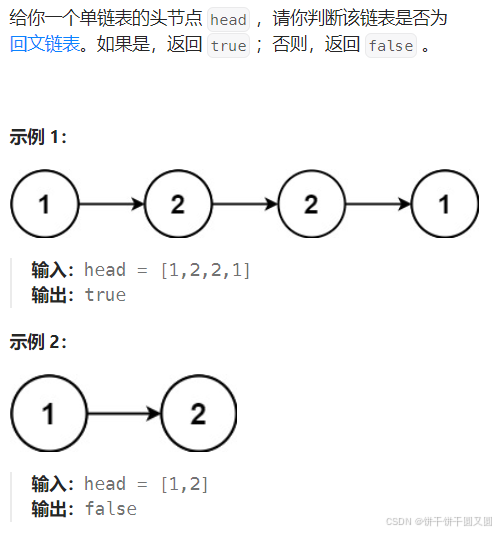
标题:数据捕手:Python 爬虫在社交媒体的深度探索
在数字化时代,社交媒体数据成为了洞察用户行为、市场趋势和公共情绪的宝贵资源。Python作为一种强大的编程语言,提供了丰富的库和框架,使得从社交媒体平台抓取数据变得可行且高效。本文将详细介绍如何使用Python爬虫技术抓取社交媒体数据,包括准备工作、技术选型、代码实现以及数据的存储和分析。
一、社交媒体数据的重要性
社交媒体数据不仅包括用户的公开帖子、评论、点赞等互动信息,还可能包含用户的位置、时间等元数据。这些数据对于市场研究、品牌分析、舆情监控等领域具有重要价值。
二、准备工作
在开始编写爬虫之前,需要进行以下准备工作:
- 了解目标社交媒体平台的API政策:许多社交媒体平台提供了API接口,允许开发者按照规定抓取数据。
- 选择合适的Python库:如
requests用于HTTP请求,BeautifulSoup或lxml用于解析HTML,Selenium用于模拟浏览器操作。 - 遵守法律法规和平台规则:尊重用户隐私和版权,合法合规地使用数据。
三、技术选型
根据目标数据的特点和来源,选择合适的技术方案:
- API抓取:使用社交媒体提供的API接口,如Twitter API、Facebook Graph API等。
- 网页爬取:对于没有开放API或API限制较多的平台,可以通过分析网页结构进行爬取。
四、Python爬虫代码实现
以下是一个简单的Python爬虫示例,使用requests和BeautifulSoup库抓取社交媒体上的公开数据:
python">import requests
from bs4 import BeautifulSoupdef fetch_social_media_data(url):headers = {'User-Agent': 'Mozilla/5.0'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')# 假设我们想抓取所有用户的用户名和帖子内容posts = []for post in soup.find_all('post_class'): # 假设'post_class'是帖子的类名username = post.find('username_class').text # 假设'username_class'是用户名的类名content = post.find('content_class').text # 假设'content_class'是内容的类名posts.append({'username': username, 'content': content})return posts# 使用示例
url = 'https://example-social-media.com'
data = fetch_social_media_data(url)
print(data)
五、数据存储与分析
抓取到的数据需要进行存储和分析才能发挥其价值:
- 数据存储:可以使用数据库如MySQL、MongoDB或文件系统存储数据。
- 数据分析:使用Python的数据分析库如
pandas进行数据清洗、统计和可视化。
六、注意事项
七、总结
使用Python爬虫抓取社交媒体数据是一个涉及多个步骤的复杂过程,从技术选型到代码实现,再到数据的存储和分析,每一步都需要精心设计和实施。本文提供了一个基本的框架和示例代码,帮助你开始这一旅程。记住,始终遵守法律法规和平台规则,合理利用社交媒体数据。
通过本文的介绍,你已经掌握了使用Python爬虫技术抓取社交媒体数据的基本方法。现在,你可以开始构建自己的爬虫,挖掘社交媒体的丰富数据资源,为你的研究或业务提供支持。

![[Algorithm][综合训练][孩子们的游戏][大数加法][拼三角]详细讲解](https://i-blog.csdnimg.cn/direct/19a2a00b4f764a14a499e850bf09697c.png)