早期 对外采购mobileye EyeQ3 芯片+摄像头半集成方案,主要是为了满足快速量产需求,且受制于研发资金不足限制;
中期 采用高算力NVIDIA 芯片平台+其他摄像头供应商的特斯拉内部集成方案,mobileye开发节奏无法紧跟特斯拉需求;
当前:采用自研NPU(网络处理器)为核心的芯片+外采Aptina摄像头的特斯拉核心自研方案,主要原因在于市面方案无法满足定制需求,而后期时间和资金充足,公司自研实力和开发自由度更高。
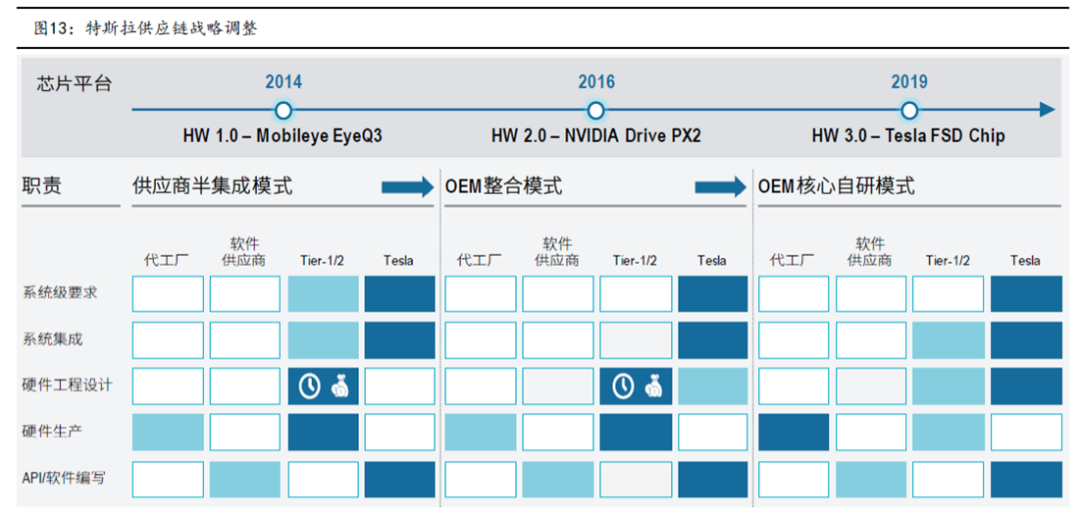
为了掌握自动驾驶话语权,同时并掌握核心数据和AI算法,过去5年特斯拉经历了外购主控芯片到自研的道路。2014年~2016年,特斯拉配备的是基于Mobileye EyeQ3芯片的AutoPilot HW1.0计算平台,车上包含1个前摄像头+1个毫米波雷达+12个超声波雷达。2016年~2019年,特斯拉采用基于英伟达的DRIVE PX 2 AI计算平台的AutoPilot HW2.0和后续的AutoPilot HW2.5,包含8个摄像头+1个毫米波雷达+12超声波雷达。
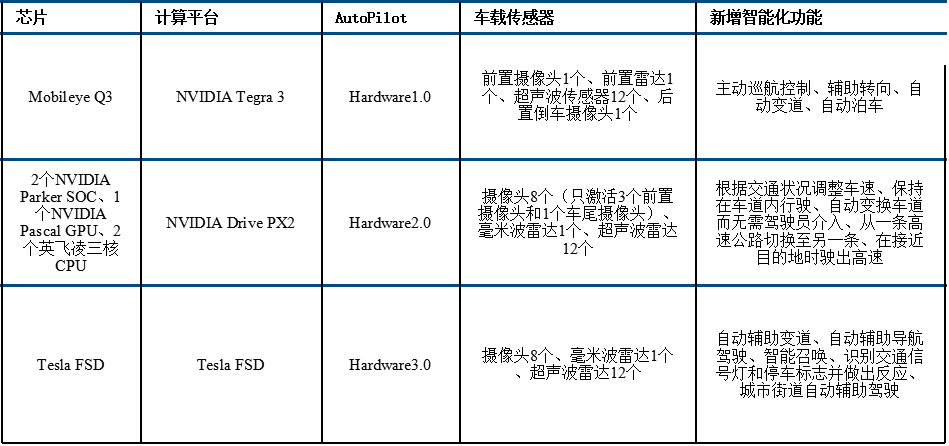
2017年开始特斯拉开始启动自研主控芯片,尤其是主控芯片中的神经网络算法和AI处理单元全部自己完成。2019年4月,AutoPilot HW3.0平台搭载了Tesla FSD自研版本的主控芯片,这款自动驾驶主控芯片拥有高达60亿的晶体管,每秒可完成144万亿次的计算,能同时处理每秒2300帧的图像。

特斯拉的FSD HW3.0基本介绍
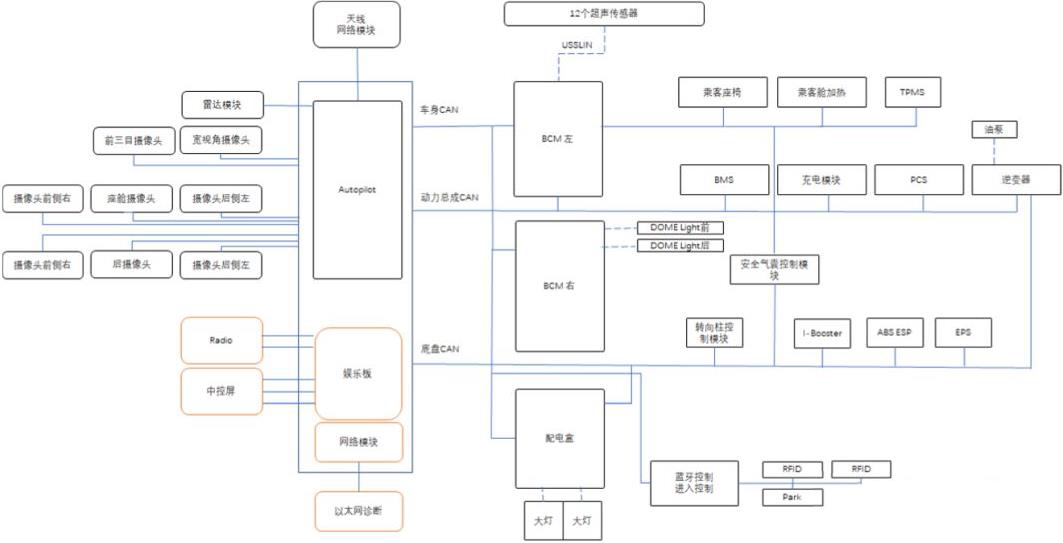
特斯拉Model 3自研“中央-区EEA”架构:中央计算机是自动驾驶及娱乐控制模块(Autopilot & Infotainment Control Module),由两块FSD芯片承担大量的数据计算,主要服务于自动驾驶功能。两个区控制器分别是右车身控制器(BCM RH)和左车身控制器(BCM LH),主要服务于热管理、扭矩控制、灯光等功能。
FSD 的 HW3.0 由两个相同的计算单元构成,每个计算单元上面有特斯拉自研的2 块FSD计算芯片,每块算力位 36 Tops,设备总算力位 4 x 36 Tops = 144 Tops。但是由于采用的是双机冗余热备的运行方式,实际可用的算力为72 Top。
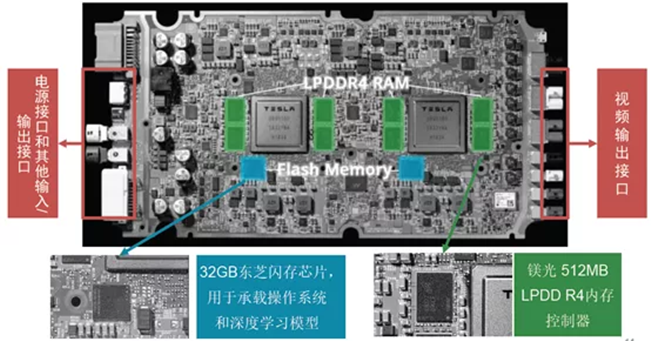
特斯拉板子的右侧接口从上到下依次是FOV摄像头、环视摄像头、A柱左右摄像头、B柱左右摄像头、前视主摄像头、车内DMS摄像头、后摄像头、GPS同轴天线。左侧从上到下依次是第二供电和I/O接口(车身LIN网络等),以太网诊断进/出、调试USB、烧录、主供电和I/O(底盘CAN网络等)。
而通过特斯拉在售车型的介绍和实际配置来看,主张以摄像头视觉为核心的特斯拉安装了一个三目摄像头、4个环视、一个后置摄像头、车内DMS摄像头、前置毫米波雷达、以及12颗超声波雷达。
HW 3.0 PCB器件介绍
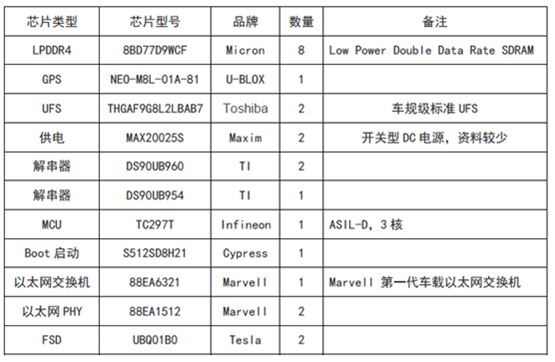
LPDDR 全称是Low Power Double Data Rate SDRAM,是DDR SDRAM的一种,又称为 mDDR(Mobile DDR SDRM),是目前全球范围内移动设备上使用最广泛的“工作记忆”内存。特斯拉的LPDDR4(8BD77D9WCF)是Micron美光供应。
