RESET_CONFIG参数,来指定消费者组在服务端的Offset不存在时如何进行后续消费。(有可能服务端初始化Consumer Group的Offset失败,也有可能Consumer Group当前的Offset对应的数据文件被过期删除了。)这就相当于服务端做的兜底保障。

(2)消费者应该要如何保证offset的安全性
有两种方式:一种是异步提交。就是消费者在处理业务的同时,异步向Broker提交Offset。这样好处是消费者的效率会比较高,但是如果消费者的消息处理失败了,而offset又成功提交了。这就会造成消息丢失。
另一种方式是同步提交。消费者保证处理完所有业务后,再提交Offset。这样的好处自然是消息不会因为offset丢失了。因为如果业务处理失败,消费者就可以不去提交Offset,这样消息还可以重试。但是坏处是消费者处理信息自然就慢了。另外还会产生消息重复。因为Broker端不可能一直等待消费者提交。如果消费者的业务处理时间比较长,这时在消费者正常处理消息的过程中,Broker端就已经等不下去了,认为这个消费者处理失败了。这时就会往同组的其他消费者实例投递消息,这就造成了消息重复处理。
这类问题的根源在于Offset反映的是消息的处理进度。而消息处理进度跟业务的处理进度又是不同步的。所有我们可以换一种思路,将Offset从Broker端抽取出来,放到第三方存储比如Redis里自行管理。这样就可以自己控制用业务的处理进度推进Offset往前更新。
2.2生产者拦截器机制
拦截器机制一般用得比较少,主要用在一些统一添加时间等类似的业务场景。比如,用Kafka传递一些POJO,就可以用拦截器统一添加时间属性。但是我们平常用Kafka传递的都是String类型的消息,POJO类型的消息,Kafka可以传吗?这就要用到下面的消息序列化机制。
2.3消息序列化机制
Kafka内部发送和接收消息的时候,使用的是byte[]字节数组的方式(RPC底层也是用这种通讯格式)
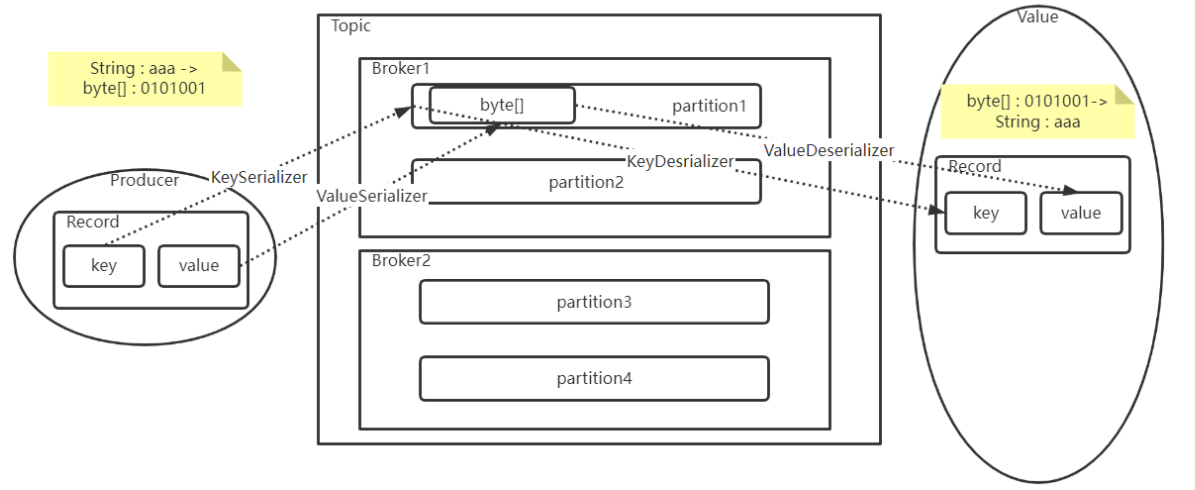
