数据分析中的预处理步骤是数据分析流程中的重要环节,它的目的是清洗、转换和整理原始数据,以便后续的分析能够准确、有效。预处理通常包括以下几个关键步骤:
-
数据收集:确定数据来源,可能是数据库、文件、API或网络抓取,确保数据的质量和完整性。
-
数据清洗(Data Cleaning):
- 缺失值处理:填充、删除或估算缺失的数据。
- 异常值检测:识别并可能修复或排除不合理的数值。
- 重复值检查:删除重复记录,保持数据唯一性。
- 数据类型转换:将数据调整为正确的格式,如日期时间格式化、数值类型等。
-
数据集成(Data Integration):如果数据来自多个源,需要合并和统一数据格式。
-
数据转换(Data Transformation):
- 标准化或归一化:使数据具有可比性,例如Z-score标准化或Min-Max缩放。
- 编码分类变量:如One-Hot Encoding或Label Encoding。
- 特征工程:创建新的特征,比如从文本中提取关键词或计算衍生指标。
-
数据降维(Dimensionality Reduction):如果数据维度过高,可能使用PCA(主成分分析)或LDA(潜在狄利克雷分配)等方法减少冗余。
-
数据划分(Data Splitting):将数据集分为训练集、验证集和测试集,用于模型的训练和评估。
-
数据采样(Sampling):对于大规模数据,可能需要进行随机抽样或分层抽样以平衡类别分布。
-
数据可视化(Exploratory Data Analysis, EDA):初步了解数据的分布、关联性和模式。
完成这些预处理步骤后,数据就准备好了供机器学习模型进行训练和预测。预处理的质量直接影响到分析结果的可靠性。
接下来进行一个小小案例讲解:
- 1、缺失值处理
python">#1、
#读取数据
import pandas as pd
data = pd.read_excel('学生信息表.xlsx')
#查看属性缺失值情况
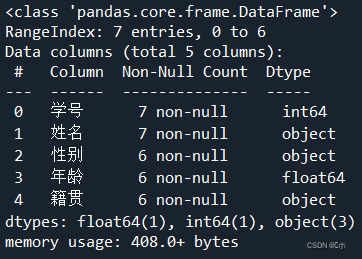
data.info()
data.isnull()
#删除“籍贯”为空的行
data = data.dropna(subset=["籍贯"])
#使用平均年龄填充“年龄”属性为空的数据
data['年龄'].fillna(data['年龄'].mean(),inplace=True)
#使用性别的众数填充“性别”属性为空的列
data.fillna({'性别':data['性别'].mode()[0]},inplace=True)- (1)读取“学生信息表.xlsx”。
-
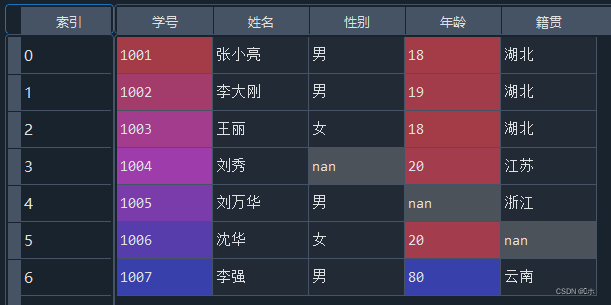
- (2)使用info()方法查看每一属性的缺失值情况。
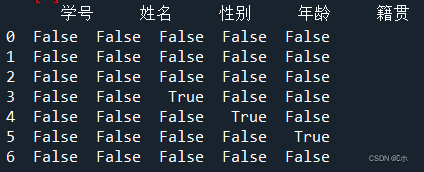
- (3)删除“籍贯”属性为空的行。
-
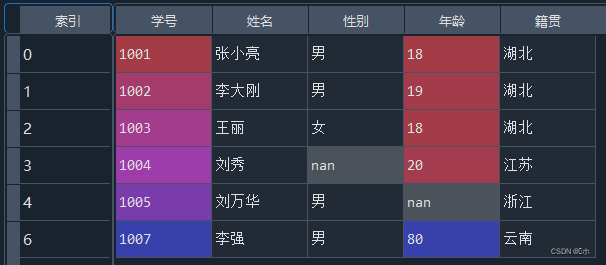
- (4)使用平均年龄填充“年龄”属性为空的数据。
-
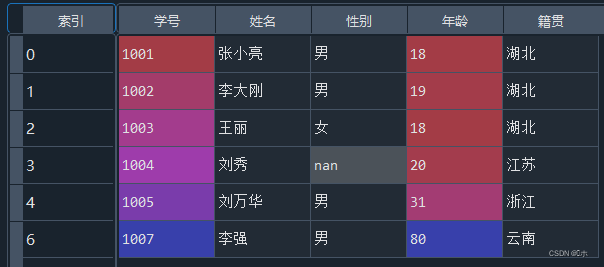
- (5)使用性别的众数填充“性别”属性为空的列。
-

- 2、非数值数据处理
-
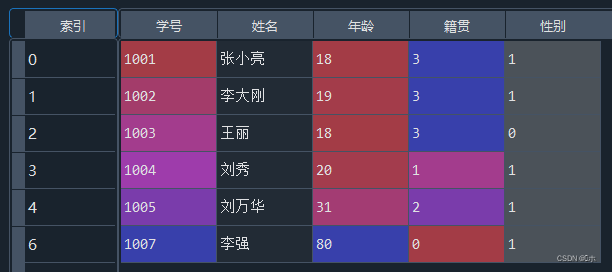
python">#2、 #将“性别”属性设置为哑变量,删除“性别_女”,并将“性别_男”改为“性别” data = pd.get_dummies(data,columns=['性别']) data = data.drop(columns = '性别_女') data = data.rename(columns={'性别_男':'性别'}) #对“籍贯”属性进行编号处理 from sklearn.preprocessing import LabelEncoder le = LabelEncoder() label = le.fit_transform(data['籍贯']) data['籍贯'] = label - (1)将“性别”属性设置为哑变量,删除“性别_女”,并将“性别_男”改为“性别”。
