2020年高教社杯全国大学生数学建模竞赛C题 第三问详细解答+代码
本文摘自小编自己的参赛论文与经历,小编获得了2020年高教社杯国奖,有问题的同学们可私聊博主哦。
问题 三: 增加企业抗突发因素能力后 信贷策略 的 调整
1.1 问题分析
问题三要求我们把突发因素考虑在内,仍然是对 302 家无信贷记录的企业进行研究,因为缺少企业信誉评级,而问题三要求我们把突发因素考虑在内,那我们自然想到可以利用新增的突发因素代替企业信誉在信贷策略中所占有的地位,于是我们需要综合考虑企业实力和突发因素对企业的影响。为了能够量化突发因素对企业的影响,我们应该找到一个可以评判企业抗突
发因素的能力的指标,把这个指标与企业实力相结合,再来研究银行对企业的信贷策略。 从数据表格分析,我们发现公司企业的 行业与类别 不同主要体现在企业名字上,所以我们考虑到对公司名字进行处理分析,并结合“多元 化企业往往抗突发因素能力强,单一化企业往往抗突发因素能力弱” 和“规模大的企业抗突发因素强,规模小的企业抗突发因素能力弱” 的假设,对企业的抗突发因素能力进行了衡量。
1.2 数据预处理
数据初处理
在企业实力评价系数的计算方面,我们利用问题二中的预处理结果可以很容易计算得到企业实力的相关数据。考虑到突发因素对不同的企业有着不同的影响,所以我们必须对企业的名字进行一定的处理。在处理过程中,为了处理之后信息具有一定的有效性,我们必须保留能够反映公司规模大小以及行业类别的关键字,所以 我们 保留 了“公司”、 “发展中心 、“合作社”、 “厂”、“场”、“房”、“店”、“部”、“院”、“所”、“站”、 “分公司 以
及“个体” 等能反映 企业 规模的关键词,剔除了 “有限”、“股份”、“责任”、 “(有限合伙)”、 E***E***”以及 “******”等 既不能反映公司规模也无法体现公司行业类别的分词, 最后 并把每个公司对应的关键词 先 进行另存,方便后面的提 取 与利用。
数据二次处理
经过初处理的数据虽然已经含有了所有有效信息,但还知识一串文本信息,无法对文本中的关键词进行运用,因为我们后续计算需要用到“公司行业关键词”以及“公司规模关键词”所以必须对数据进行二次处理。首先我们对文本进行切词处理,将文本切分成一个个的关键词,因为“公司规模关键词”都在文本最后,所以我们把处理后得到的最后一个关键词转存到专门的表格中,然后把剩余关键词另存在另一个表格中,需要注意的是,我们数据处理时,发现有的文本既含有“公司”、又含有“分公司”,比如企业 E414 它的命名名字是“ 物流有限责任公司 分公司 ”,所以在处理时,处理了上述情况,这时候我们只 保留“分公司”一个关键词作为企业 E414 的“公司规模关键词”,并且不把“公司”纳入“公司行业关键词”中。考虑到
Excel 对 少量数据处理 的优越性, 我们在二次数据处理时,利用 Excel对 进行数据处理, 把公司行业关键词个数和公司规模关键词写入 表格, 处理后的表格数据作为我们后续计算的支撑。
1.3 企业抗突发因素能力
企业抗突发因素能力
突发因素突发因素往往具有突发性和难以 预见性、不确定性和非常规性、公共性和多样性 等特点。突发因素对不同的行业,不同类别的企业有着不同的影响,它的随机性和多元性也导致我们很难定性的描述突发因素的企业的影响。
指标选取
在已有的数据支撑之下,我们可以发现不同的企业有着不同的行业交叉度和广泛度,有的企业非常单一化只涉及一种行业,有的企业行业涉及面非常广,如下图 所示。

因为有关企业类别的数据较少,我们为了找到能够衡量企业抗风险能力的指标,在已有数据的基础上,选择企业的行业涉及面的广窄 以及企业的规模大小两个指标 来作为衡量企业抗风险能力的指标。
模型建立
记企业抗突发因素 能力为 A ,企业的规模大小系数为 S ,企业的行业 覆盖 强度 系数为 K ,我们给出企业抗突发能力的计算公式
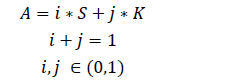
式中,i,j 分别代表了企业规模和企业的行业 覆盖 强度 在计算企业抗突发能力时的权重大小。
企业规模大小系数
在分析了表格数据后,我们发现对企业规模的描述有以下几类::“公司”、“厂”、“场”、“房”、“店”、“部”、“院”、“所”、“站”、“分公司”以及“个体”。为了能定量的计算企业规模大小,我们对企业规模划分为四类,每种企业规模对应的企业规模大小系数如表所示

为了保证计算得到的企业规模系数的有效性,我们沿用前边在计算是企业信誉评价系数时的思想,在计算企业规模大小系数时,在对应的区间随机取值。下面我们给出企业规模大小系数的计算公式:
𝑆=𝑟𝑎𝑛𝑑(𝑄)
其中,Q 代表企业对应的公司规模大小系数区间, rand 为在区间 Q 上产生随机数的函数。
行业覆盖度强度系数