在Kafka中,对于常用的一些基础数据类型,都已经提供了对应的实现类。但是,如果需要使用一些自定义的消息格式,比如自己定制的POJO,就需要定制具体的序列化机制了。(需要考虑的是如何用二进制来描述业务数据)
序列化机制的实现方法:
如对于一个通常的POJO类型,可以将他的属性拆分成两种类型:一种类型是定长的基础类型,比如Integer, Long,Double等。这些基础类型转化成二进制数组都是定长的。这类属性可以直接转成序列化数组,在反序列化时,只要按照定长去读取二进制数据就可以反序列化了。另一种是不定长的浮动类型,比如String,或者基于String的JSON类型等。这种浮动类型的基础数据转化成二进制数组,长度都是不一定的。对于这类数据,通常的处理方式都是先往二进制数组中写入一个定长的数据的长度数据(Integer或者Long类型),然后再继续写入数据本身。这样,反序列化时,就可以先读取一个定长的长度,再按照这个长度去读取对应长度的二进制数据,这样就能读取到数据的完整二进制内容。
2.4消息分区路由机制
Kafka默认提供了三种消费者的分区分配策略:
- range策略:比如一个Topic有10个Partiton(partition 0~9) 一个消费者组下有三个Consumer(consumer1~3)。Range策略就会将分区0~3分给一个Consumer,4~6给一个Consumer,7~9给一个Consumer。
- round-robin策略:轮询分配策略,可以理解为在Consumer中一个一个轮流分配分区。比如0,3,6,9分区给一个Consumer,1,4,7分区给一个Consumer,然后2,5,8给一个Consumer。
- sticky策略:粘性策略。这个策略有两个原则:
- 在开始分区时,尽量保持分区的分配均匀。比如按照Range策略分(这一步实际上是随机的)。
- 分区的分配尽可能的与上一次分配的保持一致。比如在range分区的情况下,第三个Consumer的服务宕机了,那么按照sticky策略,就会保持consumer1和consumer2原有的分区分配情况。然后将consumer3分配的7~9分区尽量平均的分配到另外两个consumer上。这种粘性策略可以很好的保持Consumer的数据稳定性。
