Basic flow control for RDMA transfers | The Geek in the Corner (wordpress.com)
名词解释
IB : InfiniBand的缩写,指的就是InfiniBand技术。
MAD : Management Datagram的缩写。MAD是InfiniBand架构中用于设备管理和配置的一种特殊消息传输格式。
RDMA: Remote Direct Memory Access的缩写。RDMA技术允许一台计算机直接访问另一台计算机的内存,而无需经过操作系统,极大地提高了数据传输的效率和速率。
LID: Local Identifier的缩写。在InfiniBand网络中,每个端口都会被分配一个LID,这是一个唯一的本地标识符,用于标识网络中的端口。
sm_lid : 这是指InfiniBand网络中的子网管理器(Subnet Manager)的LID。子网管理器负责管理InfiniBand网络中的地址和路由,确保数据能够正确地在设备间路由传递。
GID: Global Identifier的缩写。GID是一个全局唯一的标识符,用于标识InfiniBand网络中的节点或端口。一个GID包含了一个LID和一个GUID(全球唯一标识符),它是一种128位的地址,用于确保网络中设备的全球唯一性。
librdmacm(RDMA_CM):RDMA Connection Manager(RDMA连接管理器),是一个库,允许应用程序建立和管理RDMA连接。这个库提供了一组API,用于简化与RDMA硬件的交互,包括连接请求、监听和断开连接事件。`librdmacm`工作在用户空间,并通过系统调用与内核空间中的RDMA驱动程序交互。
Verbs:是一组API定义,用于通过InfiniBand硬件执行低级操作,如内存注册、队列对创建、发送和接收数据等。Verbs API直接对应于RDMA硬件的能力,因此它们是非常底层和强大的工具。
用户空间Verbs:是指应用程序直接使用的Verbs API,这些API允许用户空间程序直接与RDMA硬件交互,而不需要通过内核。这提供了最大程度的控制和效率,因为它避免了系统调用的开销。用户空间Verbs通常通过用户空间RDMA提供的库(如libibverbs库)来访问。
内核空间Verbs:是在内核模块或内核驱动程序中使用的Verbs API。内核空间的RDMA驱动程序负责实现与硬件交互的细节,提供给上层的系统资源,如虚拟文件系统或网络栈等内核子系统,可以通过内核空间Verbs API直接与RDMA硬件通信。需要注意的是,尽管用户空间Verbs API和内核空间Verbs API的目的是相似的——提供与RDMA硬件的直接交互——两者在使用方式、访问级别以及性能上会有差异。开发者在选择使用哪种API时,需要根据具体的需求和对性能的考量进行权衡。通常情况下,直接操作用户空间Verbs API会有更高的性能,因为用户空间的操作可以避免内核态和用户态之间的上下文切换开销。
IB卡传输数据前,需要交换一些信息。交换信息就需要IB卡之间通信。若不通过TCP/IP交换信息,采用的方式:(1)通过LID (ibv_devinfo命令结果的sm_lid);(2)通过GID(运行ibv_devinfo -vv,末尾GID[ 0]字段就是GID)。
文心一言
已经介绍了使用发送/接收操作和RDMA读写操作,那么现在是一个很好的机会来结合这两种方法的元素,并讨论一般的流量控制。还会稍微谈谈RDMA带有立即数据的写操作(IBV_WR_RDMA_WRITE_WITH_IMM),并且将通过一个示例来说明这些方法,该示例使用RDMA传输命令行中指定的文件。
示例包括一个服务器和一个客户端。服务器等待来自客户端的连接。客户端在连接到服务器后主要执行两个操作:它发送要传输的文件名,然后发送文件的内容。我们不会关注建立连接的细节;这些在之前的帖子中已经讨论过了。相反,我们将专注于同步和流量控制。不过,在本文中的代码结构上做了一些调整,与之前关于RDMA读写的帖子中的结构相反——在那里,将连接管理代码分别放在client.c和server.c中,而将完成处理代码放在common.c中。而在这里,将连接管理代码集中放在common.c中,并将完成处理代码分别放在client.c和server.c中。
