packagecom.shujia.mr.top3;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.TextInputFormat;importorg.apache.hadoop.mapreduce.lib.output.TextOutputFormat;importjava.io.FileNotFoundException;importjava.io.IOException;publicclassTop3{/*TODO:将项目打包到Hadoop中进行执行。*/publicstaticvoidmain(String[] args)throwsIOException,InterruptedException,ClassNotFoundException{// TODO MapReduce程序入口中的固定写法// TODO 1.获取Job对象 并设置相关Job任务的名称及入口类Configuration conf =newConfiguration();Job job =Job.getInstance(conf,"Top3");// 设置当前main方法所在的入口类job.setJarByClass(Top3.class);// TODO 2.设置自定义的Mapper和Reducer类job.setMapperClass(Top3Mapper.class);job.setReducerClass(Top3Reducer.class);// TODO 3.设置Mapper的KeyValue输出类 和 Reducer的输出类 (最终输出)job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Stu.class);job.setOutputKeyClass(Text.class);/*NullWritable是Writable的一个特殊类,实现方法为空实现,不从数据流中读数据,也不写入数据,只充当占位符,如在MapReduce中,如果你不需要使用键或值,你就可以将键或值声明为NullWritable,NullWritable是一个不可变的单实例类型。*/job.setOutputValueClass(NullWritable.class);// TODO 4.设置数据的输入和输出路径// 本地路径FileSystem fileSystem =FileSystem.get(job.getConfiguration());Path outPath =newPath("hadoop/out/new_top3");// Path outPath = new Path("/data/hadoop/out/new_top3");Path inpath =newPath("hadoop/out/reducejoin");// Path inpath = new Path("/data/hadoop/out/reducejoin");if(!fileSystem.exists(inpath)){thrownewFileNotFoundException(inpath+"不存在");}TextInputFormat.addInputPath(job,inpath);if(fileSystem.exists(outPath)){System.out.println("路径存在,开始删除");fileSystem.delete(outPath,true);}TextOutputFormat.setOutputPath(job,outPath);// TODO 5.提交任务开始执行job.waitForCompletion(true);}}
016条件查询之等量关系
条件查询语法格式
select ...
from...
where过滤条件;等于
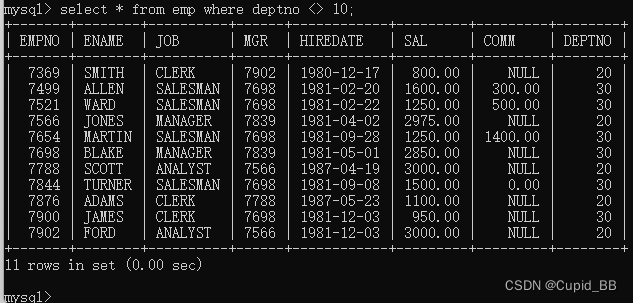
select empno, ename from emp where sal3000;select job, sal from emp where enameFORD;select grade, losal, hisal from salgrade where grade 1;不等于 <> 或 !
selectempno,en…