在对 企业的行业覆盖强度系数 进行计算之前,我们首先明确 “多元化企业往往抗突发因素能力强,单一化企业往往抗突发因素能力弱”这一准则,根据处理后得到数据:“ 公司行业关键词”,我们提取表格中每个公司对应的关键词个数,记为 n, 通过数据分析,我们发现在 302 家企业中“公司行业关键词”的个数最小为 m in= 1 最大为 m ax= 4 。另外企业的行业覆盖
强度 从问题三来说仅受“公司行业关键词”的个数影响,其值基本不会受其他因素影响。考虑到数值的 量纲 问题,我们使 行业覆盖度强度系数 K 的值落在 0,1], 其中“公司关键词个数”为“ 1 2 3 4 ”的企业分别对应的系数 K 区间为 0,0.25 ],[0.25,0.5],[0.5,0.75],[ 基于此,我们给出企业的行业覆盖强度系数的计算公式:
𝐾=𝑟𝑎𝑛𝑑(𝐽)
其中J 是企业对应的行业覆盖强度系数区间。
1.4 信贷调整策略
1.4.1 信贷风险
问题三中虽然没有要求量化信贷风险,但是信贷策略模型求解过程时需要用到信贷风险的,所以我们还是要在问题三增加抗突发因素能力的情况下,对信贷风险进行量化,这里我们 就作简单描述。
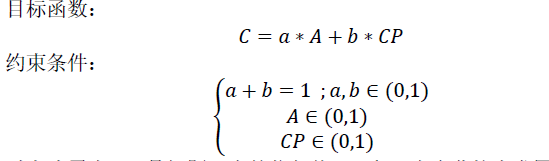
以上式 子 中, C 是问题三中的信任值, a 和 b 为 企业抗突发因素能力 以及 实力 的权重系数 CP 和 A 是企业实力和的 企业抗突发因素能力 。
关于企业实力的计算和第一问的计算方法一致,这里我们就不作过多赘述。
1.4.2 是否放贷
问题三与问题二不同之处在于,在衡量企业信贷风险时加入了企业抗突发因素能力 A ,问题三与问题一在信贷风险计算时都是用两个因素来衡量,所以我们采取与问题一 相同的模型,对问题三进行求解。不同之处在于信誉评级这一指标替换为企业抗突发因素能力。
为了描述放贷的可能性,我们定义p 为放贷可能性, p0 为允许放贷的最低阈值,其中 p 由信贷风险和供求关系决定,其中放贷与否我们用 0/1 来表示, 1表示放贷, 0 表示不放贷。

其中C 是 问题三中的信任 值, 其值由企业抗突发因素能力和企业实力决定,C 的值越大, 说明 企业抗突发因素能力 和企业实力 就越强,放贷可能性就越高。G 为供求稳定系数, a,b 分别为信贷风险和供求稳定性在放贷可能性计算中的权重 其中 G 和 C 的范围均为( 0,1 。问题三中供求稳定系 数和问题二中的供求稳定系数都是针对无信贷企业 而言的 ,所以这里我们不在对供求稳定系数的计算过程进行赘述。
1.4.3贷款额度,利率与贷款期限
问题三与问题二都不含企业信誉评级,所以在求解银行利润最大化模型时,都不考虑客户流失率,但是,问题三中的信任值由企业实力和企业抗突发因素能力,所以信任值 C 的计算方法和问题二是不同的, 在进行利率变动计算时,得到的结果规律 是 不同的。因为问题三中的利率变动公式同问题 二 ,所以这里我们不再给出利率变动公式, 但是问题二中的模型和算法可以沿用到问题三中,下面我们给出具体的模型:
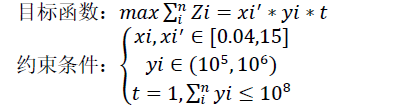
问题三沿用模拟退火算法对模型进行求解,其中参数的设置和模拟退火算法的过程和问题二是一致的,这里我们不再对模拟退火的具体求*解进行阐释。
1.4.4结果 分析
我们仍然 取企业放贷可能性的平均值作为 𝑝0,通过计算比较,发现共 163 个企业获得了贷款资格。依据利润模型,通过反复运行代码,在模拟退火算法的不断迭代之后,我们找出了银行在在受 突发 因素 影响 的利润最大值 大概在 1080 万 ,给出了此时银行对于每个企业的信贷策略。部分企业的信贷利率和信贷额度如表 所示,模拟退火算法运行寻找最优
解的迭代过程如图所示。

从模拟退火算法迭代图来看,在寻找最优解的过程中,前期搜索范围较大,所得到的利润不是很大,随着迭代次数的增加利润的最优值逐渐稳定,最后在1060 万附近微小波动。
以上是问题三的全部分析与结果,部分代码如下:
Matlab部分代码
%第三题计算包含企业规模,企业营业范围,收益实力,供求稳定的风险系数
keywords=xlsread('附件2:302家无信贷记录企业的相关数据.xlsx',1,'C2:C303');
big=xlsread('附件2:302家无信贷记录企业的相关数据.xlsx',1,'E2:E303');
r_key=zeros(302,1);
r_big=zeros(302,1);
for i=1:302if keywords(i)==1r_key(i)=0+(0.25-0)*rand(1);elseif keywords(i)==2r_key(i)=0.25+(0.5-0.25)*rand(1);elseif keywords(i)==3r_key(i)=0.5+(0.75-0.5)*rand(1);elseif keywords(i)==4r_key(i)=0.75+(1-0.75)*rand(1);end
