目录
- 前言
- 软件设计简介
- 概要设计
- 模块化
- 模块化的评价
- 耦合
- 内聚
- 面向对象设计原则
- Liskov替换原则(LSP)
- 开放-封闭原则(OCP)
- 单一职责原则(SRP)
- 接口隔离原则(ISP)
- 依赖倒置原则(DIP)
- 类到数据库的映射
- 类图中关系到数据库的映射方法
前言
软件工程生命周期分为八个阶段:
问题定义—>可行性研究—>需求分析—>概要设计—>详细设计—>编码与单元测试—>综合测试—>软件维护这节我们讲的是软件开发流程中的一个阶段,概要设计。
软件设计简介
- 设计的定义
- 软件设计解决的是“怎么做”的问题。
- 软件设计是将需求描述的“做什么”问题变为一个实施方案的创造性的过程。
概要设计
概要设计从需求出发,从总体上描述系统架构以及应该包含的组成要素(模块),同时描述各个模块之间的关联。
概要设计包括:
- 体系结构设计
- 模块设计
- 接口设计
- 数据设计
模块化
就是把程序划分成独立命名且可独立访问的模块,每个模块完成一个子功能,把这些模块集成起来构成一个整体,可以完成指定的功能满足用户的需求。
模块化的优点:
- 易于维护
- 易于分工合作
- 易于扩充功能
- 易于模块化测试
模块化的评价
设计遵循的原则之一——模块独立:
希望这样设计软件结构,使得每个模块完成一个相对独立的特定子功能,并且和其他模块之间的关系很简单。
模块独立程度的两个定性标准度量:
- 耦合度
- 内聚度
耦合:
如果改变程序中的一个模块,要求另一个模块也同时发生改变,就认为这两个模块发生了耦合。