FSD的GPS模块是NEO-M8L-01A-81,水平精度圆概率误差(英文简称CEP- CircularError Probable)为2.5米,有SBAS辅助下是1.5米,接收GPS/QZSS/GLONASS/北斗,CEP和RMS是GPS的定位准确度(俗称精度)单位,是误差概率单位。冷启动26秒,热启动1秒,辅助启动3秒。内置简易6轴IMU,刷新频率20Hz,量大的话价格会低于300元人民币。
UFS(Universal Flash Storage)采用THGAF9G8L2LBAB7,Toshiba 2018年中期量产的新产品,车规级标准UFS,AEC-Q100 2级标准,容量32GB,由于特斯拉的算法模型占地不大倒也够用。
MAX20025S是开关型电源稳压器,给内存供电的,来自Maxim Integrated,目前查不到更多的介绍资料。
S512SD8H21应该是Boot启动,由Cypress(已被Infineon收购)供货。
特斯拉用了3片TI的FPD-LINK,也就是解串器芯片,解串器芯片都是配对使用,加串行一般在摄像头内部,解串行在PCB上。两片DS90UB960,与其对应的可以是DS90UB953-Q1, DS90UB935-Q1,DS90UB933-Q1, DS90UB913A-Q1。DS90UB960拥有4条Lane,如果是MIPI CSI-2端口,每条Lane带宽可以从400Mbps到1.6Gbps之间设置。
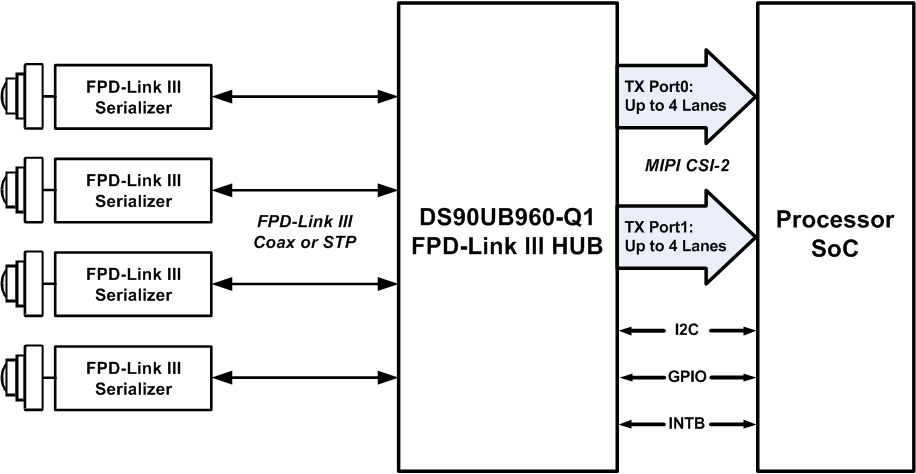
上图为TI推荐的DS90UB960的典型应用示意图,即接4个200万像素帧率30Hz的YUV444数据,或者4个200万像素帧率60Hz的YUV420数据。DS90UB954是DS90UB960简化版,从4Lane减少到2Lane,与之搭配使用的是DS90UB953。
由于大部分摄像头的LVDS格式只能用于近距离传输,因此摄像头都要配备一个解串行芯片,将并行数据转换为串行用同轴或STP传输,这样传输距离远且EMI电磁干扰更容易过车规。目前行业内做解串行芯片用的较多的就是德州仪器TI以及Maxim,特斯拉用的是德州仪器,而我们做开发接触的较多的是Maxim,可能是源于NVIDIA的AI芯片平台设计推荐,目前智能驾驶方面用的摄像头大部分都是Maxim方案。
(摄像头的数据格式通常有RAWRGB、YUV两种。YUV常见的有三种级YUV444,YUV422和YUV420。计算带宽的公式是像素*帧率*比特*X,对RAW RGB来说X=4,比如一款摄像头输出30Hz,200万像素,那么带宽是200万x30x8x4,即1.92Gbps。YUV444是像素X帧率X比特X3,即1.44Gbps,YUV422是像素X帧率X比特X2,即0.96Gbps,YUV420是像素X帧率X比特X1.5,即0.72Gbps。ADAS通常对色彩考虑不多,YUV420足够。除车载外一般多采用YUV422。)

特斯拉自动驾驶主芯片详细讲解
这款FSD芯片采用14nm工艺制造,包含一个中央处理器、1个图像处理单元、2个神经网络处理器,其中中央处理器和图像处理器都采用了第三方设计授权,以保证其性能和稳定性,并易于开发,关键的神经网络处理器设计是特斯拉自主研发, 是现阶段用于汽车自动驾驶领域最强大的芯片。

中央处理器是1个12核心ARM A72架构的64位处理器,运行频率为2.2GHz;图像处理器能够提供0.6TFLOPS计算能力,运行频率为1GHz;2个神经网络处理器运行在2.2GHz频率下能提供72TOPS的处理能力。为了提升神经网络处理器的内存存取速度以提升计算能力,每颗FSD芯片内部还集成了32MB高速缓存。
