文章目录
- 前言
- 关于更新
- python 编码规范
- 命名类
- 类名称需要使用驼峰命名
- 函数中的变量需要使用小写
- 外部作用域的重复命名
- 排版类
- PEP 8: 文件末尾没有新的行
- PEP 8: 太多的空行
- PEP 8: 单行代码长度过长
- PEP 8: 代码缩进不是4的倍数
- PEP 8: 操作符前后未留空白
- 编码类
- 不合适的列表/字典变量定义
- 移除多余的小括号
- 导入依赖未使用
- 在__init__.py文件中找不到引用
- 在类__init__方法之外初始化成员变量
- 大量重复的代码块
- 不明确的异常捕捉
- 子类重写/重载警告
- 重写 / 重载
- 定义的变量未使用
- 子类必须实现所有的抽象方法
- 关于ABC抽象基类的延伸
- 写在最后
- 比通用规范更重要的
- 另一个目的
- 参考
- 更新
前言
作为Pycharm的忠实使用者,在平时的开发过程当中,你是否有注意过编辑界面左侧的高亮提醒呢?是否在某个夜深人静的时候,打开公司项目代码的某个文件,看到排山倒海一般的黄色小条条,感到头皮发麻呢?

解决方法来了!!!!!
点击左下角的小人(最新版这个功能貌似换到左上角并且不是小人了,我还挺喜欢这个小人的…)

世界清静了(大雾)!

但真的就此可以放心了吗,戴帽小人的回眸一笑,究竟是人性的泯灭,还是道德的沦丧!!?
今日说码,就来带你一探究竟(并不,歪嘴笑)

言归正传,到底是写出了什么样的代码,会让Pycharm契而不舍的去一遍遍高亮提醒你呢?
这就要从python的语言规范PEP8(加上其他一堆语法检查)说起了。
关于更新
本篇中,笔者列举了一些平时开发中经常遇到的规范问题,可(肯)能(定)列举的不全,故而这篇博文会保持持续更新,为了不影响阅读,更新日志放到了本篇的最后(记录博客更新日志个人觉得是个好习惯,233)~
python 编码规范
PEP8 是Python社区通用的风格指南,一开始是Python之父龟叔(Guido van Rossum)自己编写代码风格,后来慢慢演变至今,逐渐形成一套较为成熟的编码规范。其目的在于帮助开发者写出可读性高且风格一致的代码。许多开源项目,例如 Django、OpenStack等都是以PEP8为基础再加上自己的风格建议。
Pycharm则将这套规范植入了自身并对开发者的代码语法加以监测,促进开发者写出符合规范的python代码。
命名类
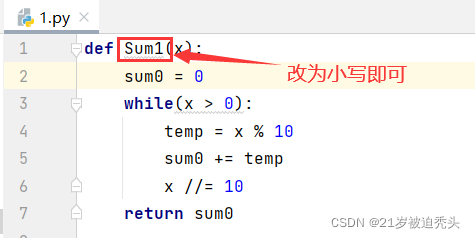
类名称需要使用驼峰命名
Class names should use CamelCase convention

(起名真是编程界的一大难题)
提示中表示,当我们定义python类时,应该使用驼峰命名——CamelCase,即单词组合中首字母需要大写。故而我们在命名时,图上的名称应改为SeriesSquareCompeted
函数中的变量需要使用小写
Variable in function should be lowercase

与上面一条相对应,我们对函数或方法中变量的命名,建议是使用下滑线命名法,对应图上的变量的名称,应改为org_id
外部作用域的重复命名
Shadows name 'use_a' from outer scope

出现这个提示,表示当前代码不同作用域中重复使用了同样的变量名。最常出现的情况就就是方法中的函数变量和__main__下面的变量出现重名。通常情况下,这不会出现什么问题,但事实上这种做法会带来潜在的风险。
来看看下面这段代码:
def sample_func(*args):sample = 2 # note the misspelling of `sample here`print(sample * sample)if __name__ == "__main__":for sample in range(1, 5):sample_func()
运行这段代码,会打印出什么呢?
运行结果:
4
4
4
4
可以看出,结果是符合预期的,因为局部变量sample覆盖了全局变量sample,此时sample就被pycharm定义为一个shadow name,无论__main__下如何赋值,打印结果都是4。
那么这样写的潜在问题是什么呢?试想一下一个很复杂的很业务,其中用到了全局变量sample,在某个方法中,又存在一个名称相同的局部变量sample。如果出于编码需要,该方法内的局部变量sample需要进行替换。而你因为不小心漏改了一个地方,那么漏改的部分就会跑去引用全局变量sample,从而导致逻辑发成混乱(由于引用关系看上去“完全正确“,所以pycharm也不会报引用错误)
def sample_func(*args):smaple = 2# 注意这里第二个sample忘改了,但是并不会报错,但跑出来的结果就完全不符合预期了print(smaple * sample)if __name__ == "__main__":for sample in range(1, 5):sample_func()
排版类
排版类的提示基本都是为了对代码文件进行规范,遵循其规范有助我们写出更加干净的代码
PEP 8: 文件末尾没有新的行
PEP 8: W292 no newline at end of file