回到示例。有许多方法可以从客户端向服务器传输整个文件。例如:
- 将整个文件加载到客户端内存中,连接到服务器,等待服务器发布一系列接收操作,然后在客户端端发起一个发送操作(send)以将内容复制到服务器。
- 将整个文件加载到客户端内存中,注册内存,将区域详细信息传递给服务器,让服务器发起RDMA读取操作将整个文件复制到其内存中,然后将内容写入磁盘。
- 与上述相同,但发起RDMA写入操作以将文件内容复制到服务器内存中,然后通知它写入磁盘。
- 在客户端打开文件,读取一个块,等待服务器发布接收操作,然后在客户端端发布一个发送操作,并循环直到整个文件被发送。
- 与上述相同,但使用RDMA读取操作。
- 与上述相同,但使用RDMA写入操作。
将整个文件加载到内存中对于大文件来说可能不切实际,因此将跳过前三个选项。在剩下的三个选项中,将专注于使用RDMA写入操作,以便可以说明RDMA带有立即数据的写入操作的使用,这是一直想讨论的一个话题。这种操作类似于常规的RDMA写入,但发起者可以将32位值“附加”到写入操作上。与常规RDMA写入不同,RDMA带有立即数据的写入要求在目标的接收队列上发布一个接收操作。当从目标的队列中拉取完成时,该32位值将可用。
12月26日:Roland D. 相当热心地指出,iWARP适配器不支持RDMA带有立即数据的写入。我们可以重写代码以使用RDMA写入(不带立即数据)后跟一个发送操作,但这留作读者的练习。
既然我们已经决定要将文件拆分成块,并将这些块一次一个地写入服务器的内存,我们需要找到一种方法来确保我们不会比服务器能够处理的速度更快地写入块。我们将通过服务器在准备好接收数据时向客户端发送显式消息来实现这一点。另一方面,客户端将使用带有立即数据的写入来向服务器发送信号。这个过程的大致顺序如下:
- 服务器开始监听连接。
- 客户端发布一个用于流量控制消息的接收操作,并启动到服务器的连接。
- 服务器发布一个用于RDMA带有立即数据的写入的接收操作,并接受来自客户端的连接。
- 服务器向客户端发送其目标内存区域的详细信息。
- 客户端重新发布一个接收操作,然后通过将文件名写入服务器的内存区域来响应。立即数据字段包含文件名的长度。
- 服务器打开一个文件描述符,重新发布一个接收操作,然后发送一个消息,指示它已准备好接收数据。
- 客户端重新发布一个接收操作,从输入文件中读取一个数据块,然后将该数据块写入服务器的内存区域。立即数据字段包含该数据块的大小(以字节为单位)。
- 服务器将数据块写入磁盘,重新发布一个接收操作,然后发送一个消息,指示它已准备好接收数据。
- 重复步骤7和8,直到没有数据要发送。
- 客户端重新发布一个接收操作,然后向服务器的内存发起一个零字节的写入操作。立即数据字段设置为零。
- 服务器发送一个消息,指示已完成操作。
- 客户端关闭连接。
- 服务器关闭文件描述符。
一个图表可能会有所帮助:
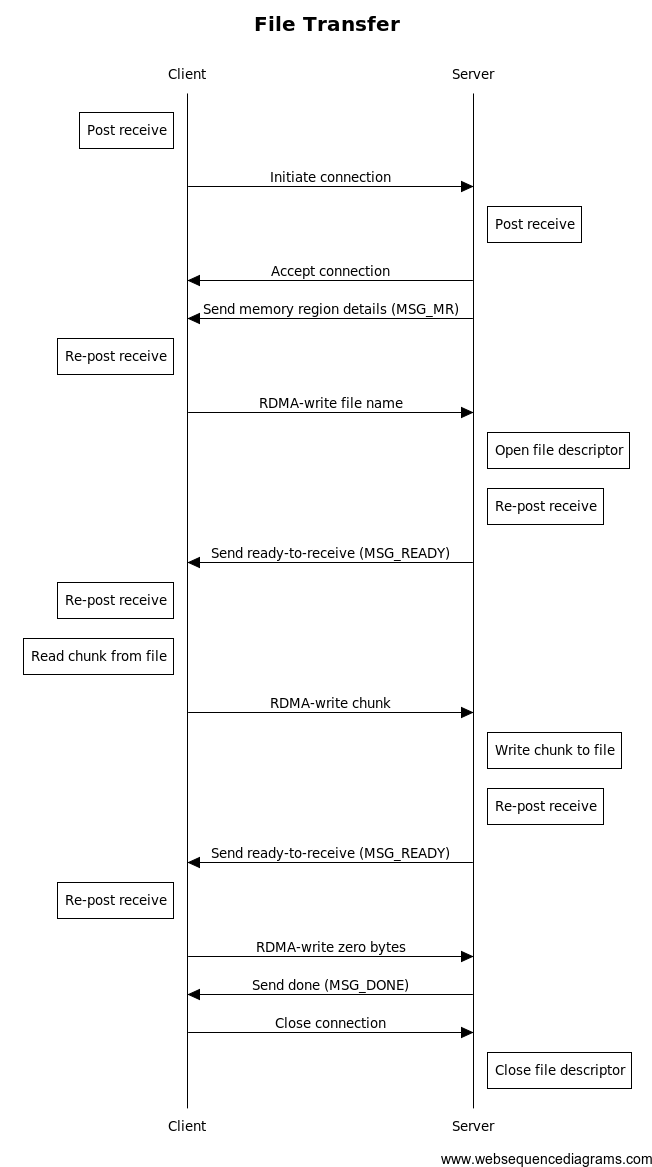
查看这个序列,我们可以看到服务器只向客户端发送小消息,并且只从客户端接收RDMA写入操作。客户端只执行RDMA写入操作,并且只从服务器接收小消息。
让我们从服务器开始看起。建立连接的细节现在隐藏在rc_init()函数之后,该函数设置了各种回调函数,以及rc_server_loop()函数,它运行一个事件循环:
int main(int argc, char **argv)
{rc_init(on_pre_conn,on_connection,on_completion,on_disconnect);printf("waiting for connections. interrupt (^C) to exit.\n");rc_server_loop(DEFAULT_PORT);return 0;
}回调函数的名称相当直观:on_pre_conn()在接收到连接请求但尚未接受连接时被调用,on_connection()在建立连接时被调用,on_completion()在从完成队列中拉取条目时被调用,而on_disconnect()在断开连接时被调用。
