接上篇《52、CrawlSpider链接提取器的使用》
上一篇我们学习了基于规则进行跟踪和自动爬取网页数据的“特殊爬虫”CrawlSpider。本篇我们来学习Scrapy的日志信息及日志级别。
一、引言
1、日志在Scrapy中的重要性
在Scrapy框架中,日志扮演着至关重要的角色。日志不仅记录了爬虫在运行过程中的详细行为,还提供了大量有助于开发者定位问题和优化程序的信息。通过日志,开发者可以了解到爬虫的每一步操作,包括请求的发送、响应的接收、数据的解析以及任何可能出现的异常。这些信息对于调试程序、监控运行状态以及优化性能都是不可或缺的。
2、日志级别及其作用
日志级别在Scrapy中同样具有重要意义。不同级别的日志信息反映了不同层次的程序运行状况。通过设置合适的日志级别,开发者可以过滤掉大量不必要的细节信息,只关注关键的运行状态和错误提示。这不仅可以提高开发效率,还有助于快速定位并解决潜在的问题。同时,合理的日志级别设置也有助于保护程序的敏感信息,避免信息泄露的风险。因此,深入理解Scrapy的日志级别及其使用方法是每一个Scrapy开发者必须掌握的技能。
二、Scrapy日志系统概述
1、Scrapy日志系统的基本结构
Scrapy的日志系统采用了层次化的设计,确保日志信息能够有序地生成、处理和输出。它主要由以下几个关键组件构成:
●日志记录器(Logger):Scrapy中的每个模块或组件都有自己的日志记录器。这些记录器负责收集并处理与该模块或组件相关的日志信息。
●日志处理器(Handler):日志处理器负责将日志信息输出到指定的目的地,如控制台、文件或远程服务器等。Scrapy支持多种类型的处理器,以满足不同的输出需求。
●日志级别(Level):Scrapy支持多种日志级别,包括DEBUG、INFO、WARNING、ERROR和CRITICAL。这些级别用于区分不同重要程度的日志信息,帮助开发者快速定位问题。
●日志格式(Formatter):日志格式定义了日志信息的输出格式,包括时间戳、日志级别、模块名、消息内容等。Scrapy允许开发者自定义日志格式,以满足特定的需求。
2、日志信息的生成与输出
在Scrapy中,日志信息的生成与输出是一个自动化的过程。当爬虫运行时,各个模块和组件会根据其内部状态和操作生成相应的日志信息。这些信息首先被传递给对应的日志记录器,记录器根据配置的日志级别对信息进行过滤和处理。然后,处理后的日志信息被传递给相应的日志处理器,由处理器负责将其输出到指定的目的地。
Scrapy的日志系统支持多种输出方式,包括控制台输出、文件存储和远程日志服务等。开发者可以根据自己的需求选择合适的输出方式,并配置相应的处理器。