- 衡量不同模块彼此间互相依赖(连接)的紧密程度。
- 紧密:耦合高
- 不紧密:耦合低
- 期望低耦合
内聚:
内聚描述了一个模块内部各个元素彼此关联程度的度量。高内聚意味着模块内的元素彼此关联紧密,都围绕着同一个目标或功能。低内聚则表示模块内的元素关联较少,可能是一些不相关的功能被放在了同一个模块中。
- 衡量一个模块内部各个元素(属性、方法)彼此结合的紧密程度。
- 期望高内聚
耦合

- 非直接耦合
- 如果两个模块中的每一个都能独立地工作而不需要另一个模块的存在,那么它们完全独立。
- 在一个软件系统中不可能存在一个和所有模块之间都没有任何关系的独立模块。
- 数据耦合
如果两个模块彼此间通过参数交换信息,而且交换的信息仅仅是数据,那么这种耦合称为数据耦合。
评价:- 系统中至少必须存在这种耦合。一般说来,一个系统内可以只包含数据耦合。
- 数据耦合是理想的目标
- 维护更容易,对一个模块的修改不会使另一个模块产生退化错误
- 控制耦合
如果两个模块彼此间传递的信息中有控制信息,这种耦合称为控制耦合。
比如:
一个模块A调用另一个模块B,并且在模块B执行完特定的操作后,模块A根据模块B的执行结果来决定自己的下一步动作,或者模块C根据模块B的执行结果来执行不同的结果,或者模块B的每种结果会导致不同模块的调用,这些都是控制耦合。- 控制耦合往往是多余的,把模块适当分解之后通常可以用数据耦合代替它。
- 被调用的模块需知道调用模块的内部结构和逻辑,降低了重用的可能性 。
- 特征耦合
当把整个数据结构作为参数传递而被调用的模块只需要使用其中一部分数据元素时,就出现了特征耦合。