在on_pre_conn()中,我们分配一个结构体来包含各种连接上下文字段(一个缓冲区来包含来自客户端的数据,一个缓冲区用于向客户端发送消息等),并发布一个接收工作请求以接收客户端的RDMA写入操作:
static void post_receive(struct rdma_cm_id *id)
{struct ibv_recv_wr wr, *bad_wr = NULL;memset(&wr, 0, sizeof(wr));wr.wr_id = (uintptr_t)id;wr.sg_list = NULL;wr.num_sge = 0;TEST_NZ(ibv_post_recv(id->qp, &wr, &bad_wr));
}这里有趣的是我们设置了sg_list = NULL和num_sge = 0。传入的RDMA写请求将指定一个目标内存地址,由于这个工作请求只与传入的RDMA写请求匹配,所以我们不需要使用sg_list和num_sge来指定接收的内存位置。在连接建立后,on_connection()将内存区域的详细信息发送给客户端:
static void on_connection(struct rdma_cm_id *id)
{struct conn_context *ctx = (struct conn_context *)id->context;ctx->msg->id = MSG_MR;ctx->msg->data.mr.addr = (uintptr_t)ctx->buffer_mr->addr;ctx->msg->data.mr.rkey = ctx->buffer_mr->rkey;send_message(id);
}这促使客户端开始发出RDMA写入操作,这会触发on_completion()回调函数:
static void on_completion(struct ibv_wc *wc)
{struct rdma_cm_id *id = (struct rdma_cm_id *)(uintptr_t)wc->wr_id;struct conn_context *ctx = (struct conn_context *)id->context;if (wc->opcode == IBV_WC_RECV_RDMA_WITH_IMM) {uint32_t size = ntohl(wc->imm_data);if (size == 0) {ctx->msg->id = MSG_DONE;send_message(id);// don't need post_receive() since we're done with this connection} else if (ctx->file_name[0]) {ssize_t ret;printf("received %i bytes.\n", size);ret = write(ctx->fd, ctx->buffer, size);if (ret != size)rc_die("write() failed");post_receive(id);ctx->msg->id = MSG_READY;send_message(id);} else {memcpy(ctx->file_name, ctx->buffer, (size > MAX_FILE_NAME) ? MAX_FILE_NAME : size);ctx->file_name[size - 1] = '\0';printf("opening file %s\n", ctx->file_name);ctx->fd = open(ctx->file_name, O_WRONLY | O_CREAT | O_EXCL, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);if (ctx->fd == -1)rc_die("open() failed");post_receive(id);ctx->msg->id = MSG_READY;send_message(id);}}
}我们在第7行检索即时数据字段,并将其从网络字节顺序转换为主机字节顺序。然后我们测试三种可能的情况:
如果size == 0,则表示客户端已完成数据写入(第9-14行)。我们用MSG_DONE来确认这一点。