在Scrapy中,日志信息的生成与输出通常是自动进行的,无需开发者显式编写日志记录代码。Scrapy内部使用了Python的logging模块来处理日志,并在框架的不同部分自动记录日志信息。以下是一个简单的Scrapy spider示例,其中日志信息的生成和输出是自动发生的:
python">import scrapyclass BaiduSpiderSpider(scrapy.Spider):name = "baidu_spider"allowed_domains = ["www.baidu.com"]start_urls = ["https://www.baidu.com"]# 百度设置了反爬,使用这个程序测试时,记得把setting.py的ROBOTSTXT_OBEY参数改为Falsedef parse(self, response):# 当爬虫解析页面时,会自动生成并输出日志信息self.logger.info('被抓取的页面地址为: %s', response.url)# ... 其他解析逻辑 ...pass在这个示例中,self.logger.info()用于记录一条INFO级别的日志信息。Scrapy会自动处理这条日志信息的输出,通常默认输出到控制台: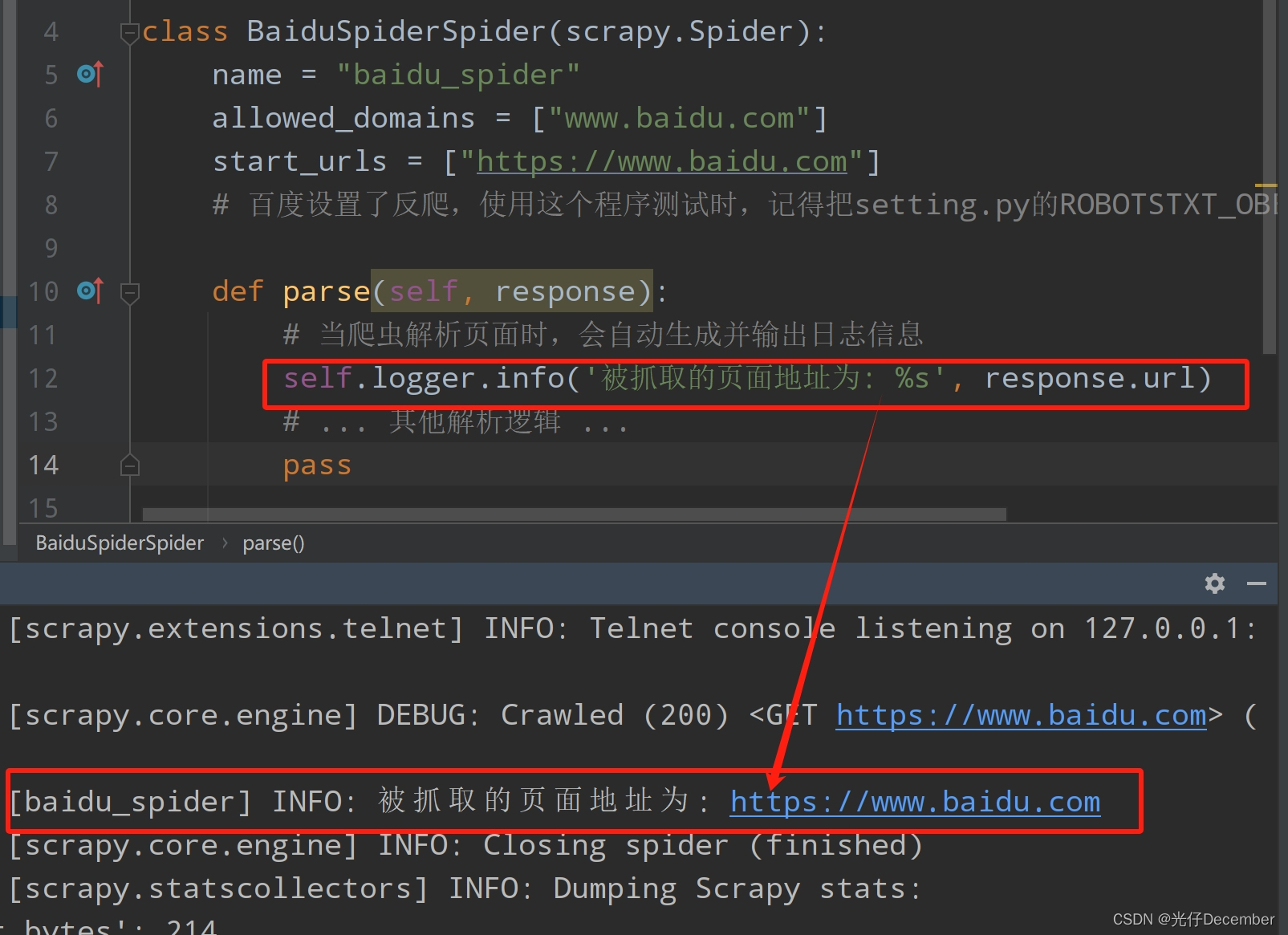
3、日志系统的配置与自定义
Scrapy的日志系统提供了丰富的配置选项,允许开发者根据实际需求进行自定义。通过修改Scrapy的配置文件或编写自定义的日志处理逻辑,开发者可以控制日志的级别、格式、输出方式等。
(1)设置日志级别
你可以设置整个Scrapy项目的日志级别,或者为特定的组件设置不同的日志级别(在settings.py中设置):
python"># settings.py # 设置整个项目的日志级别为INFO
LOG_LEVEL = 'INFO' # 或者为特定的组件设置日志级别
# 例如,为Scrapy引擎设置DEBUG级别
LOG_LEVEL_SCRAPY = 'DEBUG'除了LOG_LEVEL外,日志系统还包含其他参数:
●LOG_FILE: 日志输出文件。如果设置为None,日志信息将直接打印到控制台。通过设置具体的文件路径和名称,你可以将日志保存到本地文件中,方便后续查看和分析。
●LOG_ENABLED: 是否启用日志系统。默认为True,表示启用日志记录。如果设置为False,则不会记录任何日志信息。
●LOG_ENCODING: 日志编码。默认为utf-8,表示使用UTF-8编码来保存日志信息。你可以根据需要调整此设置以适应不同的编码要求。