NPU的总功耗为7.5 W,约占FSD功耗预算的21%。这使得它们的性能功率效率约为4.9TOPs/W,特斯拉在芯片设计方面充分考虑了安全性,一块典型的自动驾驶电路板会集成两颗Tesla FSD芯片,执行双神经网络处理器冗余模式,两颗处理器相互独立,即便一个出现问题另一个也能照常执行,此外还设计了冗余的电源、重叠的摄像机视野部分、各种向后兼容的连接器和接口。
信号传输流程:
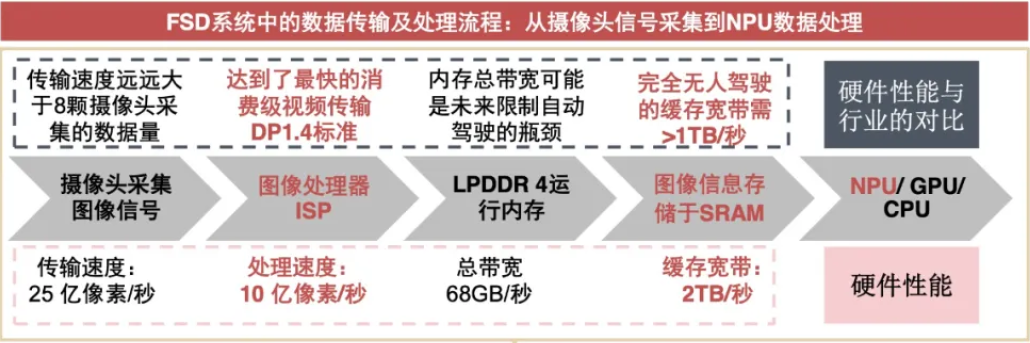
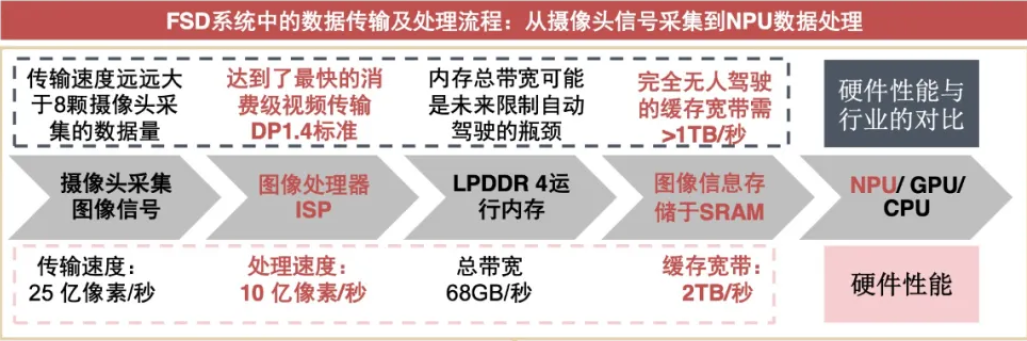
从摄像头的图像开始,根据数据流向,特斯拉解释了整个过程。首先,数据以每秒25亿像素的最大速度采集输入,这大致相当于以每秒60帧的速度输入21块全高清1080P屏幕的数据。这比目前安装的传感器产生的数据多得多。这些数据然后进入我们前面讨论的DRAM,这是SoC的第一个也是主要瓶颈之一,因为这是处理速度最慢的组件。然后数据返回到芯片,并通过图像信号处理器ISP,每秒可以处理10亿像素(大约8个全高清1080P屏幕,每秒60帧)。这一阶段芯片将来自摄像头传感器的原始RGB数据转换成除了增强色调和消除噪音之外实际上有用的数据。
使用的是车载龙头镁光的LPDDR4,具体型号是8BD77D9WCF 8表示年份2018,B 表示第 4 周,D 代表 D-Die,属于镁光产品线中性能相对一般的型号,77 分别代表芯片生产地和封装地,7 代表中国台湾(5 代表中国大陆)。所以,这是一颗美光 2018 年第二周生产的D-Die颗粒)D9WCF对应型号为MT53D512M32D2DS-046AAT。53 代表这是一颗 LPDDR4 颗粒;D 代表1.1V 的工作电压;512M 表示单颗颗粒的容量为 512MB;32 表示单颗粒位宽为 32bit。
按照容量计算单颗芯片是=512MB X 32 ÷8 = 2GB,使用量是4颗,所以DDR的总容量是8GB。
按照LPDDR4最高频率4266MHZ的速率计算,每颗DDR是32位的位宽,CPU的位宽是32X4=128 bit,此时DDR的带宽=4266MBX128 ÷ 8 = 68.25G/S。
我们再来看看目前的特斯拉的信号传输流向。
可以看到,传输速度远远大于8颗摄像头采集的图像数据,传输速度不是瓶颈,ISP的处理速率是10亿像素/秒,如果是RGB888的位深,此时的数据量应该是2.78GB/S,此处的LPDDR4 的带宽是68GB/S,目前单独处理图像是够的。这里说内存带宽可能是未来限制自动驾驶的瓶颈,原因是要处理很多除了图像以外的数据,比如雷达,多线程多应用的数据。
自动驾驶对于DDR带宽的要求:
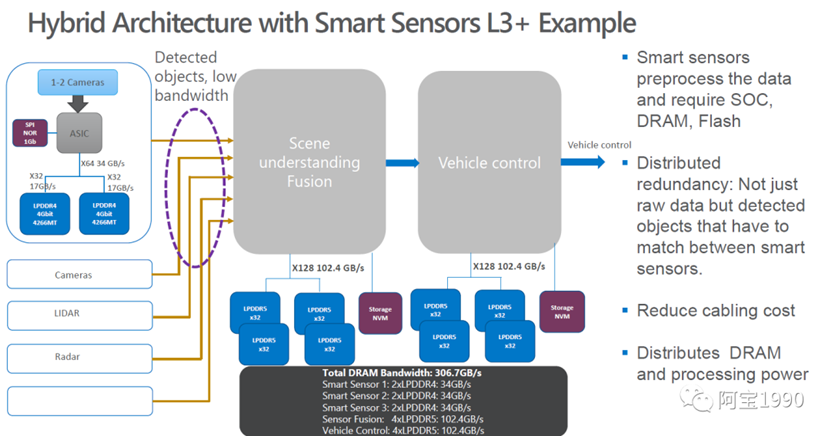
上图是目前比较主流的L3+自动驾驶的架构,从这里可以看到,摄像头那部分的处理需要的DDR的带宽是34GB/s,ASIC的DDR带宽为64bit,ADAS需要处理摄像头的raw dater,这样才是最原始的数据,不是压缩,也没有处理过的数据,这样ADAS处理起来才比较灵活,所以ADAS的带宽要求非常高。
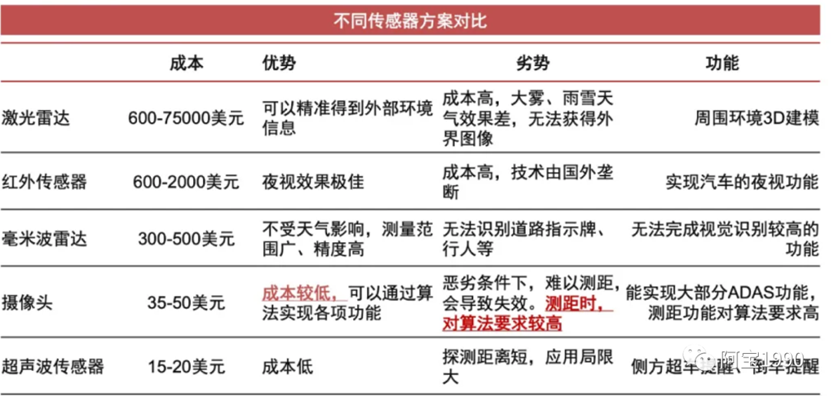
可以看到除了要处理高清摄像头的raw dater的数据,还需要处理超声波雷达和激光雷达的数据,这些传感器的作用是不同的,激光雷达主要用于3D建模、超声波雷达用于倒车、超车,摄像头主要用于部分ADAS功能,比如ACC自适应巡航、AEB紧急制动等等。
由于这些传感器的数据量非常大,处理的要求也比较高,所以对于ADAS CPU的DDR的带宽要求非常高,需要使用到4颗32bit的LPDDR5,同时需要CPU 的DDR带宽为128bit,同时带宽需要达到102.4GB/s,也许你会有疑惑,为什么特斯拉的才68GB/s的带宽就可以处理了呢?
