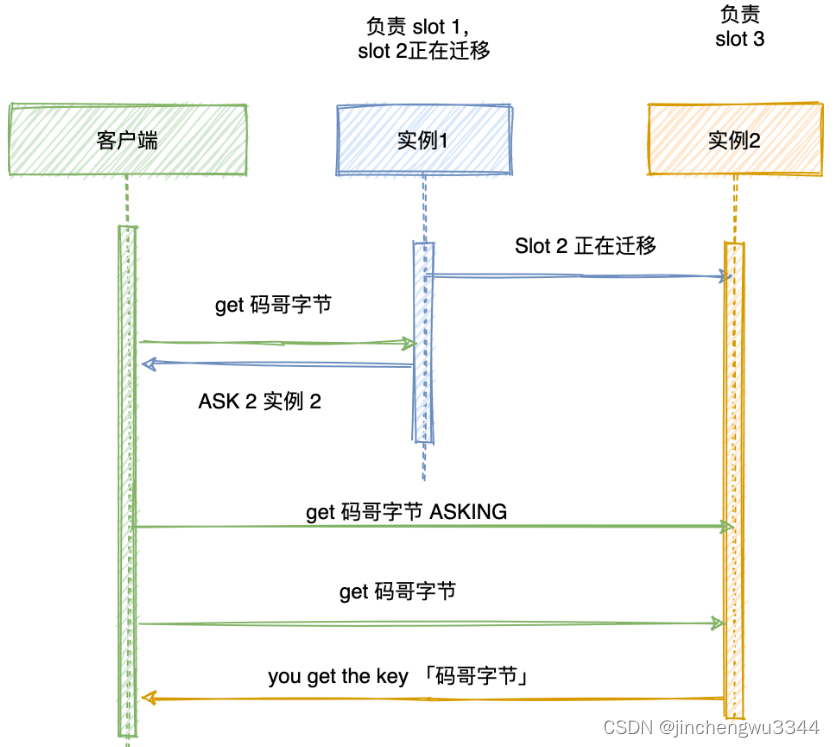
NMT结构图:(具体结构图)

LSTM基础知识
nmt_model.py:
参考文章:LSTM输出结构描述
#!/usr/bin/env python3
# -*- coding: utf-8 -*-"""
CS224N 2020-21: Homework 4
nmt_model.py: NMT Model
Pencheng Yin <pcyin@cs.cmu.edu>
Sahil Chopra <schopra8@stanford.edu>
Vera Lin <veralin@stanford.edu>
"""
from collections import namedtuple
import sys
from typing import List, Tuple, Dict, Set, Union
import torch
import torch.nn as nn
import torch.nn.utils
import torch.nn.functional as F
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequencefrom model_embeddings import ModelEmbeddings
Hypothesis = namedtuple('Hypothesis', ['value', 'score'])class NMT(nn.Module):""" Simple Neural Machine Translation Model:- Bidrectional LSTM Encoder- Unidirection LSTM Decoder- Global Attention Model (Luong, et al. 2015)"""def __init__(self, embed_size, hidden_size, vocab, dropout_rate=0.2):""" Init NMT Model.@param embed_size (int): Embedding size (dimensionality)@param hidden_size (int): Hidden Size, the size of hidden states (dimensionality)@param vocab (Vocab): Vocabulary object containing src and tgt languagesSee vocab.py for documentation.@param dropout_rate (float): Dropout probability, for attention"""super(NMT, self).__init__()self.model_embeddings = ModelEmbeddings(embed_size, vocab)self.hidden_size = hidden_sizeself.dropout_rate = dropout_rateself.vocab = vocab# default valuesself.encoder = None self.decoder = Noneself.h_projection = Noneself.c_projection = Noneself.att_projection = Noneself.combined_output_projection = Noneself.target_vocab_projection = Noneself.dropout = None# For sanity check only, not relevant to implementationself.gen_sanity_check = Falseself.counter = 0### YOUR CODE HERE (~8 Lines)### TODO - Initialize the following variables:### self.encoder (Bidirectional LSTM with bias)### self.decoder (LSTM Cell with bias)### self.h_projection (Linear Layer with no bias), called W_{h} in the PDF.### self.c_projection (Linear Layer with no bias), called W_{c} in the PDF.### self.att_projection (Linear Layer with no bias), called W_{attProj} in the PDF.### self.combined_output_projection (Linear Layer with no bias), called W_{u} in the PDF.### self.target_vocab_projection (Linear Layer with no bias), called W_{vocab} in the PDF.### self.dropout (Dropout Layer)###### Use the following docs to properly initialize these variables:### LSTM:### https://pytorch.org/docs/stable/nn.html#torch.nn.LSTM### LSTM Cell:### https://pytorch.org/docs/stable/nn.html#torch.nn.LSTMCell### Linear Layer:### https://pytorch.org/docs/stable/nn.html#torch.nn.Linear### Dropout Layer:### https://pytorch.org/docs/stable/nn.html#torch.nn.Dropoutself.encoder = nn.LSTM(input_size=embed_size, hidden_size=hidden_size, bias=True, bidirectional=True)self.decoder = nn.LSTMCell(input_size=embed_size + hidden_size, hidden_size=hidden_size, bias=True)self.h_projection = nn.Linear(in_features=2 * hidden_size, out_features=hidden_size, bias=False)self.c_projection = nn.Linear(in_features=2 * hidden_size, out_features=hidden_size, bias=False)self.att_projection = nn.Linear(in_features=2 * hidden_size, out_features=hidden_size, bias=False)self.combined_output_projection = nn.Linear(in_features=3 * hidden_size, out_features=hidden_size, bias=False)self.target_vocab_projection = nn.Linear(in_features=hidden_size, out_features=len(self.vocab.tgt), bias=False)self.dropout = nn.Dropout(p=dropout_rate)### END YOUR CODEdef forward(self, source: List[List[str]], target: List[List[str]]) -> torch.Tensor:""" Take a mini-batch of source and target sentences, compute the log-likelihood oftarget sentences under the language models learned by the NMT system.