如果ctx->file_name的第一个字节被设置,则表示我们已经有了文件名并且有一个打开的文件描述符(第15-30行)。我们调用write()将客户端的数据追加到我们打开的文件中,然后用MSG_READY回复,表示我们已准备好接收更多数据。
否则,我们尚未收到文件名(第30-45行)。我们从输入缓冲区中复制它,打开一个文件描述符,然后用MSG_READY回复,表示我们已准备好接收数据。
在断开连接时,在on_disconnect()中,我们关闭打开的文件描述符并整理内存注册等。服务器的操作就是这样!
在客户端,main()函数稍微复杂一些,因为我们需要将服务器主机名和端口传递给rc_client_loop():
int main(int argc, char **argv)
{struct client_context ctx;if (argc != 3) {fprintf(stderr, "usage: %s <server-address> <file-name>\n", argv[0]);return 1;}ctx.file_name = basename(argv[2]);ctx.fd = open(argv[2], O_RDONLY);if (ctx.fd == -1) {fprintf(stderr, "unable to open input file \"%s\"\n", ctx.file_name);return 1;}rc_init(on_pre_conn,NULL, // on connecton_completion,NULL); // on disconnectrc_client_loop(argv[1], DEFAULT_PORT, &ctx);close(ctx.fd);return 0;
}我们不为连接或断开连接提供回调函数,因为这些事件对客户端来说不是特别相关。on_pre_conn()回调函数与服务器端的相当类似,除了连接上下文结构是预先分配的之外,我们发布的接收工作请求(在post_receive()中)需要一个内存区域:
static void post_receive(struct rdma_cm_id *id)
{struct client_context *ctx = (struct client_context *)id->context;struct ibv_recv_wr wr, *bad_wr = NULL;struct ibv_sge sge;memset(&wr, 0, sizeof(wr));wr.wr_id = (uintptr_t)id;wr.sg_list = &sge;wr.num_sge = 1;sge.addr = (uintptr_t)ctx->msg;sge.length = sizeof(*ctx->msg);sge.lkey = ctx->msg_mr->lkey;TEST_NZ(ibv_post_recv(id->qp, &wr, &bad_wr));
}我们将sg_list指向一个足够大的缓冲区,以容纳一个message结构体。服务器将使用这个缓冲区来传递流控制消息。每个消息都会触发对on_completion()的调用,这是客户端执行大部分工作的地方:
static void on_completion(struct ibv_wc *wc)
{struct rdma_cm_id *id = (struct rdma_cm_id *)(uintptr_t)(wc->wr_id);struct client_context *ctx = (struct client_context *)id->context;if (wc->opcode & IBV_WC_RECV) {if (ctx->msg->id == MSG_MR) {ctx->peer_addr = ctx->msg->data.mr.addr;ctx->peer_rkey = ctx->msg->data.mr.rkey;printf("received MR, sending file name\n");send_file_name(id);} else if (ctx->msg->id == MSG_READY) {printf("received READY, sending chunk\n");send_next_chunk(id);} else if (ctx->msg->id == MSG_DONE) {printf("received DONE, disconnecting\n");rc_disconnect(id);return;}post_receive(id);}