特斯拉由于成本原因,没有使用激光雷达,下图是特斯拉车身上不同版本的硬件的传感器,AP3.0的硬件使用了6个摄像头,12个超声波雷达,1个毫米波雷达。由于算法做的非常牛掰,一样的可以使用超声波雷达+摄像头进行3D数据建模。所以性能更优,成本更少,而且对于DDR的带宽要求也下降了。
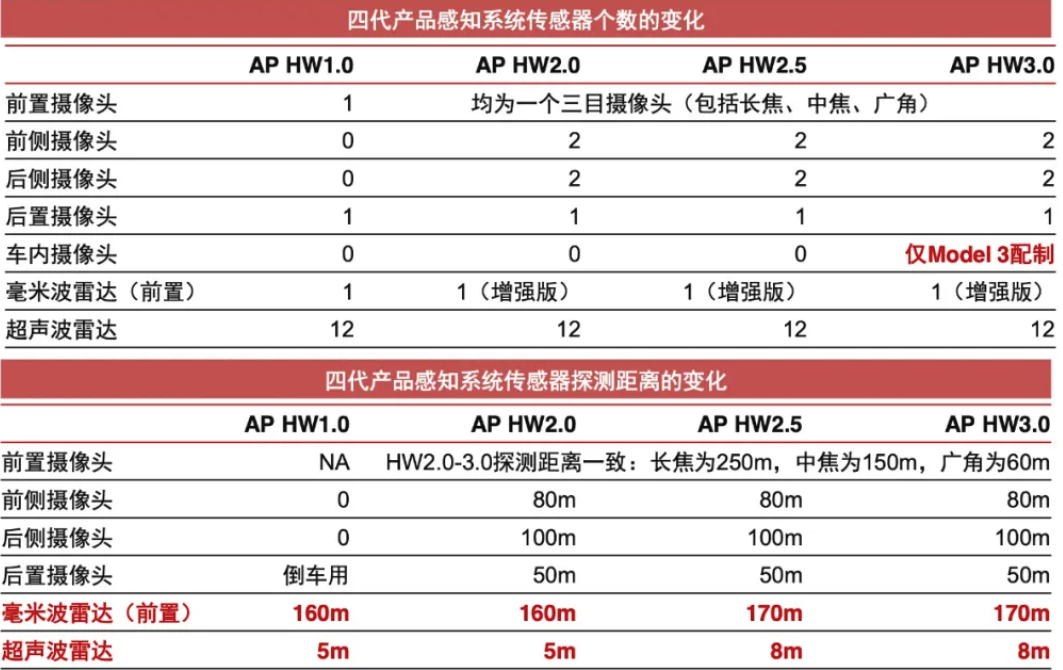
2020年市场上打造的L2级别的驾驶,都没有使用到激光雷达,只有谷歌的waymo使用了4颗激光雷达还有奥迪A8的使用了1颗激光雷达。2021年上海车展的情况来看极光雷达如雨后春笋,越来越多的智能汽车选择使用激光雷达,很多激光雷达都是安全冗余使用的目的,传感器数据是做后融合,此时处理数据的能力要求就提高,此时对于DDR带宽要求会变大。

特斯拉NPU介绍
上图的型号处理过程中,该过程的第一步是将数据存储在SRAM阵列中。现在很多人——甚至是那些对计算机组件略知一二的人——可能会想,“SRAM到底是什么?”嗯,最接近的比较是在计算机处理器上能找到的共享L3缓存。这意味着什么呢?这意味着存储速度非常快,但同时也很贵。
目前,Intel最大的L3缓存是45 MB(2010年以前是16 MB, 2014年以前是24 MB)。大多数消费级笔记本电脑和桌面处理器都有8-12 MB的L3缓存。特斯拉的神经网络处理器有一个庞大的64MB SRAM,它被分成两个32 MB的SRAM段来支持两个神经网络处理器。特斯拉认为其强大的SRAM容量是其相对于其他类型芯片的最大优势之一。
NPU的算力能够满足很多图像相关的识别算法:

假设此时你车上的AI图像算法是YOLO-V3,它是一种使用深度卷积神经网络学得的特征来检测对象的目标检测器,直白点就是照片识别器,在机场地铁都有批量使用,就是大量的卷积、残差网络、全连接等类型的计算,本质是乘法和加法。对于YOLO-V3来说,如果确定了具体的输入图形尺寸,那么总的乘法加法计算次数是确定的。比如一万亿次。(真实的情况比这个大得多的多),用算力表示就是TOPS为单位。那么要快速执行一次YOLO-V3,就必须执行完一万亿次的加法乘法次数。
这个时候就来看了,比如IBM的POWER8,最先进的服务器用超标量CPU之一,4GHz,SIMD,128bit,假设是处理16bit的数据,那就是8个数,那么一个周期,最多执行8个乘加计算。一次最多执行16个操作。这还是理论上,其实是不大可能的。
那么CPU一秒钟的巅峰计算次数=16* 4Gops =64Gops,当然,以上的数据都是完全最理想的理论值。因为,芯片上的存储不够大,所以数据会存储在DRAM中,从DRAM取数据很慢的,所以,乘法逻辑往往要等待。另外,AI算法有许多层网络组成,必须一层一层的算,所以,在切换层的时候,乘法逻辑又是休息的,所以,诸多因素造成了实际的芯片并不能达到利润的计算峰值,而且差距还极大,实际情况,能够达到5%吧,也就3.2Gops,按照这个图像算法,如果需要执行YOLO-V3的计算,1W除以3.2=3125秒,也就是那么需要等待52分钟才能计算出来。
如果是当前的CPU去运算,那么估计车翻到河里了还没发现前方是河,这就是速度慢,对于ADAS产品而言,时间就是生命。
此时我们在回过头来看看高通820A芯片的算力,CPU的算力才42K,刚刚那个是基于最先进的服务器IBM的POWER8 CPU计算力是是3.2GPOS,车载算的上最先进的域控制器才42K的CPU计算力,所以不能用于AI的计算。此时需要使用GPU来计算,看看GPU的算力是320Gops,此时算这个YOLO-V3图像识别的算法需要32秒,这个成绩还是非常不错的。
此时可以看到高通820A芯片的CPU算力是不能够用于AI的计算,GPU的算力是可以满足一些不需要那么实时性比较高的一些AI处理。
此时可以看到高通820A芯片的CPU算力是不能够用于AI的计算,GPU的算力是可以满足一些不需要那么实时性比较高的一些AI处理。
此时再来看看特斯拉的NPU,这个只需要13.8ms就可以计算出来了,按照80KM/h的速度,这个响应速度在0.3米,完全是杠杠的,实际情况下应该没有那么快,因为运算速度没有那么快。
神经网络处理器是一个非常强大的工具。很多数据都要经过它,但有些计算任务还没有调整到适合神经网络处理器上运行,或者不适合这种处理器。这就是GPU的用武之地。该芯片的GPU(每辆特斯拉都有)性能适中,运行速度为1 GHz,能够处理600 GFLOPS数据。特斯拉表示,GPU目前正在执行一些后处理任务,其中可能包括创建人类可以理解的图片和视频。然而,从特斯拉在其演示中描述的GPU的角色来看,预计该芯片的下一次迭代将拥有一个更小的GPU。
还有一些通用的处理任务不适合由神经网络处理器处理、而由CPU来完成的。特斯拉解释说,芯片中有12个ARM Cortex A72 64位CPU,运行速度为2.2 GHz。尽管这样——更准确的描述应该是有三个4核cpu——特斯拉选择使用ARM的Cortex A72架构有点令人费解。Cortex A72是2015年的一个架构。从那以后,A73, A75,甚至几天前A77架构已经发布。埃隆和他的团队解释说,这是他们两年前开始设计芯片时就有的东西。