示例:
现有一个班的成绩息表,包含学号,姓名,年龄,班级,籍贯等数据项。
要求编写函数对该班年龄进行修改。 - 公共环境耦合
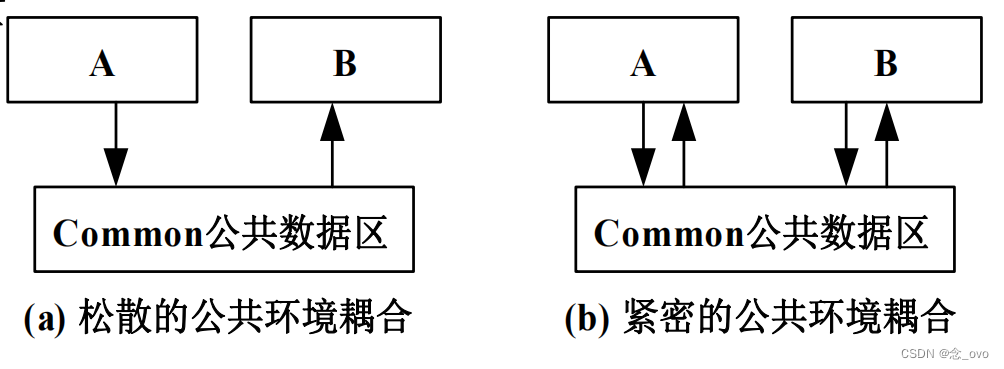
公共环境耦合是指两个或多个模块之间共享了同一份数据或资源,这些数据或资源处于公共的环境中,多个模块都可以读取或修改它们。这种耦合方式下,各个模块之间通过访问公共的环境来进行通信和交互。
示例:
多个模块共享同一个全局变量或配置文件。如果多个模块都依赖于该全局变量或配置文件中的数据,那么它们之间就存在公共环境耦合。如果其中一个模块修改了这个全局变量或配置文件中的数据,可能会影响到其他模块的行为。
- 内容耦合
最高程度的耦合是内容耦合。
如果出现下列情况之一,两个模块间就发生了内容耦合:- 一个模块访问另一个模块的内部数据;(重点)
- 一个模块不通过正常入口转到另一个模块的内部
- 两个模块有一部分程序代码重叠;
- 一个模块有多个入口。
内聚

偶然内聚、逻辑内聚、时间内聚属于低内聚,不建议用
过程内聚、通信内聚属于中内聚,不建议使用
-
偶然内聚
如果一个模块的各成分之间毫无关系,则称为偶然内聚。
例如:统计学生英语的平均成绩 和修改id为xx的老师的基本信息
或者发现一组语句在两处或多处出现,于是把这些语句作为一个模块以节省内存,也是偶然内聚。例如:

- 模块内各元素之间没有实质性联系,很可能在一种应用场合需要修改这个模块,在另一种应用场合又不允许这种修改,从而陷入困境;
- 可理解性差,可维护性产生退化;
- 模块是不可重用的。
-
逻辑内聚