@param source (List[List[str]]): list of source sentence tokens@param target (List[List[str]]): list of target sentence tokens, wrapped by `<s>` and `</s>`@returns scores (Tensor): a variable/tensor of shape (b, ) representing thelog-likelihood of generating the gold-standard target sentence foreach example in the input batch. Here b = batch size."""# Compute sentence lengthssource_lengths = [len(s) for s in source]# Convert list of lists into tensorssource_padded = self.vocab.src.to_input_tensor(source, device=self.device) # Tensor: (src_len, b)target_padded = self.vocab.tgt.to_input_tensor(target, device=self.device) # Tensor: (tgt_len, b)### Run the network forward:### 1. Apply the encoder to `source_padded` by calling `self.encode()`### 2. Generate sentence masks for `source_padded` by calling `self.generate_sent_masks()`### 3. Apply the decoder to compute combined-output by calling `self.decode()`### 4. Compute log probability distribution over the target vocabulary using the### combined_outputs returned by the `self.decode()` function.enc_hiddens, dec_init_state = self.encode(source_padded, source_lengths)enc_masks = self.generate_sent_masks(enc_hiddens, source_lengths)combined_outputs = self.decode(enc_hiddens, enc_masks, dec_init_state, target_padded)P = F.log_softmax(self.target_vocab_projection(combined_outputs), dim=-1)# Zero out, probabilities for which we have nothing in the target texttarget_masks = (target_padded != self.vocab.tgt['<pad>']).float()# Compute log probability of generating true target wordstarget_gold_words_log_prob = torch.gather(P, index=target_padded[1:].unsqueeze(-1), dim=-1).squeeze(-1) * target_masks[1:]scores = target_gold_words_log_prob.sum(dim=0)return scoresdef encode(self, source_padded: torch.Tensor, source_lengths: List[int]) -> Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:""" Apply the encoder to source sentences to obtain encoder hidden states.Additionally, take the final states of the encoder and project them to obtain initial states for decoder.@param source_padded (Tensor): Tensor of padded source sentences with shape (src_len, b), whereb = batch_size, src_len = maximum source sentence length. Note that these have already been sorted in order of longest to shortest sentence.@param source_lengths (List[int]): List of actual lengths for each of the source sentences in the batch@returns enc_hiddens (Tensor): Tensor of hidden units with shape (b, src_len, h*2), whereb = batch size, src_len = maximum source sentence length, h = hidden size.@returns dec_init_state (tuple(Tensor, Tensor)): Tuple of tensors representing the decoder's initialhidden state and cell."""enc_hiddens, dec_init_state = None, None### YOUR CODE HERE (~ 8 Lines)### TODO:### 1. Construct Tensor `X` of source sentences with shape (src_len, b, e) using the source model embeddings.### src_len = maximum source sentence length, b = batch size, e = embedding size. Note### that there is no initial hidden state or cell for the decoder.### 2. Compute `enc_hiddens`, `last_hidden`, `last_cell` by applying the encoder to `X`.