对于Tesla来说,这可能是一个更便宜的选择,如果多线程性能对他们来说比单个任务性能更重要,那么这是有意义的,因此包含3个较老的处理器而不是1个或2个更新或更强大的处理器。多线程通常需要更多的编程工作来正确分配任务,但是,嘿,我们正在谈论的是特斯拉——这对它来说可能是小菜一碟。无论如何,该芯片的CPU性能比特斯拉之前版本HW 2.0的CPU性能高出2.5倍。
AI芯片加速原理:
人工智能(深度学习)现在无处不在,衡量人工智能运算量通常有三个名词。
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
MACCs:是multiply-accumulate operations),也叫MAdds,意指乘-加操作(点积运算),理解为计算量,也叫MAdds, 大约是 FLOPs 的一半。
人工智能中最消耗运算量的地方是卷积,就是乘和累加运算Multiply Accumulate,MAC。
y = w[0]*x[0] + w[1]*x[1] + w[2]*x[2] + ... + w[n-1]*x[n-1]
w 和 x 都是向量,y 是标量。上式是全连接层或卷积层的典型运算。一次乘-加运算即一次乘法+一次加法运算,所以上式的 MACCs 是n。而换到 FLOPS 的情况,点积做了 2n-1 FLOPS,即 n-1 次加法和 n 次乘法。可以看到,MACCs 大约是 FLOPS 的一半。实际就是MAC只需一个指令,一个运算周期内就可完成乘和累加。卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算都可以分解为数个 MAC 指令,人工智能运算也可以写成MAC运算。
MAC指令的输入及输出的数据类型可以是整数、定点数或是浮点数。若处理浮点数时,会有两次的数值修约(Rounding),这在很多典型的DSP上很常见。若一条MAC指令在处理浮点数时只有一次的数值修约,则这种指令称为“融合乘加运算”/“积和熔加运算”(fused multiply-add, FMA)或“熔合乘法累积运算”(fused multiply–accumulate,FMAC)。假设3×3卷积,128 个 filer,输入的 feature map 是 112×112×64,stride=1,padding=same,MACCs 有:3×3×64×112×112×128=924,844,032次,即1.85TOPS算量。
AI芯片就是简单暴力地堆砌MAC单元。增加MAC数量,这是提升算力最有效的方法,没有之一,而增加MAC数量意味着芯片裸晶面积即成本的大幅度增加,这也是为什么AI芯片要用到尽可能先进的半导体制造工艺,越先进的半导体制造工艺,就可拥有更高的晶体管密度,即同样面积下更多的MAC单元,衡量半导体制造工艺最主要的指标也就是晶体管密度而不是数字游戏的几纳米。
具体来说,台积电初期7纳米工艺,每平方毫米是9630万个晶体管,后期7+纳米可以做到每平方毫米1.158亿个晶体管,三星7纳米是9530万个,落后台积电18%,而英特尔的10纳米工艺是1.0078亿个晶体管,领先三星,落后台积电。这也是台积电垄断AI芯片的原因。而5纳米工艺,台积电是1.713亿个晶体管,而英特尔的7纳米计划是2亿个晶体管,所以英特尔的7纳米芯片一直难产,难度比台积电5纳米还高。顺便说下,台积电平均每片晶圆价格近4000美元,三星是2500美元,中芯国际是1600美元。
除了增加数量,还有提高MAC运行频率,但这意味着功耗大幅度增加,有可能造成芯片损坏或死机,一般不会有人这么做。除了简单的数量增加,再一条思路是提高MAC的效率。
提高MAC效率方法:
提升MAC效率最重要的就是存储。
真实值和理论值差异极大。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率( 即供电电压或温度),还有算法的batch尺寸。例如谷歌第一代TPU,理论值为90TOPS算力,最差真实值只有1/9,也就是10TOPS算力,因为第一代内存带宽仅34GB/s。而第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片,TPU V2板内存总带宽2400GB/s)。
最新的英伟达的A100使用40GB的2代HBM,带宽提升到1600GB/s,比V100提升大约73%。特斯拉是128 bit LPDDR4-4266 ,那么内存的带宽就是:2133MHz*2DDR*128bit/8/1000=68.256GB/s。比第一代TPU略好( 这些都是理论上的最大峰值带宽)其性能最差真实值估计是2/9。也就是大约8TOPS。16GB版本的Xavier内存峰值带宽是137GB/s。