这个好说,PEP8要求我们在代码的最后在空出一行,一个回车加一行搞定
PEP 8: 太多的空行
PEP 8: E303 too many blank lines (2)

这个规范对每行代码之间的间隔进行了定义,简单来说:
- 函数之间,类之间一般要空2行
- 类方法之间一般空1行
- 函数/方法代码内部每行间隔不超过1行
PEP 8: 单行代码长度过长
PEP 8: E501 line too long (166 > 150 characters)

PEP8对单行代码的长度进行了限制,事实上这个长度可以在Pycharm中设置~~
PEP 8: 代码缩进不是4的倍数
PEP 8: E111 indentation is not a multiple of four

这个属于python的基本规范了,python要求我们的代码缩进是4个空格或者4的倍数,运行图上这段代码,并不会出错(但是如果后面的代码缩进与前面不一致,就会出现语法错误)。项目中如果出现了不合规范的缩进,应及时修复。
PEP 8: 操作符前后未留空白
PEP 8: E225 missing whitespace around operator

啊哈,又一个格式上的问题,简而言之,我们在操作符两边需要各预留一个空格。
但是在传关键字参数时,不需要这么做,比如
sample = SampleClass(method=1)
这时=两边加上空格会报PEP 8: E251 unexpected spaces around keyword / parameter equals的警告
编码类
不合适的列表/字典变量定义
This list creation could be rewritten as a list literal

示例代码:
def sample_func(*args):a = [] # This list creation could be rewritten as a list literal a.append(1)b = {} # This list creation could be rewritten as a list literal b['super'] = 'man'
这里Pycharm提示我们应该将a重新定位为一个列表的实例,笔者之前都是这么干的
def sample_func(*args):a = list()a.append(1)b = dict()b['super'] = 'man'
而实际上,我们可以这么改
def sample_func(*args):a = [1]b = {'super': 'man'}
我们在定义列表和字典时直接将值填进去,这也是较为通常的做法,并且较前者代码更少,性能更好。
当然,如果项目中为了可读性,或者其他原因需要使用第一种的写法,那么直接忽略Pycharm的提示即可。
移除多余的小括号
Remove redundant parentheses

python3中,定义类是默认是继承object的,你可以显示在括号中继承object, 但如果我们不需要继承其他类,那么还是掉多余的括号吧:)
导入依赖未使用
Unused import statement 'import xxx'

导入了这个库,却又不用,我帮你删了应该没意见吧(狗头保命)
在__init__.py文件中找不到引用
Cannot find reference 'xxx' in __init__.py

字面上看是没有找到引用,这个算是Pycharm的一个bug吧,Pycharm希望所有的模块都被包含在__init__.py当中的__all__ = []当中,实际上不这么做,也并不会影响调用。(当然不排除是真的找不到了,所以Pycharm只是给个口头警告~)
在类__init__方法之外初始化成员变量
Instance attribute a defined outside __init__

这个警告表示代码违反了SRP(Single Pesponsibility Principle, SRP) 原则,我们可以理解为成员变量初始化的工作应该在一个单独的方法(def __init__())中完成,其他方法不应做初始化的操作。
规范虽如此,但是我们仍然可以看到很多项目中会在__init__之外初始化成员变量,也有人认为这些变量只有某一个方法才会使用,不应放到__init__做初始化,这个就见仁见智了。
大量重复的代码块
Duplicated code fragment (xx lines long)

出现这个提示说明Pycharm检测到你项目中存在重复的代码段,如果对项目整洁度有要求的话,可以考虑一下是否能够将这些重复的代码抽象出来,形成一个方法或者函数,从而减少冗余。
如果不需要,直接忽略也是一个选择。
不明确的异常捕捉
PEP 8: E722 do not use bare 'except'