### - Before you can apply the encoder, you need to apply the `pack_padded_sequence` function to X.### - After you apply the encoder, you need to apply the `pad_packed_sequence` function to enc_hiddens.### - Note that the shape of the tensor returned by the encoder is (src_len, b, h*2) and we want to### return a tensor of shape (b, src_len, h*2) as `enc_hiddens`.### 3. Compute `dec_init_state` = (init_decoder_hidden, init_decoder_cell):### - `init_decoder_hidden`:### `last_hidden` is a tensor shape (2, b, h). The first dimension corresponds to forwards and backwards.### Concatenate the forwards and backwards tensors to obtain a tensor shape (b, 2*h).### Apply the h_projection layer to this in order to compute init_decoder_hidden.### This is h_0^{dec} in the PDF. Here b = batch size, h = hidden size### - `init_decoder_cell`:### `last_cell` is a tensor shape (2, b, h). The first dimension corresponds to forwards and backwards.### Concatenate the forwards and backwards tensors to obtain a tensor shape (b, 2*h).### Apply the c_projection layer to this in order to compute init_decoder_cell.### This is c_0^{dec} in the PDF. Here b = batch size, h = hidden size###### See the following docs, as you may need to use some of the following functions in your implementation:### Pack the padded sequence X before passing to the encoder:### https://pytorch.org/docs/stable/nn.html#torch.nn.utils.rnn.pack_padded_sequence### Pad the packed sequence, enc_hiddens, returned by the encoder:### https://pytorch.org/docs/stable/nn.html#torch.nn.utils.rnn.pad_packed_sequence### Tensor Concatenation:### https://pytorch.org/docs/stable/torch.html#torch.cat### Tensor Permute:### https://pytorch.org/docs/stable/tensors.html#torch.Tensor.permuteX = self.model_embeddings.source(source_padded)X = pack_padded_sequence(X, lengths=torch.tensor(source_lengths))enc_hiddens, (last_hidden, last_cell) = self.encoder(X)enc_hiddens = pad_packed_sequence(enc_hiddens, batch_first=True)[0]last_hidden = torch.cat((last_hidden[0], last_hidden[1]), dim=1)init_decoder_hidden = self.h_projection(last_hidden)last_cell = torch.cat((last_cell[0], last_cell[1]), dim=1)init_decoder_cell = self.c_projection(last_cell)dec_init_state = (init_decoder_hidden, init_decoder_cell)### END YOUR CODEreturn enc_hiddens, dec_init_statedef decode(self, enc_hiddens: torch.Tensor, enc_masks: torch.Tensor, dec_init_state: Tuple[torch.Tensor, torch.Tensor], target_padded: torch.Tensor) -> torch.Tensor: # Chop off the <END> token for max length sentences. target_padded = target_padded[:-1] # Initialize the decoder state (hidden and cell) dec_state = dec_init_state # Initialize previous combined output vector o_{t-1} as zero batch_size = enc_hiddens.size(0) o_prev = torch.zeros(batch_size, self.hidden_size, device=self.device) # Initialize a list we will use to collect the combined output o_t on each step combined_outputs = [] enc_hiddens_proj = self.att_projection(enc_hiddens) Y = self.model_embeddings.target(target_padded) for Y_t in torch.split(Y, split_size_or_sections=1, dim=0): Y_t = torch.squeeze(Y_t, dim=0) Ybar_t = torch.cat((Y_t, o_prev), dim=1) next_dec_state, o_t, _ = self.step(Ybar_t, dec_state, enc_hiddens, enc_hiddens_proj, enc_masks) combined_outputs.append(o_t) o_prev = o_t dec_state = next_dec_state # Notice the corrected indentation here combined_outputs = torch.stack(combined_outputs, dim=0) ### END