}这与上面描述的序列相匹配。send_file_name()和send_next_chunk()最终都调用了write_remote():
static void write_remote(struct rdma_cm_id *id, uint32_t len)
{struct client_context *ctx = (struct client_context *)id->context;struct ibv_send_wr wr, *bad_wr = NULL;struct ibv_sge sge;memset(&wr, 0, sizeof(wr));wr.wr_id = (uintptr_t)id;wr.opcode = IBV_WR_RDMA_WRITE_WITH_IMM;wr.send_flags = IBV_SEND_SIGNALED;wr.imm_data = htonl(len);wr.wr.rdma.remote_addr = ctx->peer_addr;wr.wr.rdma.rkey = ctx->peer_rkey;if (len) {wr.sg_list = &sge;wr.num_sge = 1;sge.addr = (uintptr_t)ctx->buffer;sge.length = len;sge.lkey = ctx->buffer_mr->lkey;}TEST_NZ(ibv_post_send(id->qp, &wr, &bad_wr));
}这个RDMA请求与之前帖子中描述的请求在两个方面有所不同:我们将操作码(opcode)设置为IBV_WR_RDMA_WRITE_WITH_IMM,并将imm_data设置为我们缓冲区的长度。
这并不难理解,对吧?如果一切正常,你应该会看到以下情况:
ib-host-1$ ./server
waiting for connections. interrupt (^C) to exit.
opening file test-file
received 10485760 bytes.
received 10485760 bytes.
received 5242880 bytes.
finished transferring test-file
^Cib-host-1$ md5sum test-file
5815ed31a65c5da9745764c887f5f777 test-fileib-host-2$ dd if=/dev/urandom of=test-file bs=1048576 count=25
25+0 records in
25+0 records out
26214400 bytes (26 MB) copied, 3.11979 seconds, 8.4 MB/sib-host-2$ md5sum test-file
5815ed31a65c5da9745764c887f5f777 test-fileib-host-2$ ./client ib-host-1 test-file
received MR, sending file name
received READY, sending chunk
received READY, sending chunk
received READY, sending chunk
received READY, sending chunk
received DONE, disconnecting如果你在内存注册期间遇到错误,比如以下错误,你可能需要增加你的锁定内存资源限制:
error: ctx->buffer_mr = ibv_reg_mr(rc_get_pd(), ctx->buffer, BUFFER_SIZE, IBV_ACCESS_LOCAL_WRITE) failed (returned zero/null).