在使用try....except语法时,如果我们不能清楚了解到代码在什么场景下会出现什么异常,以及异常后应该如何去进行处理,就不应该简单的使用一个Exception用来捕获所有异常,因为不同的异常可能需要不用的逻辑去处理。
子类重写/重载警告
Signature of method 'XX.xx()' does not match signature of base method in class 'XXX'
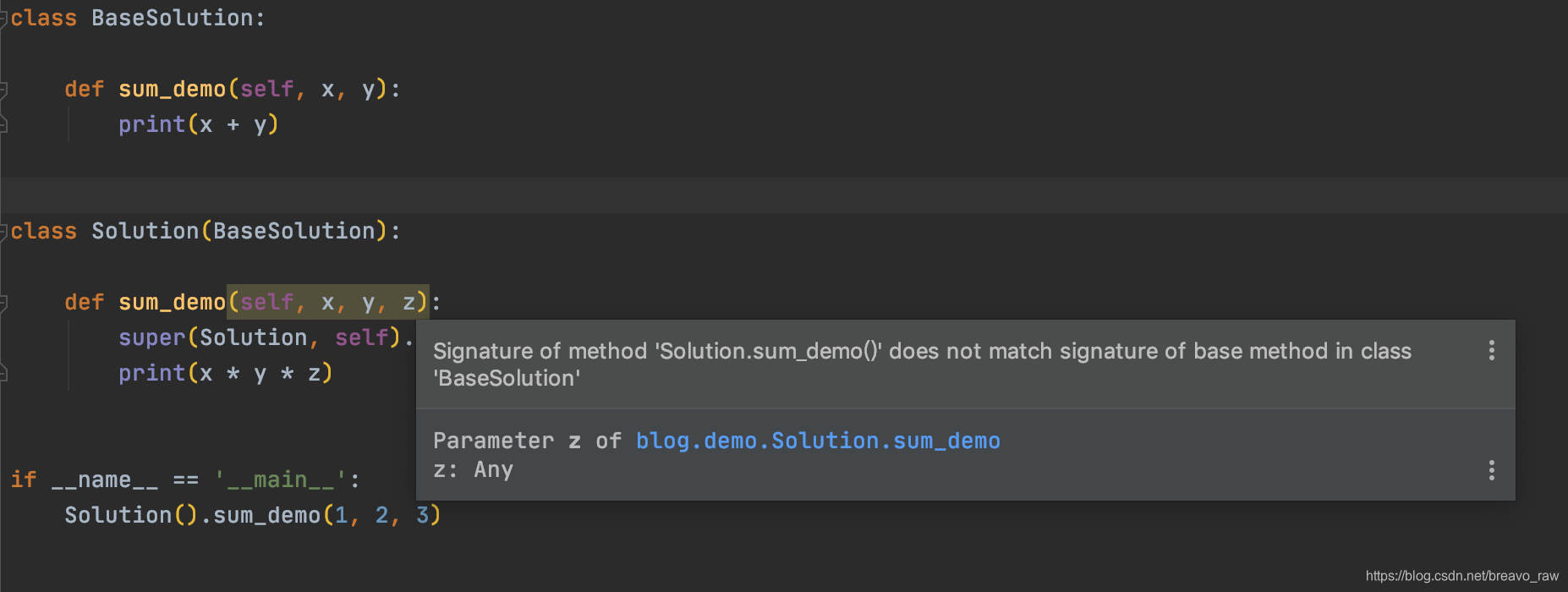
在实现类,继承父类的过程中,自然会有修改父类方法的需求,这就涉及到了面向对象编程中重写,重载的概念。让我们简单的回顾一下:
重写 / 重载
重写
- 重写是子类对父类的允许访问的方法的实现过程进行重新编写,
返回值和形参都不能改变。即外壳不变,核心重写! - 重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
- (注意:这个是java才有的,我在python里尝试了一下,好像并没有啥问题?)重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。例如: 父类的一个方法申明了一个检查异常
IOException,但是在重写这个方法的时候不能抛出Exception异常,因为Exception是IOException的父类,只能抛出IOException的子类异常。
重载
- 重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
- 每个重载的方法都必须有一个独一无二的参数类型列表。
概念复习完了,那么在python里面,我们对父类方法进行重载,却出现了上述的警告,是为什么呢?
其实主要是因为我们给子类增加了参数,与父类的方法相比出现了不一致(当然会不一致,重载的目的就在于此),但这违反了LSP原则(即我们在使用父类的场景下,将其替换为子类的方法,也一样可行)。现在这么写,把调用父类的方法替换成子类方法的时候就直接报参数错误了~
解决方式也很简单,在子类重载的方法中为新增的参数添加默认值赋值,这样就确保了父类方法中定义的参数在子类中一定不会失效从而确保了自上而下的一致性。
像这样
可以看到,警告已经消失了,强迫症患者的福音~~
定义的变量未使用
这个变量可能是函数的入参,也可能隐藏在某段代码中~
方法的参数未使用(即使你用不上他,你还是得传一个进去,否则就会报错,难受)

