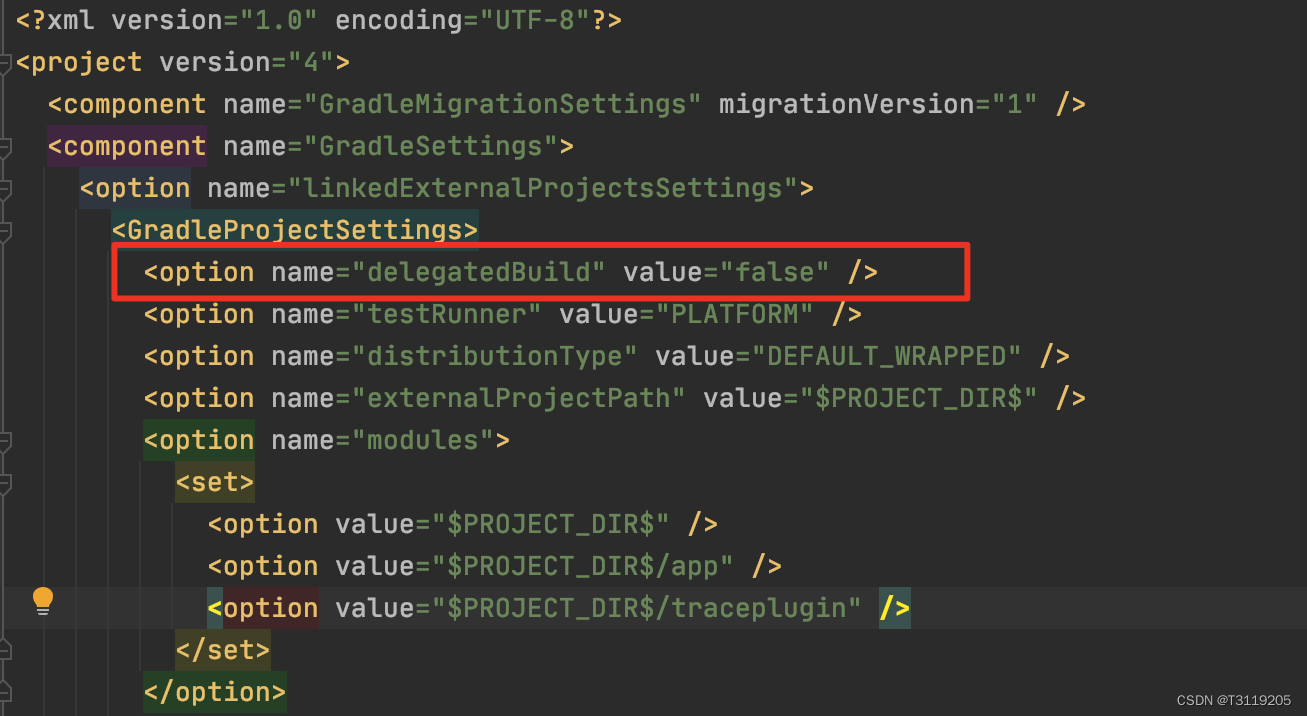
调整语音识别准确性
- 精度差的原因
- 测试数据库设置
- 运行测试
语音识别的准确性并不总是很高。
首先,重要的是要了解您的准确性是否只是低于预期,还是总体上非常低。如果总体精度非常低,则您很可能错误配置了解码器。如果低于预期,可以采用各种方法来改进。
您应该做的第一件事是收集测试样本数据库并测量识别准确性。您需要将话语转储到 wav 文件中,编写参考文本并使用解码器对其进行解码。然后使用 Sphinxtrain 的工具计算字错误率 (WER) word_align.pl。测试数据库的大小取决于准确性,但通常有 30 分钟的转录音频就足以可靠地测试识别器的准确性。
只有拥有测试数据库,您才能继续优化识别精度。
精度差的原因
精度不佳的主要原因是:
-
传入音频的采样率和通道数不匹配或传入音频带宽不匹配。它必须是 16 kHz(或 8 kHz,具体取决于训练数据)、16 位 Mono(= 单通道)Little-Endian 文件。您需要通过重采样来修复源的采样率(仅当其采样率高于训练数据的采样率时)。您不应该对文件进行上采样并使用在更高采样率的音频上训练的声学模型对其进行解码。可以使用命令验证音频文件格式(采样率、通道数)
sox --i /path/to/audio/file在此处查找更多信息: 什么是采样率?
-
声学模型不匹配。为了验证这个假设,您需要根据测试数据库文本构建一个语言模型。这样的语言模型会非常好,并且一定会给你很高的准确率。如果精度仍然较低,则需要在声学模型上进行更多工作。您可以使用声学模型自适应来提高准确性。
-
语言模型不匹配。您可以创建自己的语言模型来匹配您尝试解码的词汇。
-
字典中的不匹配以及单词的发音。在这种情况下,必须在语音词典中完成一些工作。
测试数据库设置
要测试识别,您需要使用所需的参数配置解码,特别是,您需要有一个语言模型<your.lm>。有关更多详细信息,请参阅构建语言模型页面。
创建一个fileids文件test.fileids:
test1
test2创建转录文件test.transcription:
some text (test1)
some text (test2)将音频文件放入wav文件夹中。确保这些文件具有正确的格式和采样率。
└─ wav├─ test1.wav└─ test2.wav运行测试
现在,让我们运行解码器:
pocketsphinx_batch \-adcin yes \-cepdir wav \-cepext .wav \-ctl test.fileids \-lm `<your.lm>` \ # for example en-us.lm.bin from pocketsphinx-dict `<your.dic>` \ # for example cmudict-en-us.dict from pocketsphinx-hmm `<your_hmm>` \ # for example en-us-hyp test.hypword_align.pl test.transcription test.hyp该word_align.pl脚本是 sphinxtrain 发行版的一部分。
如果您要解码 8 kHz 文件,请务必将该选项添加-samprate 8000到上述命令!
Sphinxtrain 的脚本word-align.pl将向您报告准确的错误率,您可以使用该错误率来确定改编是否适合您。它看起来像这样:
TOTAL Words: 773 Correct: 669 Errors: 121
TOTAL Percent correct = 86.55% Error = 15.65% Accuracy = 84.35%
TOTAL Insertions: 17 Deletions: 11 Substitutions: 93要查看解码速度,请检查 pocketsphinx 日志,它应该如下所示:
INFO: batch.c(761): 2484510: 9.09 seconds speech, 0.25 seconds CPU, 0.25 seconds wall
INFO: batch.c(763): 2484510: 0.03 xRT (CPU), 0.03 xRT (elapsed)是0.03 xRT解码速度(“记录时间的0.03倍”)。