●LOG_FORMAT 和 LOG_DATEFORMAT: 分别用于定义日志的格式和日期格式。通过自定义这些格式,你可以控制日志信息的显示方式,使其更符合你的需求。
(2)自定义日志输出格式
你可以自定义日志的输出格式,使其包含更多或更少的信息(在settings.py中设置):
python"># settings.py # 自定义日志输出格式
LOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_DATEFORMAT = '%Y-%m-%d %H:%M:%S'测试效果: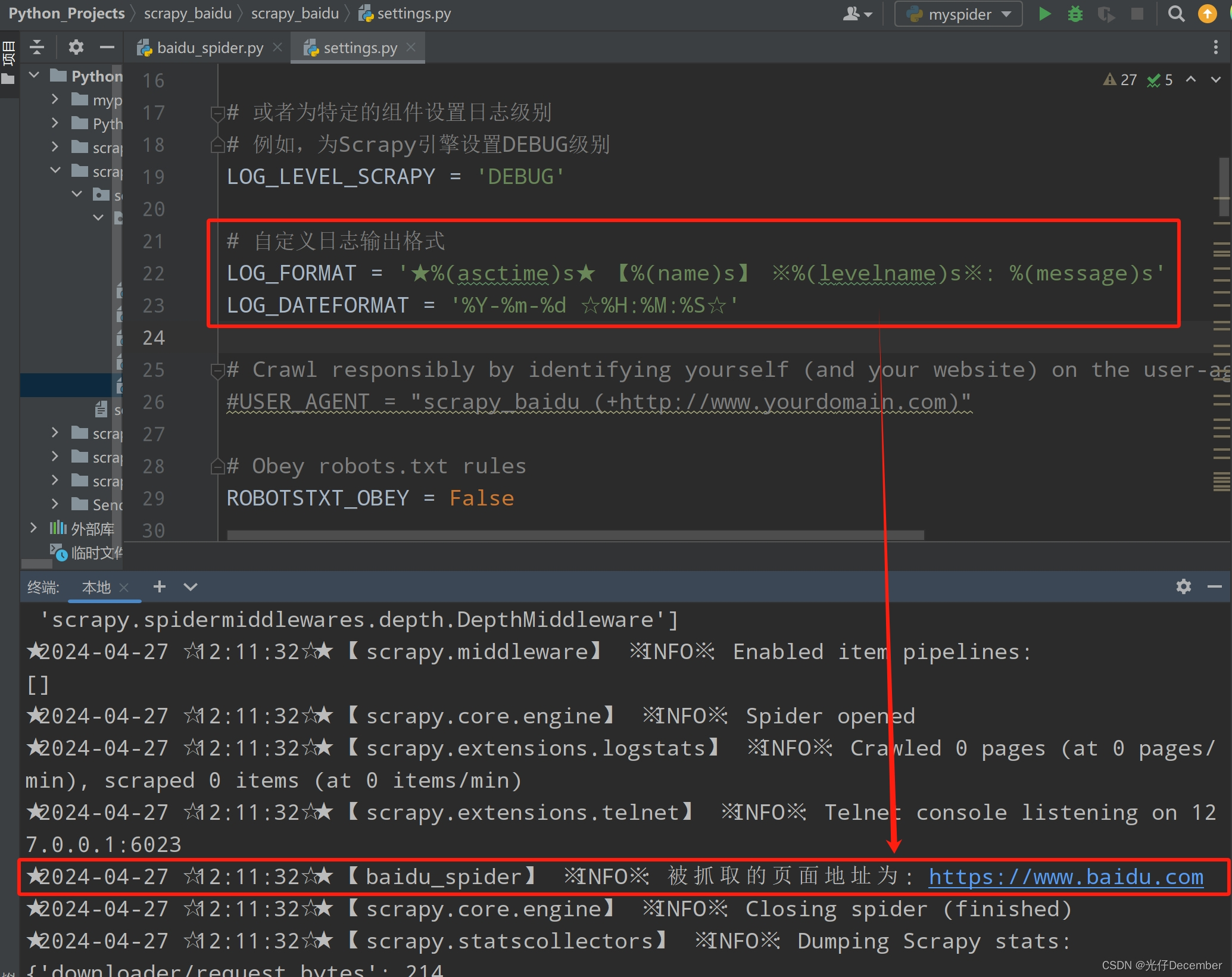
(3)将日志输出到文件
默认情况下,Scrapy将日志输出到控制台。你可以通过添加自定义的日志处理器来将日志输出到文件(在settings.py中设置):
python"># settings.py # 添加自定义的日志处理器,将日志输出到文件
from scrapy.utils.log import configure_logging
import loggingclass FilelogHandler(logging.FileHandler):def emit(self, record):msg = self.format(record)self.stream.write(msg + '\n')# Scrapy会设置一些默认设置,并在运行命令时借助scrapy.utils.log.configure_logging()来处理这些设置。
# 当Scrapy的命令行工具(如scrapy crawl)被执行时,它会自动调用configure_logging来设置默认的日志配置。这包括设置日志级别、输出格式、处理器等。
configure_logging({'LOG_FILE': 'baidu_spider.log','loggers': {'baidu_spider': {'level': 'DEBUG','handlers': ['file'],'propagate': True,},},'handlers': {'file': {'level': 'DEBUG','class': 'settings.FilelogHandler','filename': 'baidu_spider.log','append': True,}},
})在这个示例中,我们定义了一个自定义的FileLogHandler类,并将其添加到Scrapy的日志配置中。这样,Scrapy就会将日志信息输出到指定的文件myspider.log中。