如果一个模块完成的任务在逻辑上属于相同或相似的一类,则称为逻辑内聚。
举例:一个子程序将打印季度开支报告、月份开支报告和日开支报告.具体打印哪一个,将由传入的控制标志决定,这个子程序具有逻辑内聚性,因为它的内部逻辑是由输进的外部控制标志决定的。- 接口难以理解,造成整体上不易理解;
- 完成多个操作的代码互相纠缠在一起,即使局部功能的修改有时也会影响全局,导致严重的维护问题;
- 难以重用。
-
时间内聚
如果一个模块包含的任务必须在同一段时间内执行,就叫时间内聚。
例如:初始化模块。初始化模块要为所有全局变量赋初值,对所有介质上的文件置初态,初始化寄存器和栈等,因此要求在程序开始执行的最初一段时间内,模块中所有功能全部执行一遍。- 时间关系在一定程度上反映了程序某些实质,所以时间内聚比逻辑内聚好一些
- 模块内操作之间的关系很弱,与其他模块的操作却有很强的关联
- 时间内聚的模块不太可能重用
-
过程内聚
如果一个模块内的处理元素是相关的,而且必须以特定次序执行,则称为过程内聚。
这些操作原本并不需要关联到一起,只是因为人为的赋予特定的顺序。
比如,银行接收用户信息模块,要求:必须是先输入身份证号(审核),后输入姓名,然后是密码(密码)- 比时间内聚好,至少操作之间是过程关联的。
- 仍是弱连接,不太可能重用模块
-
通信内聚
如果模块中所有元素都使用同一个输入数据和(或)产生同一个输出数据,则称为通信内聚。即在同一个数据结构上操作。
例如:操作某个数据时,先查找该数据是否存在,然后再执行相应的增删改操作。 (具体操作可以通过调用函数实现)