OpenMPI的FAQ对如何设置锁定内存限制有很好的解释。
示例代码可以在这里找到。
12月21日:更新了帖子以描述锁定内存限制错误,并更新了示例代码以:检查ibv_reg_mr()的错误;使用文件路径的basename()而不是完整路径;在open()调用中添加缺失的模式参数;在Makefile中添加缺失的库引用。感谢Matt。
10月4日:示例代码现在位于https://github.com/tarickb/the-geek-in-the-corner/tree/master/03_file-transfer。

Kimi
这篇文章讨论了使用RDMA(Remote Direct Memory Access,远程直接内存访问)传输大量数据的基本流程控制。作者Matt最近询问了发送大于或等于2GB数据的方法。作者指出,尽管存在2^31的消息大小限制,但有多种有效的方法可以处理这个问题,考虑到内存资源有限,将跳过将整个文件加载到内存中的前三个选项。作者选择了使用RDMA写入操作来说明RDMA写入即时数据(IBV_WR_RDMA_WRITE_WITH_IMM)操作的使用,这是一种与常规RDMA写入类似的操作,但发起方可以附加一个32位的值。
文章提供了一个示例,包括服务器和客户端的代码,服务器等待客户端连接,客户端在连接后发送要传输的文件名,然后发送文件内容。文章重点讨论了同步和流程控制,而不是连接建立的细节。
以下是文章的中文翻译概要:
- 服务器和客户端结构:服务器等待连接,客户端在连接后发送文件名和内容。
- 流程控制:使用RDMA写入操作和即时数据来控制数据传输速度,确保不会比服务器处理速度快。
- 服务器代码:隐藏了连接建立的细节,通过回调函数处理连接请求、建立、完成和断开连接。
- 客户端代码:比服务器复杂,需要传递服务器主机名和端口,处理接收到的消息,并执行RDMA写入操作。
- 写入远程数据:客户端使用RDMA写入即时数据操作发送文件名和数据块。
- 错误处理:如果遇到内存注册错误,可能需要增加锁定内存资源限制。
文章最后提供了示例代码的链接,并在后续更新中修正了一些错误和遗漏。
请注意,这是文章内容的概要翻译,并非逐字翻译。如果需要更详细的翻译或对特定部分有疑问,请告知。

这是一篇关于使用RDMA(Remote Direct Memory Access,远程直接内存访问)进行大文件传输的讨论。评论者Matt最近询问了如何发送较大的数据量,例如大于或等于2GB的文件。他怀疑存在一种有效的方法来处理这个问题,因为消息大小有一个2^31的限制。他指出,他没有大量的内存可用,因为它被用于其他事情。
文章中提到了多种方法来协调从客户端到服务器的整个文件传输。包括将整个文件加载到客户端内存中,然后发送到服务器;或者使用RDMA读取或写入操作。但是,加载整个文件到内存对于大文件来说可能是不切实际的,所以我们将跳过前三个选项。在剩下的三个选项中,作者选择使用RDMA写入,这样可以展示RDMA-write-with-immediate-data操作的使用,这是他一直想讨论的内容。这种操作与传统的RDMA写入类似,但发起方可以“附加”一个32位的值到写入操作中。与常规的RDMA写入不同,带有立即数据的RDMA写入需要目标在接收队列上发布接收操作。当从目标队列中提取完成时,32位的值将可用。
文章还讨论了如何处理流控制,并提供了一个示例,说明如何使用RDMA传输命令行中指定的文件。示例包括服务器和客户端。服务器等待客户端的连接。客户端在连接到服务器后主要做两件事:发送它正在传输的文件的名称,然后发送文件的内容。文章不会涉及建立连接的细节,而是将重点放在同步和流控制上。
服务器端的代码示例包括初始化、接受连接、处理完成和断开连接的回调函数。客户端代码示例包括发送文件名和文件块,以及接收服务器的流控制消息。
文章最后提供了一个示例,展示了如何使用RDMA写入和立即数据来传输文件,并说明了服务器和客户端如何通过发送和接收消息来协调文件传输的过程。
请注意,由于网络原因,我无法访问提供的GitHub链接以验证示例代码。如果你需要查看示例代码,你可以访问提供的GitHub链接。此外,RDMA write with immediate data在iWARP适配器中可能不受支持,文章建议使用RDMA write(不带立即数据)后跟一个send操作,但这留给读者作为练习。