end
for j=1:302if big(j)==4r_big(j)=0+(0.25-0)*rand(1);elseif big(j)==3r_big(j)=0.25+(0.5-0.25)*rand(1);elseif big(j)==2r_big(j)=0.5+(0.75-0.5)*rand(1);elseif big(j)==1r_big(j)=0.75+(1-0.75)*rand(1);end
end
xlswrite('处理:302家无信贷记录企业的相关数据.xlsx',r_key,3,'H2:H303');
xlswrite('处理:302家无信贷记录企业的相关数据.xlsx',r_big,3,'I2:I303');%此处用规模实力,营业范围实力,第二问放贷指数加权来计算第三问的放贷指数
r_second=xlsread('处理:302家无信贷记录企业的相关数据.xlsx',3,'F2:F303');
r_fd_third=0.7*r_second+0.2*r_key+0.1*r_big;
xlswrite('处理:302家无信贷记录企业的相关数据.xlsx',r_fd_third,3,'J2:J303');
aver=mean(r_fd_third); %第三问放贷指数的平均值
decide=zeros(302,1); %设置第三问是否放贷的初始列
for k=1:302if r_fd_third(k)>averdecide(k)=1;elsedecide(k)=0;end
end
xlswrite('处理:302家无信贷记录企业的相关数据.xlsx',decide,3,'K2:K303');
%可放贷企业信息提取
name=xlsread('处理:302家无信贷记录企业的相关数据.xlsx',3,'A2:A303');
zhishu=xlsread('处理:302家无信贷记录企业的相关数据.xlsx',3,'J2:J303');
fd_shu=sum(decide); %确定放贷企业个数有163个qy_name=zeros(163,1);
qy_zhishu=zeros(163,1);
n=0; %企业信息存储时用的索引
for i=1:302if decide(i)==1n=n+1;qy_name(n)=name(i);qy_zhishu(n)=zhishu(i);end
end
xlswrite('可贷款企业信息.xlsx',qy_name,2,'A2:A164');
xlswrite('可贷款企业信息.xlsx',qy_zhishu,2,'B2:B164');r=1-qy_zhishu; %放贷风险=1-可放贷指数
aver_r=mean(r); %得出aver_r=0.4201,max_r=0.4717 ; min_r=0.1109
%确定有优惠政策时,初始的利率范围
%由方程exp(r-aver_r)*x=0.04+(0.15-0.04)*rand(163,1);
%计算范围的方程xmax=0.15/exp(max_r-aver_r); xmin=0.04/exp(min_r-aver_r)
%可得利率x的范围:0.0545=<x<=0.1425
%给每个企业放贷所得利润:z(i)=exp(r(i)-aver_r)*x(i)*y(i)
%银行所得总利润 w=sum(z)
%计算向企业放贷时银行所得利润
z=zeros(163,1);
f=zeros(163,1);
w=zeros(100000,1);
max_lirun=0;
%以下确定较好的初始解
count=0;
for t=1:100000x=0.0545+(0.1425-0.0545)*rand(163,1);y=10*10^4+(100-10)*10^4*rand(163,1);if sum(y)<=10^9count=count+1;for j=1:163z(j)=exp(r(j)-aver_r)*x(j)*y(j);w(count)=w(count)+z(j);endelse continue;endif count==1max_lirun=w(count);fenpei_x=x;fenpei_y=y;index=count;elseif count>1if w(count)>w(index)max_lirun=w(count);fenpei_x=x;fenpei_y=y;index=count;endend
end点赞并关注博主可获得完整代码哦,有问题可随时私信博主相互交流学习哦。