- (1为性别男,0为性别女)
-
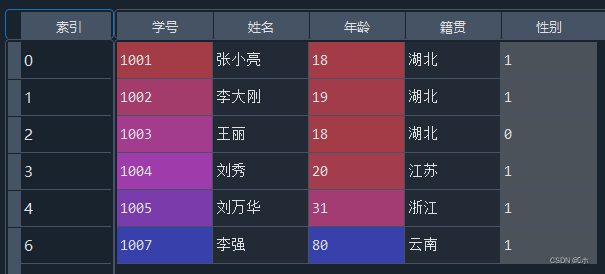
- (2)对“籍贯”属性进行编号处理。
- (0为云南;1为江苏;2为浙江;3为湖北)
-
- 3、异常值的处理
-
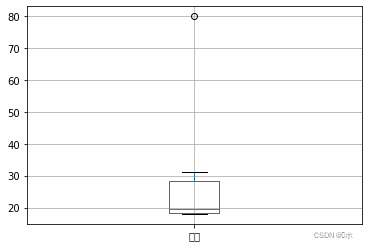
python">#3、 #箱线图观察“年龄”属性有无异常值 data.boxplot(column ='年龄' ) #对异常值进行标注,标注在out1属性中 import numpy as np data['out1'] = np.where(data['年龄'] < 30,0,1) #使用2倍标准差法标注异常值,标注在out2属性中 data['out2'] = abs((data['年龄']-data['年龄'].mean())/data['年龄'].std()) > 2 - (1)箱线图观察“年龄”属性有无异常值;
-
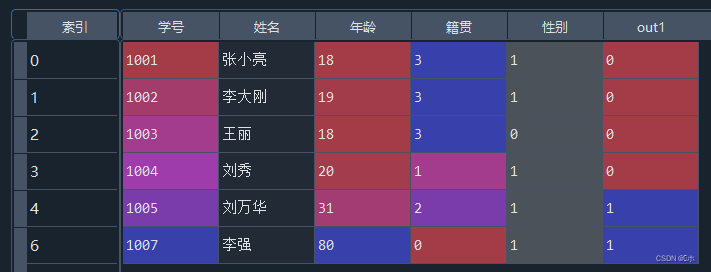
- (2)对异常值进行标注,标注在out1属性中;
-
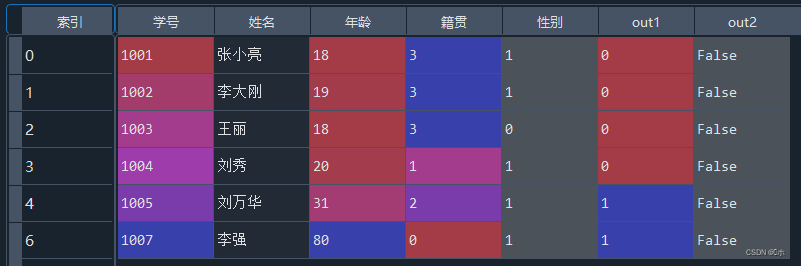
- (3)使用2倍标准差法标注异常值,标注在out2属性中。
-
- 4、数据标准化
-
python">#4、 #生成数据 data2 = pd.DataFrame({'酒精含量(%)': [50, 60, 40, 80, 90], '苹果酸含量(%)': [2, 1, 1, 3, 2]}) print(data2) #对各列进行z-score标准化 from sklearn.preprocessing import StandardScaler data2_new1 = StandardScaler().fit_transform(data2) print(data2_new1) #对各列进行min-max标准化 from sklearn.preprocessing import MinMaxScaler data2_new2 = MinMaxScaler().fit_transform(data2) print(data2_new2) - 如下数据:
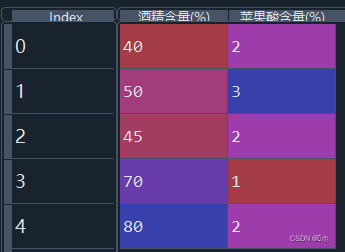
- (1)对以上数据的各列进行z-score标准化;
-
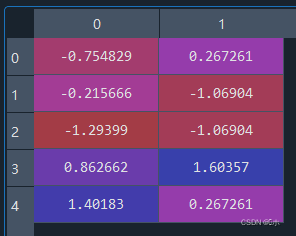
- (2)对以上数据的各列进行min-max标准化。
-
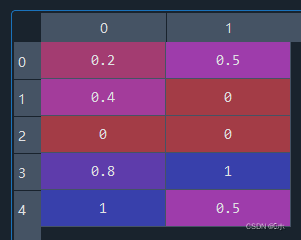
- 5、生成多项式特征
-
python">#5、 #生成多项式特征 from sklearn.preprocessing import PolynomialFeatures data3 = np.array([[2,3],[2,4]]) print(data3) pf1=PolynomialFeatures(degree=2) print(pf1.fit_transform(data3)) pf2=PolynomialFeatures(degree=2,include_bias=False) print(pf2.fit_transform(data3)) pf3=PolynomialFeatures(degree=2,include_bias=False,interaction_only=True) print(pf3.fit_transform(data3)) - 现在有(a,b)两个特征,生成二次多项式则为(1,a, b , ab, a^2, b^2),并用以下数据做测试:data3:
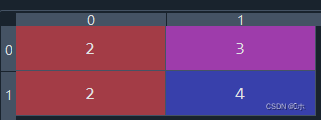
pf1:![]()
pf2:![]()
pf3:![]()