本地变量未使用

但是不管他们在哪儿,如果你后面没有使用到他们,最好还是去掉(写的时候就要注意把不要的去掉,要是一直不管,后面真的看着不爽~)
子类必须实现所有的抽象方法
Class xxx must implement all abstract methods

这里以笔者的使用的tornado框架为例,在继承RequestHandler时,pycharm会提示我们还有未实现的抽象方法,点击Implement abstract methods之后会告诉我们哪些抽象方法没有实现

看来确实有一个叫data_received的方法,那么为什么这个方法会被检测出来呢?我们直接深入到该方法看看,在源代码web.py文件中,我们找到了该方法
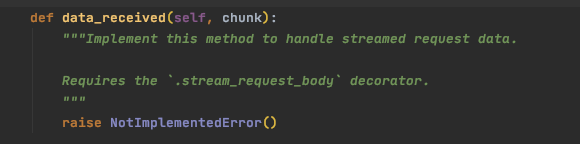
可以看到,这个方法直接抛出了一个 NotImplementedError,而这样的方法会被Pycharm检测为抽象方法,并希望所有继承这个类的子类都需要去实现它,除此之外,pycharm也会检测使用@abc.abstractmethod装饰器装饰过的方法,该装饰器的功能就是将一个方法定义为抽象方法
如何处理这样的提示,有两个解决方案
- 如果确实继承的子类有实现父类抽象方法的需求,不实现会导致问题的话,那么OK,实现它~
- 如果这个方法在子类中完全没有用到的话,我们可以忽略这个提示,在
settings->inspections中找到
取消勾选即可 :)
关于ABC抽象基类的延伸
如果在子类中加入__metaclass__ = ABCMeta 这一句,同样可去除提示,但从含义上来讲是不推荐这样做的,推荐阅读 abc — 抽象基类(官方文档) ,确认了解了其真正的含义后,在进行使用~
写在最后
比通用规范更重要的
大多数时候,你不得不忍受和通用规范不一样的代码风格,因为比起通用规范,更重要的是项目本身的风格一致性。在一个模块或函数的风格一致性是最重要的。
为了与通用规范保持强一致,从而大量修改原有的代码是不可取的,并且这是一个很令人沮丧的行为,因为你根本改不完,这个时候,编码规范的建议就不适用了。
这个时候我们可以通过Pycharm的忽略功能对一些规范进行忽略(假装看不见…),具体设置在
Preference --> Editor --> Inspections
下,我们也可以直接在出现警告的地方点击提示进行忽略。
这里有几个很好的理由去忽略特定的规则:
- 当遵循这份指南之后代码的可读性变差,甚至是遵循PEP规范的人也觉得可读性差。
- 与周围的代码保持一致(也可能出于历史原因),尽管这也是清理他人混乱(真正的Xtreme Programming风格)的一个机会。
- 有问题的代码出现在发现编码规范之前,而且也没有充足的理由去修改他们。
- 当代码需要兼容不支持编码规范建议的老版本Python。
另一个目的
本篇的另一个目的,是为了告诉读者,尽管Pycharm的代码规范和语法检查并不适用于所有场景,但是当他们出现时,我们仍需要保持一颗敬畏之心,充分了解警告背后的真实原因,这样更加有助于我们在建立起适合自己项目的代码规范。
参考
Python PEP8 编码规范中文版
PEP8 PYTHON 编码规范手册
骆驼命名法,帕斯卡命名法与下划线命名法
python PEP8
stackoverflow
pycharm learning center
更新
| 时间 | 内容 |
|---|---|
| 2020-09-07 | 1. 将标题的英文提示换成中文提示(英文提示放到了每个中文提示标题的下面) 2. 新增重复代码提示 |
| 2020-11-28 | 1. 更改了一下 不明确的异常捕捉 下的描述(使其更准确) 2. 增加了子类重写/重载警告 |
| 2020-12-15 | 1. 调整了一下格式 2. 新增 未使用的变量和参数 提示描述 |
| 2020-12-25 | 1. 增加了子类必须实现所有的抽象方法警告 2. 将更新内容以表格形式展示(排版好看了许多,瞬间高大上了哈哈哈哈) |
 |