也可以自定义实现分区路由机制。
2.5生产者消息缓存机制
Kafka生产者为了避免高并发请求对服务端造成过大压力,每次发消息时并不是一条一条发往服务端,而是增加了一个高速缓存,将消息集中到缓存后,批量进行发送。这种缓存机制也是高并发处理时非常常用的一种机制。
Kafka的消息缓存机制涉及到KafkaProducer中的两个关键组件: accumulator 和 sender
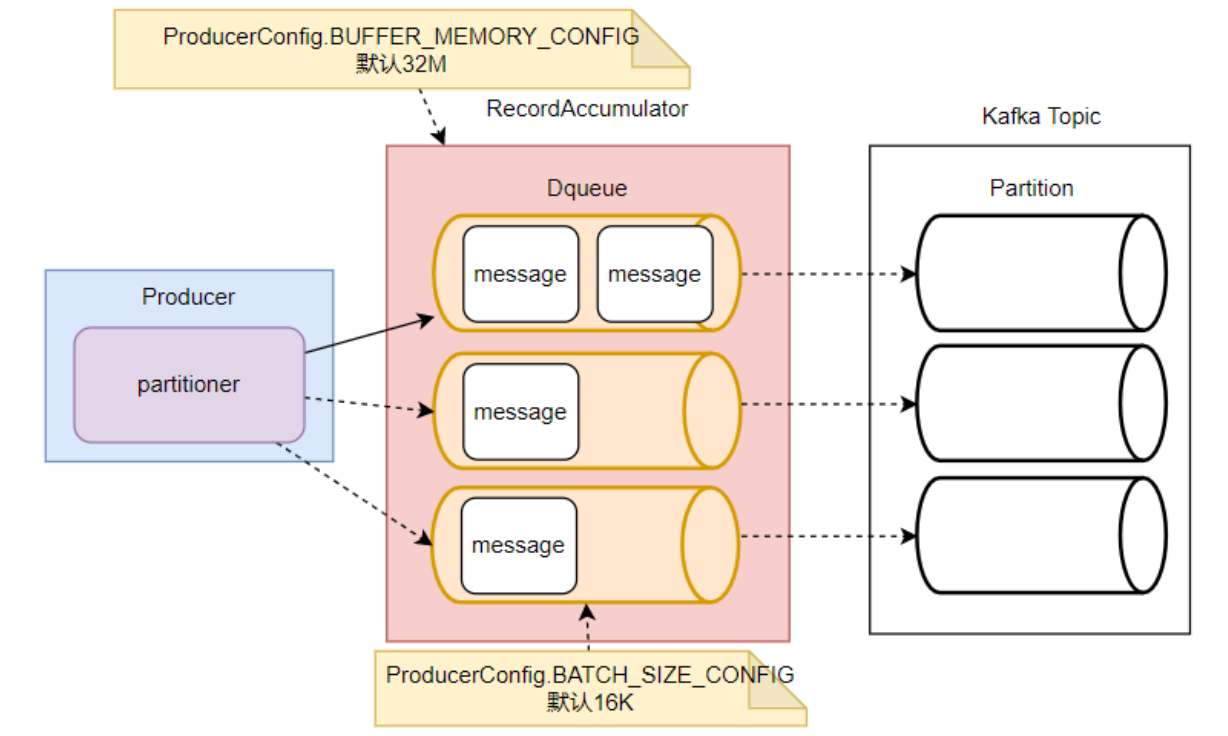
RecordAccumulator,就是Kafka生产者的消息累加器。Kafka Producer要发送的消息都会在ReocrdAccumulator中缓存起来,然后再分批发送给kafka broker。在RecordAccumulator中,会针对每一个Partition,维护一个Deque双端队列,这些Dequeue队列基本上是和Kafka服务端的Topic下的Partition对应的。每个Dequeue里会放入若干个ProducerBatch数据。 (涉及到两个参数:BUFFER_MEMORY_CONFIG 是指RecordAccumulator缓冲区大小,BATCH_SIZE_CONFIG 是指缓冲区中每一个batch的大小)
KafkaProducer每次发送的消息,都会根据key分配到对应的Deque队列中。然后每个消息都会保存在这些队列中的某一个ProducerBatch中。而消息分发的规则,就是由上面的Partitioner组件完成的。
Sender就是KafkaProducer中用来发送消息的一个单独的线程。从这里可以看到,每个KafkaProducer对象都对应一个sender线程。他会负责将RecordAccumulator中的消息发送给Kafka。
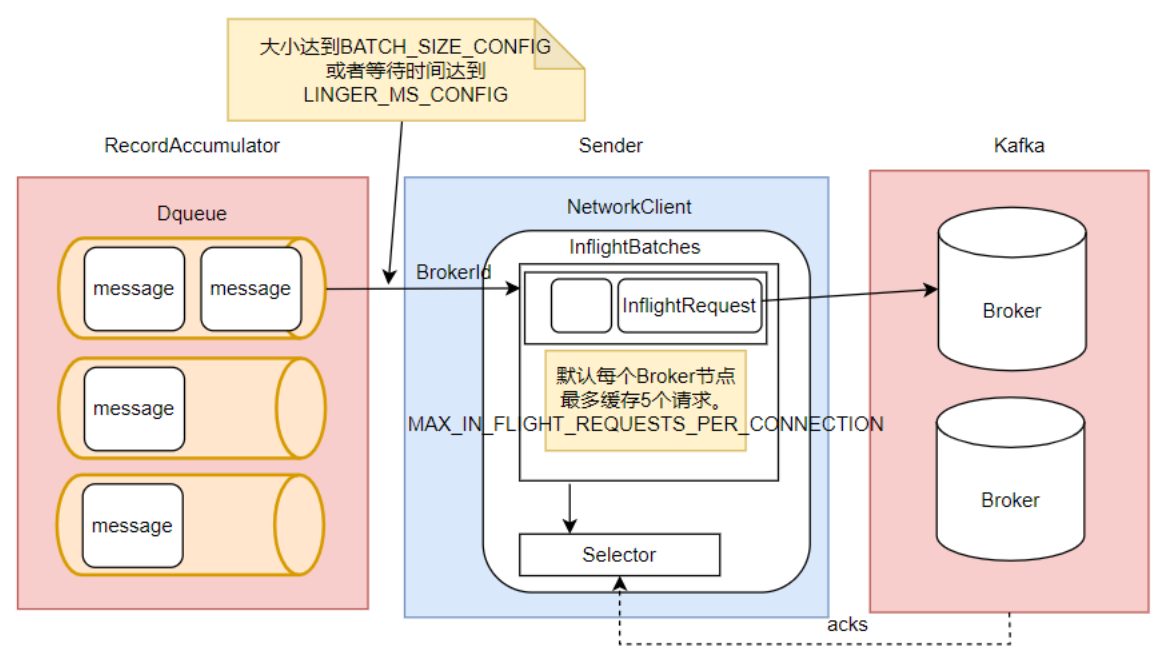