为什么会这样,这就牵涉到MAC计算效率问题,如果你的算法或者说CNN卷积需要的算力是1TOPS,而运算平台的算力是4TOPS,那么利用效率只有25%,运算单元大部分时候都在等待数据传送,特别是batch尺寸较小时候,这时候存储带宽不足会严重限制性能。但如果超出平台的运算能力,延迟会大幅度增加,存储瓶颈一样很要命。效率在90-95%情况下,存储瓶颈影响最小,但这并不意味着不影响了,影响依然存在。
然而平台不会只运算一种算法,运算利用效率很难稳定在90-95%。这就是为何大部分人工智能算法公司都想定制或自制计算平台的主要原因,计算平台厂家也需要推出与之配套的算法,软硬一体,实难分开。
最为有效的方法还是减小运算单元与存储器之间的物理距离。也是这15年来高性能芯片封装技术发展的主要目标,这不仅可以提高算力,还能降低功耗减少发热。这其中最有效的技术就是HBM和CoWoS。

CPU与HBM2之间通过Micro-bump连接,线宽仅为55微米,比传统的板上内存或者说off-chip内存要减少20倍的距离。可以大大缓解内存瓶颈问题。
不过HBM和CoWoS价格都很高,假设500万的一次下单量,7纳米工艺的话,纯晶圆本身的硬件成本大约是每片芯片208-240美元,这个价格做训练用AI芯片可以承受,但是推理AI芯片用不起。再有CoWoS是台积电垄断的,台积电也正是靠这种工艺完全垄断高性能计算芯片代工。英特尔的EMIB是唯一能和CoWoS抗衡的工艺,但英特尔不代工。
退而求其次的方法是优化指令集,尽量减少数据的访存,CNN算法会引入大量的访存行为,这个访存行为的频繁度会随着参考取样集合的增加而增加(原因很简单,缓存无法装下所有的参考取样,所以,即便这些参考取样会不断地被重复访问,也无法充分挖掘数据本地化所带来的cache收益)。针对这种应用类型,实际上存在成熟的优化范式——脉动阵列。
脉动阵列
脉动阵列并不是一个新鲜的词汇,在计算机体系架构里面已经存在很长时间。大家可以回忆下冯诺依曼架构,很多时候数据一定是存储在memory里面的,当要运算的时候需要从memory里面传输到Buffer或者Cache里面去。
当我们使用computing的功能来运算的时候,往往computing消耗的时间并不是瓶颈,更多的瓶颈在于memory的存和取。所以脉动阵列的逻辑也很简单,既然memory读取一次需要消耗更多的时间,脉动阵列尽力在一次memory读取的过程中可以运行更多的计算,来平衡存储和计算之间的时间消耗。
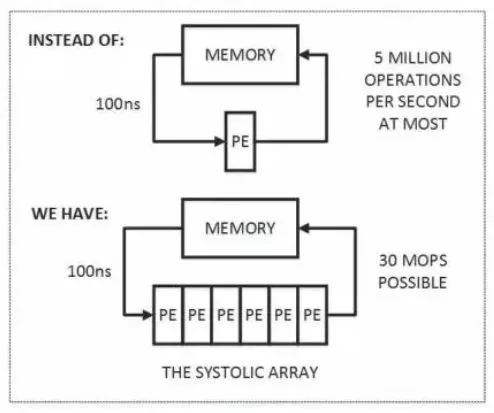
下面说下脉冲阵列的基本原理:
首先,图中上半部分是传统的计算系统的模型。一个处理单元(PE)从存储器(memory)读取数据,进行处理,然后再写回到存储器。这个系统的最大问题是:数据存取的速度往往大大低于数据处理的速度。因此,整个系统的处理能力(MOPS,每秒完成的操作)很大程度受限于访存的能力。这个问题也是多年来计算机体系结构研究的重要课题之一,可以说是推动处理器和存储器设计的一大动力。而脉动架构用了一个很简单的方法:让数据尽量在处理单元中多流动一会儿。
正如上图的下半部分所描述的,第一个数据首先进入第一个PE,经过处理以后被传递到下一个PE,同时第二个数据进入第一个PE。以此类推,当第一个数据到达最后一个PE,它已经被处理了多次。所以,脉动架构实际上是多次重用了输入数据。因此,它可以在消耗较小的memory带宽的情况下实现较高的运算吞吐率。
上面这张图非常直观的从一维数据流展示了脉动阵列的简单逻辑。当然,对于CNN等神经网络来说,很多时候是二维的矩阵。所以,脉动阵列从一维到二维也能够非常契合CNN的矩阵乘加的架构。
降低推理的量化比特精度是最常见的方法。它既可以大大降低运算单元的精度,又可以减少存储容量需求和存储器的读写。但是,降低比特精度也意味着推断准确度的降低,这在一些应用中是无法接受的。由此,基本运算单元的设计趋势是支持可变比特精度,比如BitMAC 就能支持从 1 比特到 16 比特的权重精度。大部分AI推理芯片只支持INT8位和16位数据。
除了降低精度以外,还可以结合一些数据结构转换来减少运算量,比如通过快速傅里叶变换(FFT)变换来减少矩阵运算中的乘法;还可以通过查表的方法来简化 MAC 的实现等。
对于使用修正线性单元(ReLU)作为激活函数的神经网络,激活值为零的情况很多 ;而在对神经网络进行的剪枝操作后,权重值也会有很多为零。基于这样的稀疏性特征,一方面可以使用专门的硬件架构,比如 SCNN 加速器,提高 MAC 的使用效率,另一方面可以对权重和激活值数据进行压缩。
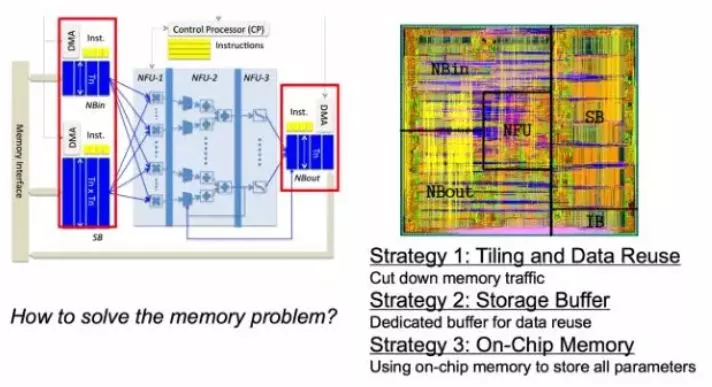
还可以从体系架构上对整个的Memory读取来做进一步的优化。这里摘取的是寒武纪展示的一些科研成果。其实比较主流的方式就是尽量做Data Reuse,减少片上Memory和片外Memory的信息读取次数,增加片上memory,因为片上数据读取会更快一点,这种方式也能够尽量降低Memory读取所消耗的时间,从而达到运算的加速。
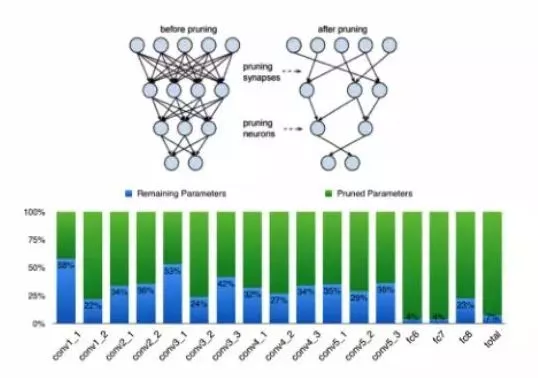
对于神经网络来说,其实很多的连接并不是一定要存在的,也就是说我去掉一些连接,可能压缩后的网络精度相比压缩之前并没有太大的变化。基于这样的理念,很多剪枝的方案也被提了出来,也确实从压缩的角度带来了很大效果提升。