请注意,为了正确实现自定义日志处理器,你需要根据具体的Scrapy版本和Python版本进行适当的调整。上述代码仅作为示例,实际使用时可能需要根据具体情况进行修改。
三、Scrapy日志级别详解
1、Scrapy支持的日志级别及其含义
Scrapy支持的日志级别及其含义如下:
●CRITICAL - 严重错误:这个级别用于记录系统中出现的严重错误,这些错误通常导致程序无法继续运行或需要立即关注。
●ERROR - 一般错误:记录系统运行时遇到的错误情况,但这些问题通常不会导致程序立即停止运行。
●WARNING - 警告信息:表示可能出现问题的情况,但这些问题不一定是错误,只是需要开发者的注意。
●INFO - 一般信息:记录程序运行时的常规信息,如启动、关闭、任务进度等。
●DEBUG - 调试信息:包含最详细的程序运行信息,通常用于开发或调试过程中,帮助开发者理解程序内部的运行情况。
在Scrapy中,默认的日志级别是DEBUG,这意味着所有DEBUG级别及以上的日志信息都会被记录。如果你只想看到ERROR级别或更高级别的日志信息,可以在Scrapy项目的settings.py文件中设置LOG_LEVEL = 'ERROR'。
此外,你也可以通过终端选项-loglevel/-L来设置日志级别。不同的日志级别可以帮助开发者根据需求快速定位问题,或者获取不同详细程度的程序运行信息。
2、日志级别的实际应用场景举例
DEBUG级别:在开发或调试Scrapy爬虫时,将日志级别设置为DEBUG是非常有用的。DEBUG级别会记录最详细的程序运行信息,包括请求和响应的详细信息、解析过程中的每一步操作等。这些信息有助于开发者深入了解爬虫的内部运行情况,发现并解决潜在的问题。
INFO级别:当爬虫开发完成后,进入测试或生产环境时,可以将日志级别设置为INFO。INFO级别会记录程序运行时的常规信息,如启动、关闭、任务进度等。这些信息可以帮助监控爬虫的运行状态,确保它按预期执行。
WARNING级别:在某些情况下,开发者可能只关心可能出现问题的情况,但不希望被过多的日志信息所干扰。此时,可以将日志级别设置为WARNING。WARNING级别会记录那些可能导致问题的操作或情况,但不会记录过多的细节信息。
ERROR级别:当爬虫在生产环境中运行时,开发者通常只关心出现的错误情况。此时,可以将日志级别设置为ERROR。ERROR级别只会记录程序运行时遇到的错误情况,帮助开发者快速定位并解决问题。
通过合理设置日志级别,开发者可以根据不同阶段的需求,获取适当详细程度的程序运行信息,从而更好地管理和维护Scrapy爬虫。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/138247107