nder也并不是一次就把RecordAccumulator中缓存的所有消息都发送出去,而是每次只拿一部分消息。他只获取RecordAccumulator中缓存内容达到BATCH_SIZE_CONFIG大小的ProducerBatch消息。当然,如果消息比较少,ProducerBatch中的消息大小长期达不到BATCH_SIZE_CONFIG的话,Sender也不会一直等待。最多等待LINGER_MS_CONFIG时长。然后就会将ProducerBatch中的消息读取出来。(LINGER_MS_CONFIG默认值是0 )
然后,Sender对读取出来的消息,会以Broker为key,缓存到一个对应的队列当中。这些队列当中的消息就称为InflightRequest。接下来这些Inflight就会一 一发往Kafka对应的Broker中,直到收到Broker的响应,才会从队列中移除。这些队列也并不会无限缓存,最多缓存MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION(默认值为5)个请求。
注意:生产者缓存机制的主要目的是将消息打包,减少网络IO频率。所以,在Sender的InflightRequest队列中,消息也不是一条一条发送给Broker的,而是一批消息一起往Broker发送。而这就意味着这一批消息是没有固定的先后顺序的。
最后,Sender会通过其中的一个Selector组件完成与Kafka的IO请求,并接收Kafka的响应。
补充:Kafka的生产者缓存机制是Kafka面对海量消息时非常重要的优化机制。合理优化这些参数,对于Kafka集群性能提升是非常重要的。比如如果你的消息体比较大,那么应该考虑加大batch.size,尽量提升batch的缓存效率。而如果Producer要发送的消息确实非常多,那么就需要考虑加大total.memory参数,尽量避免缓存不够造成的阻塞。如果发现生产者发送消息比较慢,那么可以考虑提升max.in.flight.requests.per.connection参数,这样能加大消息发送的吞吐量。
2.6发送应答机制
在Producer将消息发送到Broker后,要怎么确定消息是不是成功发到Broker上了呢?