YOUR CODE return combined_outputsdef step(self, Ybar_t: torch.Tensor, dec_state: Tuple[torch.Tensor, torch.Tensor], enc_hiddens: torch.Tensor, enc_hiddens_proj: torch.Tensor, enc_masks: torch.Tensor) -> Tuple[Tuple, torch.Tensor, torch.Tensor]: combined_output = None # Decode the input based on the decoder's current state dec_state = self.decoder(Ybar_t, dec_state) dec_hidden, dec_cell = dec_state # Compute the attention scores e_t = torch.bmm(input=torch.unsqueeze(dec_hidden, 1), mat2=enc_hiddens_proj.permute(0, 2, 1)) e_t = torch.squeeze(e_t, dim=1) # Apply attention mask if necessary if enc_masks is not None: e_t.data.masked_fill_(enc_masks.bool(), -float('inf')) # Compute the attention weights alpha_t = F.softmax(e_t, dim=1) alpha_t = torch.unsqueeze(alpha_t, dim=1) # Compute the context vector a_t = torch.bmm(input=alpha_t, mat2=enc_hiddens) a_t = torch.squeeze(a_t, dim=1) # Combine the context vector and the decoder's hidden state u_t = torch.cat((a_t, dec_hidden), dim=1) # Project the combined vector v_t = self.combined_output_projection(u_t) # Apply dropout and nonlinearity O_t = self.dropout(torch.tanh(v_t)) # Assign the combined output combined_output = O_t # Return the updated decoder state, the combined output, and the attention scores return dec_state, combined_output, e_tdef generate_sent_masks(self, enc_hiddens: torch.Tensor, source_lengths: List[int]) -> torch.Tensor:""" Generate sentence masks for encoder hidden states.@param enc_hiddens (Tensor): encodings of shape (b, src_len, 2*h), where b = batch size,src_len = max source length, h = hidden size. @param source_lengths (List[int]): List of actual lengths for each of the sentences in the batch.@returns enc_masks (Tensor): Tensor of sentence masks of shape (b, src_len),where src_len = max source length, h = hidden size."""enc_masks = torch.zeros(enc_hiddens.size(0), enc_hiddens.size(1), dtype=torch.float)for e_id, src_len in enumerate(source_lengths):enc_masks[e_id, src_len:] = 1return enc_masks.to(self.device)def beam_search(self, src_sent: List[str], beam_size: int=5, max_decoding_time_step: int=70) -> List[Hypothesis]:""" Given a single source sentence, perform beam search, yielding translations in the target language.@param src_sent (List[str]): a single source sentence (words)@param beam_size (int): beam size@param max_decoding_time_step (int): maximum number of time steps to unroll the decoding RNN@returns hypotheses (List[Hypothesis]): a list of hypothesis, each hypothesis has two fields:value: List[str]: the decoded target sentence, represented as a list of wordsscore: float: the log-likelihood of the target sentence"""src_sents_var = self.vocab.src.to_input_tensor([src_sent], self.device)src_encodings, dec_init_vec = self.encode(src_sents_var, [len(src_sent)])src_encodings_att_linear = self.att_projection(src_encodings)h_tm1 = dec_init_vecatt_tm1 = torch.zeros(1, self.hidden_size, device=self.device)eos_id = self.vocab.tgt['</s>']hypotheses = [['<s>']]hyp_scores = torch.zeros(len(hypotheses), dtype=torch.float, device=self.device)completed_hypotheses = []t = 0while len(completed_hypotheses) < beam_size and t < max_decoding_time_step:t += 1hyp_num = len(hypotheses)exp_src_encodings = src_encodings.expand(hyp_num,src_encodings.size(1),src_encodings.size(2))exp_src_encodings_att_linear = src_encodings_att_linear.expand(hyp_num,src_encodings_att_linear.size(1),src_encodings_att_linear.size(2))y_tm1 = torch.tensor([self.vocab.tgt[hyp[-1]] for hyp in hypotheses], dtype=torch.long, device=self.device)y_t_embed = self.model_embeddings.target(y_tm1)x = torch.cat([y_t_embed, att_tm1], dim=-1)(h_t, cell_t), att_t, _ = self.step(x, h_tm1,exp_src_encodings, exp_src_encodings_att_linear, enc_masks=None)# log probabilities over target wordslog_p_t = F.log_softmax(self.target_vocab_projection(att_t), dim=-1)live_hyp_num = beam_size - len(completed_hypotheses)contiuating_hyp_scores = (hyp_scores.unsqueeze(1).expand_as(log_p_t) + log_p_t).view(-1)top_cand_hyp_scores, top_cand_hyp_pos = torch.topk(contiuating_hyp_scores, k=live_hyp_num)prev_hyp_ids = top_cand_hyp_pos // len(self.vocab.tgt)hyp_word_ids = top_cand_hyp_pos % len(self.vocab.tgt)new_hypotheses = []live_hyp_ids = []new_hyp_scores = []for prev_hyp_id, hyp_word_id, cand_new_hyp_score in zip(prev_hyp_ids, hyp_word_ids, top_cand_hyp_scores):prev_hyp_id = prev_hyp_id.item()hyp_word_id = hyp_word_id.item()cand_new_hyp_score = cand_new_hyp_score.item()hyp_word = self.vocab.tgt.id2word[hyp_word_id]new_hyp_sent = hypotheses[prev_hyp_id] + [hyp_word]if hyp_word == '</s>':completed_hypotheses.append(Hypothesis(value=new_hyp_sent[1:-1],score=cand_new_hyp_score))else:new_hypotheses.append(new_hyp_sent)live_hyp_ids.append(prev_hyp_id)new_hyp_scores.append(cand_new_hyp_score)if len(completed_hypotheses) == beam_size:breaklive_hyp_ids = torch.tensor(live_hyp_ids, dtype=torch.long, device=self.device)h_tm1 = (h_t[live_hyp_ids], cell_t[live_hyp_ids])att_tm1 = att_t[live_hyp_ids]hypotheses = new_hypotheseshyp_scores = torch.tensor(new_hyp_scores, dtype=torch.float, device=self.device)if len(completed_hypotheses) == 0:completed_hypotheses.append(Hypothesis(value=hypotheses[0][1:],score=hyp_scores[0].item()))completed_hypotheses.sort(key=lambda hyp: hyp.score, reverse=True)return completed_hypotheses@propertydef device(self) -> torch.device:""" Determine which device to place the Tensors upon, CPU or GPU."""return self.model_embeddings.source.weight.device@staticmethoddef load(model_path: str):""" Load the model from a file.@param model_path (str): path to model"""params = torch.load(model_path, map_location=lambda storage, loc: storage)args = params['args']model = NMT(vocab=params['vocab'], **args)model.load_state_dict(params['state_dict'])return modeldef save(self, path: str):""" Save the odel to a file.@param path (str): path to the model"""print('save model parameters to [%s]' % path, file=sys.stderr)params = {'args': dict(embed_size=self.model_embeddings.embed_size, hidden_size=self.hidden_size, dropout_rate=self.dropout_rate),'vocab': self.vocab,'state_dict': self.state_dict()}torch.save(params, path)model_embeddings.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import torch.nn as nn class ModelEmbeddings(nn.Module): def __init__(self, embed_size, vocab): super(ModelEmbeddings, self).__init__() self.embed_size = embed_size # default values self.source = None self.target = None src_pad_token_idx = vocab.src['<pad>'] tgt_pad_token_idx = vocab.tgt['<pad>'] self.source = nn.Embedding(num_embeddings=len(vocab.src), embedding_dim=self.embed_size, padding_idx=src_pad_token_idx) self.target = nn.Embedding(num_embeddings=len(vocab.tgt), embedding_dim=self.embed_size, padding_idx=tgt_pad_token_idx)### END YOUR CODE