例如:统计数学成绩的平均成绩及80分以上人数- 模块中各操作紧密相连,比过程内聚更好。
- 不能重用
-
顺序内聚
如果一个模块的各个成分和同一个功能密切相关,而且这些处理必须顺序执行(一个成分的输出作为另一个成分的输入),则称为顺序内聚。
例如某模块:完成工业产值求值的功能。
第一个功能:求总产值,
第二个功能: 求平均产值。
显然该模块内两部分紧密关联。 -
功能内聚
如果一个模块内所有处理元素(每个处理都是必不可少)属于一个整体,完成一个单一的功能,则称为功能内聚。功能内聚是最高程度的内聚。- 模块可重用,应尽可能重用;
- 可隔离错误,维护更容易;
- 扩充产品功能时更容易。
面向对象设计原则
Liskov替换原则(LSP)
“若对每个类型S的对象O1,都存在一个类型T的对象O2,使得在所有针对T编写的程序P中,用O1替换O2后,程序P的行为不变,则S是T的子类型”——Liskov替换原则。
强调的是子类必须能够替换其父类而不影响程序的正确性。也就是说,子类型应该能够模拟基类型的行为,实现基类型所定义的所有约束和规范。
开放-封闭原则(OCP)
对扩展开放:
软件实体应该允许在不修改现有代码的情况下进行扩展。这意味着,当需要添加新的功能或行为时,应该通过添加新的代码来实现,而不是修改已有的代码。
对修改封闭:
软件实体的行为应该是稳定的,不应该因为系统的变化而需要频繁地修改。一旦一个模块、类或函数被设计和实现,就应该封闭起来,确保它的行为不受外部影响。
强调的是软件实体应该对扩展开放,对修改封闭。也就是说,软件实体应该允许在不修改现有代码的情况下进行扩展。
单一职责原则(SRP)