这里涉及到的,就是在Producer端一个不太起眼的属性ACKS_CONFIG。这个属性更大的作用在于保证消息的安全性,尤其在replica-factor备份因子比较大的Topic中,尤为重要。
- acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。吞吐量是最高的,但是数据安全性是最低的。
- acks=all or -1,生产者需要等Broker端的所有Partiton(Leader Partition以及其对应的Follower Partition )都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞吐量是最低的。
- acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回结果。
应用场景:在生产环境中,acks=0可靠性太差,很少使用。acks=1,一般用于传输日志等,允许个别数据丢失的场景。使用范围最广。acks=-1,一般用于传输敏感数据,比如与钱相关的数据。
注意:如果ack设置为all或者-1 ,Kafka也并不是强制要求所有Partition都写入数据后才响应。在Kafka的Broker 服务端会有一个配置参数min.insync.replicas,控制Leader Partition在完成多少个Partition的消息写入后,往Producer返回响应。这个参数可以在broker.conf文件中进行配置。
2.7生产者消息幂等性
(1)生产者消息幂等性介绍
当Producer的acks设置为1或-1时,Producer每次发送消息都是需要获取Broker端返回的RecordMetadate的。这个过程就需要两次跨网络请求。
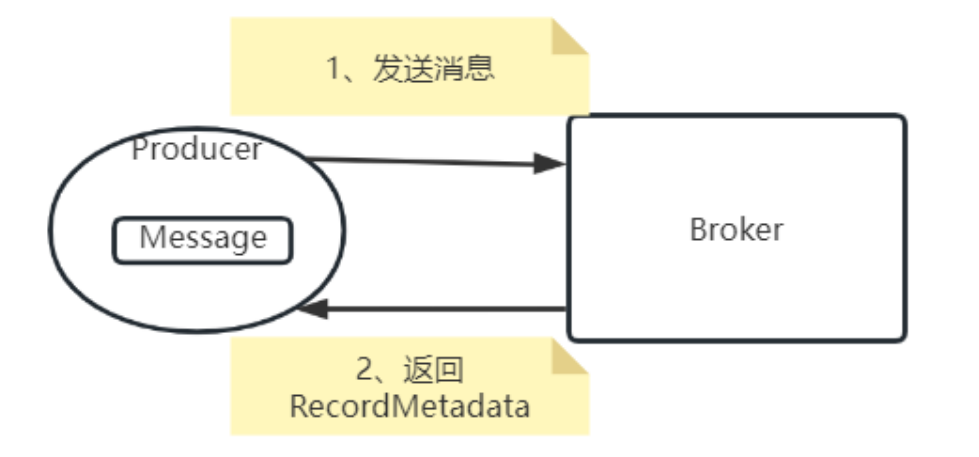
如果要保证消息安全,那么对于每个消息,这两次网络请求就必须要求是幂等的。但是,网络是不靠谱的,在高并发场景下,往往没办法保证这两个请求是幂等的。Producer发送消息的过程中,如果第一步请求成功了, 但是第二步却没有返回。这时,Producer就会认为消息发送失败了。那么Producer必然会发起重试。重试次数由参数ProducerConfig.RETRIES_CONFIG,默认值是Integer.MAX。
这时问题就来了。Producer会重复发送多条消息到Broker中。Kafka如何保证无论Producer向Broker发送多少次重复的数据,Broker端都只保留一条消息,而不会重复保存多条消息呢?这就是Kafka消息生产者的幂等性问题。
(2)解决方案
分布式数据传递过程中的三个数据语义:
at-least-once:至少一次;at-most-once:最多一次;exactly-once:精确一次。
