引言
聚类分析是一种常用的无监督学习技术,旨在将数据集中的样本分成具有相似特征的组。K均值聚类是其中一种常见的方法,它通过将数据点划分为K个簇,并使每个数据点与其所属簇的中心点距离最小化来实现聚类。本文将介绍如何使用R语言执行K均值聚类,并以鸢尾花(Iris)数据集为例进行说明。
数据集介绍
鸢尾花数据集是一个经典的多变量数据集,由英国统计学家罗纳德·费舍尔于1936年收集。该数据集包含了150个样本,每个样本代表一种鸢尾花,共分为三类:山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica)。每个样本有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
研究目的
本文的目标是利用K均值聚类方法对鸢尾花数据集进行聚类分析,以探索数据中可能存在的群组结构,并可视化聚类结果。
实现步骤
1. 导入数据集和必要的库
首先,我们导入iris数据集,并加载所需的R包。
# 导入iris数据集
data(iris)

2. 数据预处理
我们需要将数据集中的标签列去掉,以便进行聚类分析。
# 去掉数据集中的标签
iris_features <- iris[, -5]

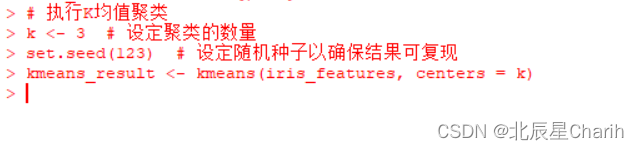
3. 执行K均值聚类
接下来,我们使用kmeans函数执行K均值聚类。
# 执行K均值聚类
k <- 3 # 设定聚类的数量
set.seed(123) # 设定随机种子以确保结果可复现
kmeans_result <- kmeans(iris_features, centers = k)
4. 分析聚类结果
我们打印出聚类的结果,包括每个点所属的簇以及簇的中心。
# 打印聚类结果
print(kmeans_result)

5. 可视化聚类结果
最后,我们使用clusplot函数可视化聚类结果。
# 可视化聚类结果
library(cluster)
clusplot(iris_features, kmeans_result$cluster, color=TRUE, shade=TRUE,labels=2, lines=0)

结果展示
执行上述代码后,我们可以得到聚类的结果。通过可视化结果,我们可以清晰地看到数据点在不同簇之间的分布情况,以及簇中心的位置。
结论
本文使用R语言对鸢尾花数据集进行了K均值聚类分析。通过对聚类结果的分析和可视化,我们可以更好地理解数据中的潜在群组结构。聚类分析为我们提供了一种无监督学习的方法,可以用于探索数据集中的内在模式和结构,为后续的数据分析和建模工作提供了重要的参考依据。
总结
聚类分析是一种强大的数据分析技术,可以帮助我们发现数据集中的潜在结构和模式。在本文中,我们介绍了如何使用R语言执行K均值聚类,并以鸢尾花数据集为例进行了演示。通过本文的学习,读者可以掌握基本的聚类分析方法,并将其应用于自己的数据集中。