SRP 的核心思想是一个类或模块应该有且仅有一个引起它变化的原因,或者说一个类或模块应该只有一个职责。
SRP 强调的是高内聚和低耦合的设计原则。一个类或模块应该包含相关性高的功能,而不应该包含无关的功能,从而使得代码更加清晰、可读、可维护。
接口隔离原则(ISP)
“使用多个专门的接口比使用单一的总接口要好”
ISP使得接口的职责明确,有利于系统的维护
依赖倒置原则(DIP)
“高层模块不应该依赖于底层模块,两者都应该依赖于抽象。
核心思想:“依赖于抽象”
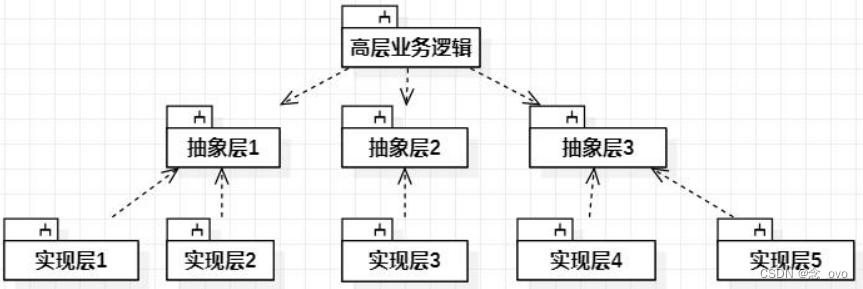
- 由客户(即高层模块)来定义并公开接口,而底层去实现这些接口,即客户提出他需要的服务,底层去实现这些服务。
- 这样当底层实现逻辑发生变化时,高层模块不受影响。
类到数据库的映射
类图中的属性映射成表的字段。
- 一般地,类中的属性是单值的,但如果在类中存在多值属性,则该属性映射成多个字段。

类图中关系到数据库的映射方法
- 关联关系
(1)一对一关联:两个实体分别映射两张表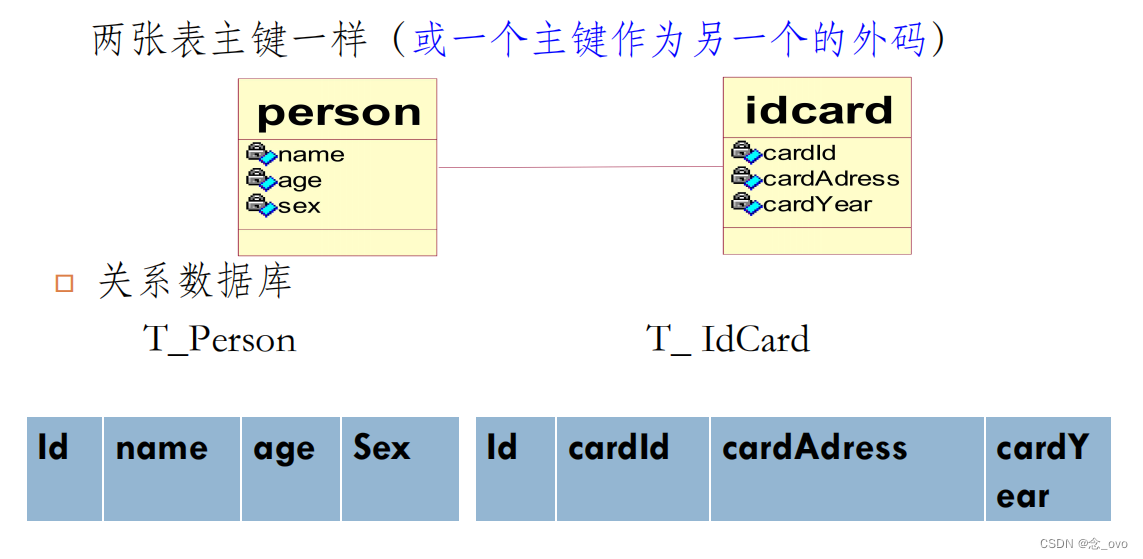
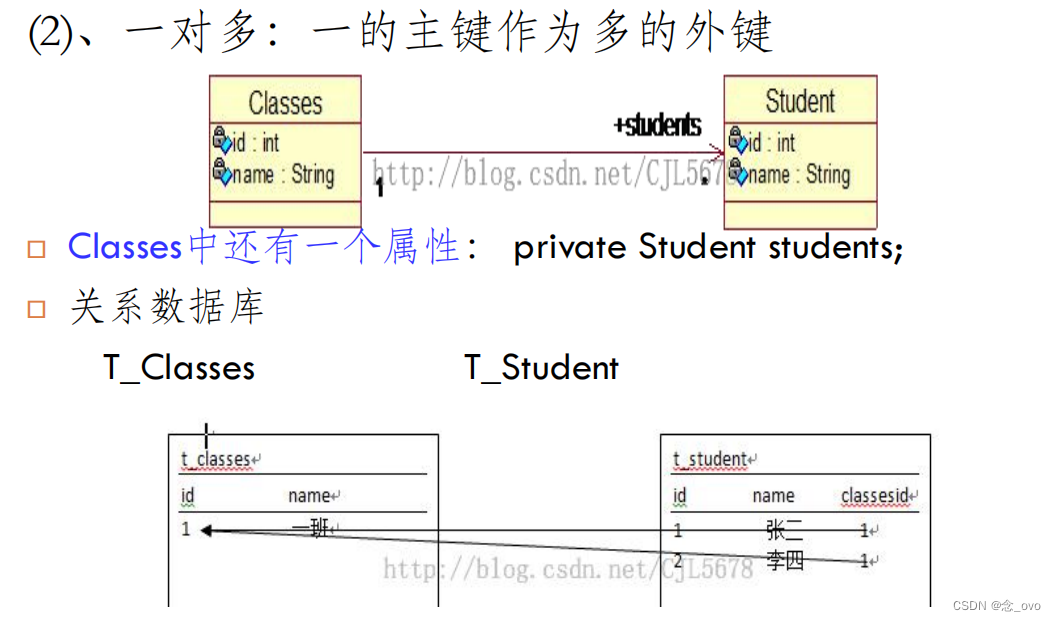
(2)一对多关联
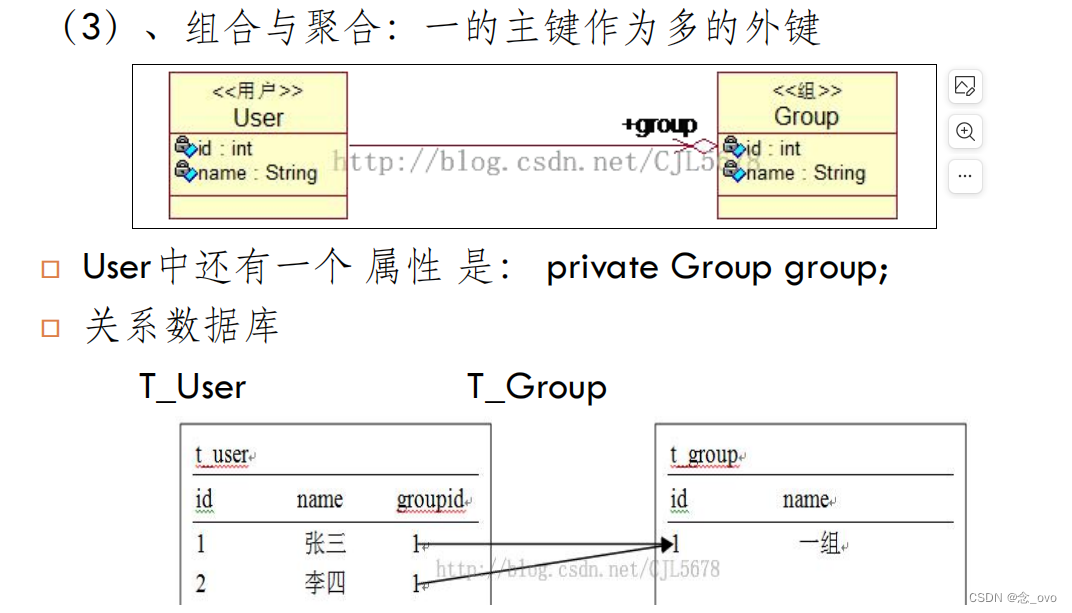
(3)组合和聚合:
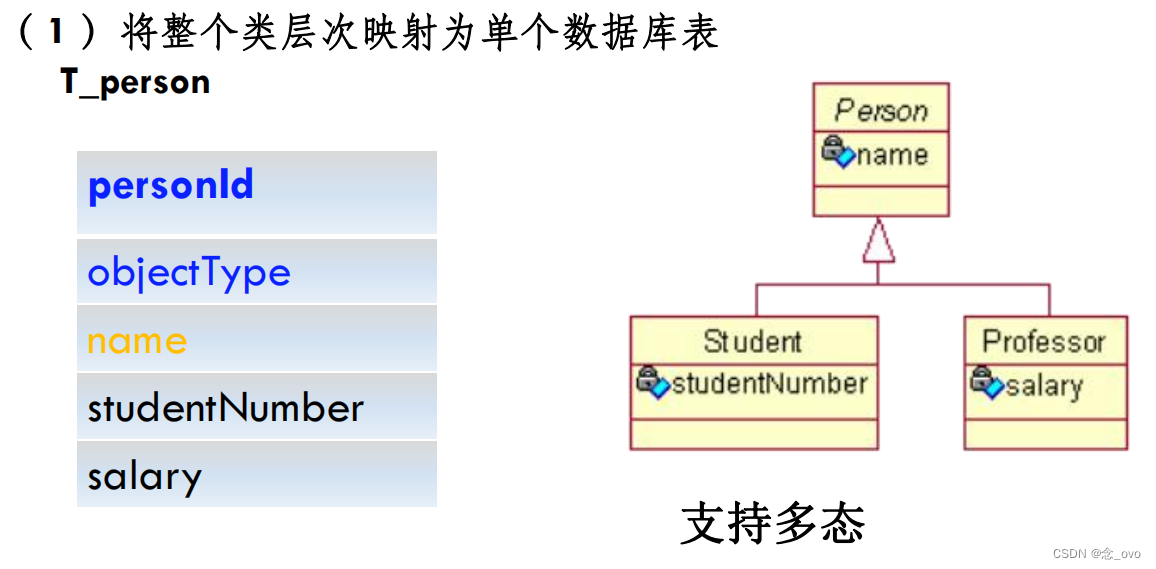
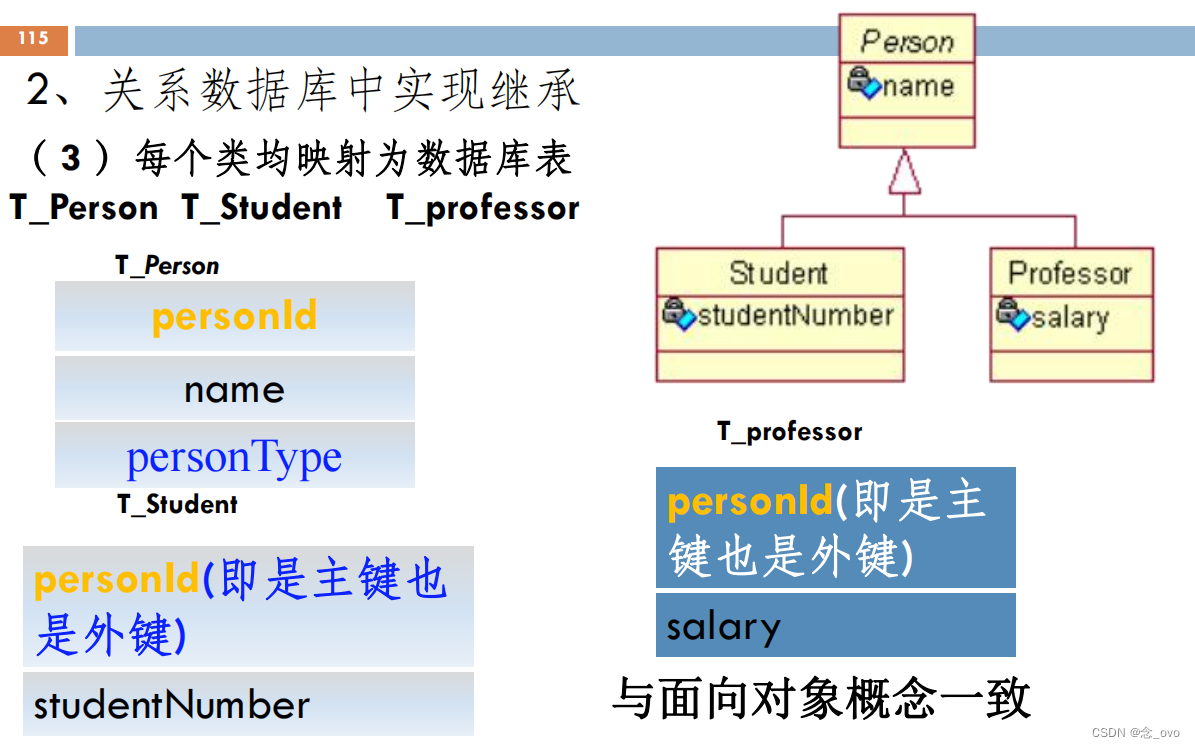
- 关系数据库中实现继承