通常意义上,at-least-once可以保证数据不丢失,但是不能保证数据不重复。而at-most-once保证数据不重复,但是又不能保证数据不丢失。这两种语义虽然都有缺陷,但是实现起来相对来说比较简单。但是对一些敏感的业务数据,往往要求数据即不重复也不丢失,这就需要支持Exactly-once语义。而要支持Exactly-once语义,需要有非常精密的设计。
Kafka为了保证消息发送的Exactly-once语义,增加了几个概念:
- PID:每个新的Producer在初始化的过程中就会被分配一个唯一的PID。这个PID对用户是不可见的。
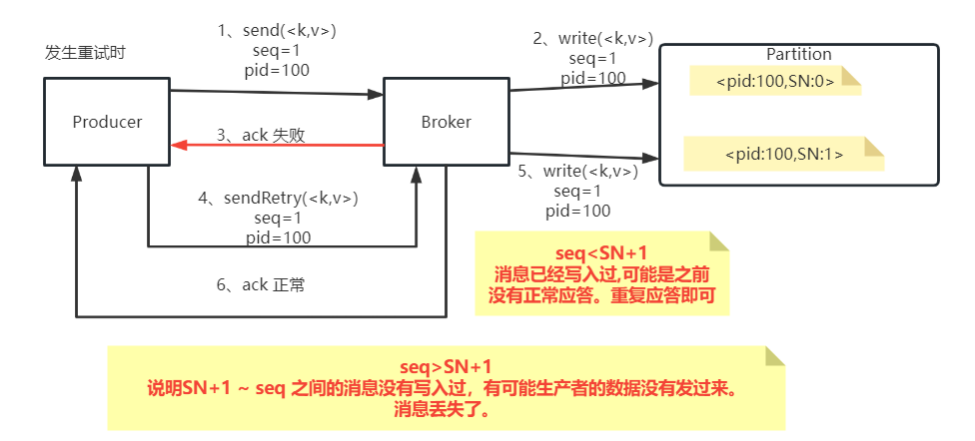
- Sequence Numer: 对于每个PID,这个Producer针对Partition会维护一个sequenceNumber。这是一个从0开始单调递增的数字。当Producer要往同一个Partition发送消息时,这个Sequence Number就会加1。然后会随着消息一起发往Broker。
- Broker端则会针对每个<PID,Partition>维护一个序列号(SN),只有当对应的SequenceNumber = SN+1时,Broker才会接收消息,同时将SN更新为SN+1。否则,SequenceNumber过小就认为消息已经写入了,不需要再重复写入。而如果SequenceNumber过大,就会认为中间可能有数据丢失了。对生产者就会抛出一个OutOfOrderSequenceException。
2.8生产者消息事务机制
(1)事务引入原因
通过生产者消息幂等性问题,能够解决单生产者消息写入单分区的的幂等性问题。
但是,如果是要写入多个分区呢?比如像我们的示例中,就发送了五条消息,他们的key都是不同的。这批消息就有可能写入多个Partition,而这些Partition是分布在不同Broker上的。这意味着,Producer需要对多个Broker同时保证消息的幂等性。
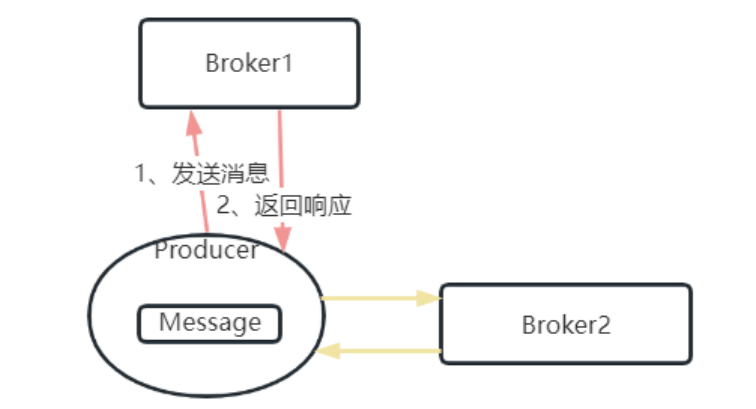
这时候,通过上面的生产者消息幂等性机制就无法保证所有消息的幂等了。这时候就需要有一个事务机制,保证这一批消息最好同时成功的保持幂等性。或者这一批消息同时失败,这样生产者就可以开始进行整体重试,消息不至于重复。
(2)具体流程
Producer中的几个API:

注意:
1.一个TransactionId只会对应一个PID
如果当前一个Producer的事务没有提交,而另一个新的Producer保持相同的TransactionId,这时旧的生产者会立即失效,无法继续发送消息。
2.跨会话事务对齐
如果某个Producer实例异常宕机了,事务没有被正常提交。那么新的TransactionId相同的Producer实例会对旧的事务进行补齐。保证旧事务要么提交,要么终止。这样新的Producer实例就可以以一个正常的状态开始工作。
3.客户端流程总结