文章最后更新了一些关于锁定内存限制错误的描述,并更新了示例代码,以检查ibv_reg_mr()的错误,使用文件路径的basename()而不是完整路径,添加了open()调用中缺少的mode参数,以及在Makefile中添加了缺失的库引用。

这篇文章讨论了使用RDMA(Remote Direct Memory Access)传输大量数据的基本流程控制。评论者Matt最近询问了关于发送较大数据量(例如大于或等于2GB的文件)的问题。作者指出,尽管存在2^31的消息大小限制,但有多种有效的方法来处理这种数据传输,尤其是在内存资源有限的情况下。
文章中提到了几种可能的数据传输方式,包括将整个文件加载到客户端内存、使用RDMA读写操作等。但考虑到内存限制,作者选择了使用RDMA写操作,并特别提到了带有立即数据的RDMA写操作(IBV_WR_RDMA_WRITE_WITH_IMM),这种操作允许发送方附加一个32位的值到写操作中,并且需要目标方在接收队列中发布接收操作。
文章详细介绍了客户端和服务器的实现方式,包括它们如何同步和控制流程。服务器等待客户端的连接请求,而客户端在连接后发送要传输的文件名,然后发送文件内容。文章重点介绍了如何使用立即数据信号服务器,以及服务器如何显式地向客户端发送消息以表示它已准备好接收数据。
以下是文章的中文翻译摘要:
Matt最近询问了关于发送较大数据量的问题,例如发送大于或等于2GB的文件。作者提供了一些指针或示例,说明了如何发送大量数据。由于存在2^31的消息大小限制,作者提出了一种结合发送/接收操作和RDMA读写操作的方法来处理流程控制,并特别介绍了带有立即数据的RDMA写操作。
文章中的示例包括一个服务器和一个客户端。服务器等待客户端的连接,客户端在连接后主要做两件事:发送它要传输的文件名,然后发送文件内容。文章没有涉及建立连接的细节,而是专注于同步和流程控制。
作者选择了使用RDMA写操作来分解文件并逐个写入服务器内存,并使用立即数据信号来确保不会比服务器处理速度更快地写入数据。服务器通过发送显式消息来告知客户端何时准备好接收数据。
文章还提供了一个流程图来说明文件传输的顺序,包括服务器和客户端如何交互,以及它们如何使用RDMA写操作和立即数据来控制数据传输。
最后,文章提供了服务器和客户端的示例代码,展示了如何实现上述流程。如果在内存注册过程中遇到错误,可能需要增加锁定内存资源的限制。
文章的示例代码可以在GitHub上找到,链接已在文章中更新。
请注意,这是一个非常技术性的文章,涉及到特定的编程概念和网络协议。如果你需要更详细的翻译或对特定部分有疑问,请告知。

这篇文章讨论了使用RDMA(Remote Direct Memory Access,远程直接内存访问)传输大量数据的基本流程控制。评论者Matt最近询问了发送较大数据量(例如大于或等于2GB的文件)的方法。文章作者指出,尽管存在2^31的消息大小限制,但有多种有效的方法可以处理这种数据传输,尤其是考虑到Matt提到可用内存有限。
文章介绍了几种可能的文件传输方式,包括将整个文件加载到客户端内存中,然后发送到服务器;或者使用RDMA读取或写入操作。作者选择了使用RDMA写入操作,因为它可以展示RDMA-write-with-immediate-data(带有立即数据的RDMA写入)操作的使用,这是一种特殊的RDMA写入操作,允许发送方附加一个32位的值。
文章接着详细描述了客户端和服务器的交互流程,包括服务器监听连接、客户端发送文件名和文件内容、同步和流程控制等。服务器和客户端都使用特定的回调函数来处理连接请求、建立连接、完成队列中的条目以及断开连接。
文章还提供了一个示例代码,展示了如何使用RDMA写入操作和立即数据来传输文件。服务器和客户端的代码都进行了简化,以便专注于流程控制和同步机制。服务器代码隐藏了连接建立的细节,并运行了一个事件循环。客户端代码则需要传递服务器主机名和端口到循环中,并在接收到服务器的内存区域细节后开始发送文件名和文件内容。
最后,文章提到如果遇到内存注册错误,可能需要增加锁定内存资源限制,并提供了OpenMPI FAQ的链接来解释如何操作。文章还提到了示例代码的位置,并感谢了Matt和其他贡献者的帮助。