需要特别提出的是,大家从图中可以看到,深度学习神经网络包括卷积层和全连接层两大块,剪枝对全连接层的压缩效率是最大的。下面柱状图的蓝色部分就是压缩之后的系数占比,从中可以看到剪枝对全连接层的压缩是最大的,而对卷积层的压缩效果相比全连接层则差了很多。
所以这也是为什么,在语音的加速上很容易用到剪枝的一些方案,但是在机器视觉等需要大量卷积层的应用中剪枝效果并不理想。

对于整个Deep Learning网络来说,每个权重系数是不是一定要浮点的,定点是否就能满足?定点是不是一定要32位的?很多人提出8位甚至1位的定点系数也能达到很不错的效果,这样的话从系数压缩来看就会有非常大的效果。从下面三张人脸识别的红点和绿点的对比,就可以看到其实8位定点系数在很多情况下已经非常适用了,和32位定点系数相比并没有太大的变化。所以,从这个角度来说,权重系数的压缩也会带来网络模型的压缩,从而带来计算的加速。
谷歌的TPU AI计算加速介绍:
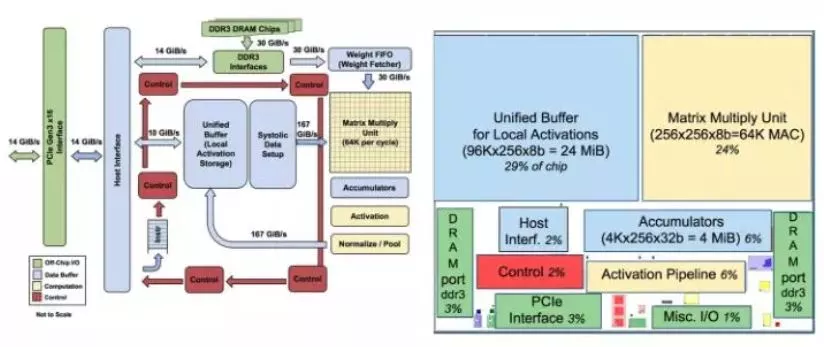
这是Google的TPU。从上边的芯片框图可以看到,有一个64K的乘加MAC阵列对乘加运算进行加速。从论文中可以看到里面已经用到了脉动阵列的架构方法来对运算进行加速,另外也有我们前面提到的大量的片上Memory 这样的路径。上面蓝色框图中大家可以看到有一个24MiB的片上Memory,而且有两个高速DDR3接口能够与片外的DDR做交互。
再来说说AI芯片。比如大名鼎鼎的谷歌的TPU1。TPU1,大约700M Hz,有256X256尺寸的脉动阵列,如下图所示。一共256X256=64K个乘加单元,每个单元一次可执行一个乘法和一个加法。那就是128K个操作。(乘法算一个,加法再算一个)。

另外,除了脉动阵列,还有其他模块,比如激活等,这些里面也有乘法、加法等。
所以,看看TPU1一秒钟的巅峰计算次数至少是=128K X 700MHz=89600Gops=大约90Tops。
对比一下CPU与TPU1,会发现计算能力有几个数量级的差距,这就是为啥说CPU慢。
当然,以上的数据都是完全最理想的理论值,实际情况,能够达到5%吧。因为,芯片上的存储不够大,所以数据会存储在DRAM中,从DRAM取数据很慢的,所以,乘法逻辑往往要等待。另外,AI算法有许多层网络组成,必须一层一层的算,所以,在切换层的时候,乘法逻辑又是休息的,所以,诸多因素造成了实际的芯片并不能达到利润的计算峰值,而且差距还极大。
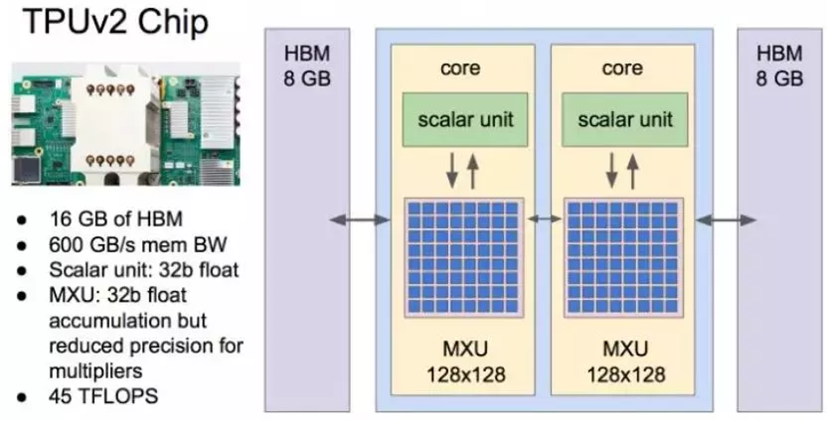
上图展示的第二代TPU。从图中可以很直观的看到,它用到了我们前面所说到的HBM Memory。从其论文披露的信息也可以看到,二代TPU在第一代的基础上增加了我们前面说到的剪枝,权重压缩等方面做了很多尝试,也是一个非常经典的云端AI加速芯片的例子。

特斯拉HW4.0 将改变未来汽车的模样
硬件层面:
我们对HW 4.0有什么期待呢?目前,我们所知道的是,它的目的是进一步提高安全性。唯一真正告诉我们的是,它不会专注于让一辆旧车学习新技术,但这并不意味着它不会包括一些新技术。以下是我列出的HW 4.0可能带来的潜在变化和改进,从最可能的到最具推测性的排列如下:
特斯拉很可能会使用更新的CPU版本,这取决于特斯拉什么时候开始设计基于A75的架构。增加的处理能力让特斯拉有机会节省芯片上的功耗和空间,为更重要的组件腾出空间。
特斯拉可能会升级到LPDDR5,这将导致显著的速度提升和功耗降低。但是,如果HW 4.0芯片在设计过程中、或者为了降低成本,特斯拉可能会选择LPDDR4X。通过使用较低的电压平台,LPDDR4X节省了能耗,但如果同时使用多个芯片,它仍然可以提高速度。尽管如此,与HW 3.0相比,这种配置并不会节省能耗。任何一种选择都代表着对HW 3.0的全面改进。
进一步改进具有更多SRAM的神经网络处理单元。
根据芯片上的处理能力是否能够处理摄像头传输过来的全分辨率和帧速率的数据,特斯拉的HW 4,0可能会配备更高分辨率的新摄像头和传感器,甚至可能会有更高的帧速率。更高分辨率的图像是至关重要的,因为更多的细节将帮助计算机更准确地识别物体,并具备更远的识别距离。
升级的图像信号处理器(ISP)。特斯拉想让自己的芯片尽可能的便宜和强大。这就是为什么在HW 3.0中,芯片输入的处理能力和ISP的处理能力之间存在很大的脱节,因此需要一个更强大的或第二块ISP,这取决于哪种解决方案需要更低的功耗、更小的空间或更低的成本。

一个更小的GPU。HW 3.0的SoC中还存在GPU的原因之一是,并不是所有的处理任务都转移到神经网络处理器中去了。对于特斯拉来说,让它的程序员有足够的时间将剩余的GPU处理任务重新分配给NPU或CPU可能是一条捷径。完全消除GPU可能是不可能的;然而,一个更小的GPU和更小的SoC占用导致更少的NoC,这样可以为更关键的组件——如更多的SRAM——匀出预算和空间。
软件层面:
新一代自动驾驶芯片和HW4.0即将在明年量产,重构AutoPilot底层架构,将推出训练神经网络超级计算机Dojo,瞄准L5自动驾驶场景。2020年8月多家媒体报道,特斯拉正与博通合作研发新款 HW 4.0 自动驾驶芯片,有望在明年第四季度大规模量产,未来将采用台积电 7nm 技术进行生产。同时AutoPilot 团队正对软件的底层代码进行重写和深度神经网络重构, 包括对数据标注、训练、推理全流程的重构。

全新的训练计算机 Dojo 正在开发中。Dojo 将专门用于大规模的图像和视频数据处理,其浮点运算能力将达到exaflop 级别(秒运算百亿亿次),将配合无监督学习算法,来减少特斯拉对于数据人工标注的工作量,帮助特斯拉数据训练效率实现指数级提升。目前特斯拉已经拥有超过82万台车不断回传数据,到2020年年底将拥有51亿英里驾驶数据用于自动驾驶训练,过去的训练数据依赖于人工标注,而主动的自监督学习配合Dojo计算机可以大幅优化算法提升的效率。
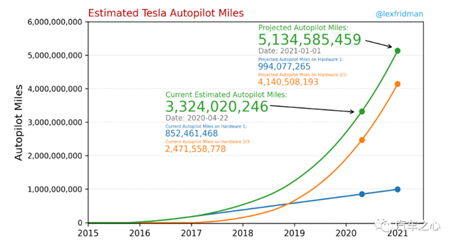
Dojo 可以改善 Autopilot 的工作方式,从目前的2D图像 + 内容标注方式训练,升级到可以在「4D」(3D 加上时间维度)环境下运行。我们预计借助强大的自研计算平台、全球领先的AI算法能力、庞大的实际驾驶数据量,特斯拉有望成为率先实现L5级别自动驾驶的公司。
特斯拉HW4.0为什么有勇气对激光雷达say no:
目前还在坚持做图像识别为主的只有特斯拉了,Mobileye已经开始使用了激光雷达做下一代自动驾驶平台的关键器件了,只有马教主坚持激光雷达就像阑尾,他说:一个阑尾就够糟了,还带一堆,简直荒谬。
特斯拉如此有勇气,其实在于它的研发模式,从芯片 ,操作系统,算法以及控制器都是自研,整个性能可以发挥到极致。

视觉方案通过摄像头,致力于解决“拍到的是什么”问题。从工作原理来看,视觉方案以摄像头作为主要传感器,通过收集外界反射的光线从而进一步呈现出外界环境画面,即我们所熟悉的摄像头功能,再进行后续图像分割、物体分类、目标跟踪、世界模型、多传感器融合、在线标定、视觉SLAM、ISP 等一系列步骤进行匹配与深度学习,其核心环节在于物体识别与匹配,或者运用AI 自监督学习来达到感知分析物体的目的,需要解决的是“我拍到的东西是什么”的问题。
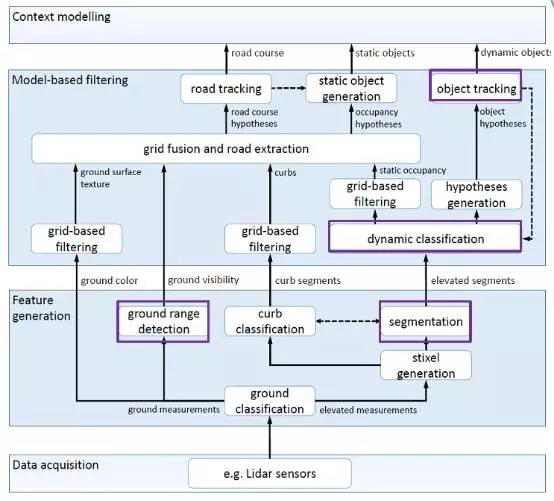
视觉方案重在分类,但样本有限度限制了视觉识别正确性,而优化样本对于AI 学习能力、样本数据量要求极高。由于L3 级及以上自动驾驶需要机器应对较为复杂的路况,要求车辆对于道路状况有精准识别能力,而视觉技术需要解决的是“摄像头拍到的是什么物体”的问题,因而对于神经网络训练集要求很高。对于训练的方法,一种为通过机器视觉,人为设定好识别样本,通过收集到的数据直接与样本匹配来识别的方式,但是能否成功辨别物体高度依赖样本的训练,样本未覆盖的物体将难以辨别;另一种为AI 学习,能够通过自学习的方式摆脱样本限制,但是对于算法与算力要求很高,并且其学习过程是个“黑盒子”,输出结果的过程未知,因而难以人为调试与纠错。
而这两个关键问题,对于特斯拉都可以通过提高芯片本身的算力,还有云计算平台的大数据训练来解决。

特斯拉的视觉方案具有很高的算法与算力复杂度。特斯拉曾公布过自己数据流自动化计划的终极目标“OPERATION VACATION”,从数据收集、训练、评估、算力平台到“影子模式”形成数据采集与学习循环。
数据收集:通过8 个摄像头对车体周围进行无死角图像采集;
数据训练:使用PyTorch 进行网络训练,特斯拉的网络训练包含48 个不同的神经网络,
能输出1000 个不同的预测张量。其背后训练量巨大,特斯拉已耗费70000 GPU 小时进行深度学习模型训练;
背后算力支持:特斯拉自研打造了FSD 芯片,具有单片144TOPS 的高算力值。另外,
特斯拉规划创造Dojo 超级计算机,可在云端对大量视频进行无监督学习训练,目前离开发出来的进度值得期待;
影子模式:特斯拉通过独创“影子模式”来降低样本训练成本、提高识别准确度,即特斯拉持续收集外部环境与驾驶者的行为,并与自身策略对比,如果驾驶者实际操作与自身判断有出入,当下数据就会上传至特斯拉云端,并对算法进行修正训练。
从数据采集,本地芯片硬件处理、图像的软件算法处理、再到后台的超级计算机进行训练,这个需要一系列的技术支持,最好从芯片、操作系统、算法、控制器都是自研,这样才能把芯片的性能发挥最佳,从Mobileye的黑盒子开发模式,直接就让车厂彻底放弃了这条纯视觉处理的道路,不投入几千亿估计门都摸不着方向,所以目前只有特斯拉这样的理工男对于激光雷达有勇气say no。
特斯拉FSD 关键功能汇总
参考资料:
1、https://mp.weixin.qq.com/s/s4XzAFBVle92lKGrh8S5_A
2、https://mp.weixin.qq.com/s/YgiMNF2NxWlqxJD7vxfALg
3、https://mp.weixin.qq.com/s/IxcVhpKfDhq-85pmV-a_HA