大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用29-卷积神经网络(CNN)中的变种:分组卷积、转置卷积、空洞卷积的计算过程。分组卷积将输入通道分为几组,对每组独立进行卷积操作,以减少计算量和模型参数。转置卷积也称为反卷积,它通过将输入特征图的元素扩展到更高维度的输出特征图来执行上采样。空洞卷积通过在输入特征图上引入“空洞”或“间隙”来增加感受野,从而在不增加额外参数的情况下扩大卷积核的有效覆盖范围。这些变种在CNN中用于解决不同的问题,如提高计算效率、实现上采样和扩大感受野等。
文章目录
一、卷积神经网络的简述
卷积是一种在图像处理和深度学习中广泛使用的数学运算,特别是在卷积神经网络(CNN)中。它通过在输入数据上滑动一个小的窗口(或称为“卷积核”或“过滤器”),并将卷积核中的值与输入数据相应位置的值相乘,然后将这些乘积求和,得到一个输出值。这个过程在整个输入数据上重复进行,以产生一个特征图(feature map),这个特征图描述了输入数据中与卷积核匹配的模式。
卷积的基本操作:
- 定义卷积核:首先定义一个卷积核,这是一个小的权重矩阵,用于在输入数据上滑动。例如,一个3x3的卷积核可以表示为:
K = [ k 11 k 12 k 13 k 21 k 22 k 23 k 31 k 32 k 33 ] K = \begin{bmatrix} k_{11} & k_{12} & k_{13} \\ k_{21} & k_{22} & k_{23} \\ k_{31} & k_{32} & k_{33} \end{bmatrix} K= k11k21k31k12k22k32k13k23k33 - 滑动卷积核:将卷积核在输入数据上滑动,覆盖输入数据的一个局部区域。例如,对于一个5x5的输入图像 I I I,卷积核会从左上角开始,每次移动一个像素,直到覆盖整个图像。
- 元素相乘并求和:在每个位置,将卷积核的元素与输入图像的相应元素相乘,并将所有乘积求和。例如,如果卷积核的中心位于输入图像的左上角,计算如下:
O u t p u t ( 1 , 1 ) = k 11 × I 11 + k 12 × I 12 + k 13 × I 13 + k 21 × I 21 + k 22 × I 22 + k 23 × I 23 + k 31 × I 31 + k 32 × I 32 + k 33 × I 33 Output_{(1,1)} = k_{11} \times I_{11} + k_{12} \times I_{12} + k_{13} \times I_{13}+ \\ k_{21} \times I_{21} + k_{22} \times I_{22} + k_{23} \times I_{23}+ \\ k_{31} \times I_{31} + k_{32} \times I_{32} + k_{33} \times I_{33} Output(1,1)=k11×I11+k12×I12+k13×I13+k21×I21+k22×I22+k23×I23+k31×I31+k32×I32+k33×I33 - 应用激活函数:通常,在卷积操作之后会应用一个非线性激活函数,如ReLU,来增加网络的非线性。
与全连接层的区别:
- 局部连接:卷积层具有局部连接性,即每个卷积核只与输入数据的一个局部区域连接,而不是与所有输入数据连接。这减少了参数的数量,并允许网络捕获局部特征(如边缘、角点等)。
- 参数共享:在卷积层中,卷积核的权重在整个输入数据上是共享的,这意味着无论卷积核在输入数据上的位置如何,都使用相同的权重。这进一步减少了参数的数量。
- 平移不变性:卷积层具有平移不变性,即即使输入数据中的模式位置发生变化,卷积层仍能检测到该模式。
相比之下,全连接层中的每个神经元都与前一层中的所有神经元相连,这导致了大量的参数。全连接层没有局部连接性和参数共享,因此它们在处理高维输入(如图像)时效率较低,并且不容易捕获局部特征。
计算例子:
假设我们有一个5x5的灰度图像 I I I和一个3x3的卷积核 K K K:
I = [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ] , K = [ 1 0 − 1 1 0 − 1 1 0 − 1 ] I = \begin{bmatrix} 1 & 2 & 3 & 4 & 5 \\ 6 & 7 & 8 & 9 & 10 \\ 11 & 12 & 13 & 14 & 15 \\ 16 & 17 & 18 & 19 & 20 \\ 21 & 22 & 23 & 24 & 25 \end{bmatrix}, \quad K = \begin{bmatrix} 1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1 \end{bmatrix} I= 16111621271217223813182349141924510152025 ,K= 111000−1−1−1
当卷积核的中心位于输入图像的左上角时(即覆盖 I 11 , I 12 , I 13 , I 21 , I 22 , I 23 , I 31 , I 32 , I 33 I_{11}, I_{12}, I_{13}, I_{21}, I_{22}, I_{23}, I_{31}, I_{32}, I_{33} I11,I12,I13,I21,I22,I23,I31,I32,I33),计算得到的输出为:
O u t p u t ( 1 , 1 ) = 1 × 1 + 0 × 2 + ( − 1 ) × 3 + 1 × 6 + 0 × 7 + ( − 1 ) × 8 + 1 × 11 + 0 × 12 + ( − 1 ) × 13 = − 4 Output_{(1,1)} = 1 \times 1 + 0 \times 2 + (-1) \times 3+ \\ 1 \times 6 + 0 \times 7 + (-1) \times 8+ \\ 1 \times 11 + 0 \times 12 + (-1) \times 13 = -4 Output(1,1)=1×1+0×2+(−1)×3+1×6+0×7+(−1)×8+1×11+0×12+(−1)×13=−4
这个输出将是特征图中的一个元素。卷积核将继续滑动,直到覆盖整个输入图像,生成整个特征图。
+
在上面的例子中,卷积核 K K K是一个简单的边缘检测器,它对垂直边缘的响应最大。当卷积核滑过图像时,它会突出显示图像中的垂直边缘,因为垂直边缘上的像素值变化会与卷积核中的正负权重相乘,从而产生较大的输出值。
卷积操作的输出大小取决于几个因素:输入图像的大小、卷积核的大小、步幅(stride)和填充(padding)。如果卷积核的大小为 k × k k \times k k×k,输入图像的大小为 W × H W \times H W×H,步幅为 s s s,填充为 p p p,则输出特征图的大小 O O O可以表示为:
O = ⌊ W − k + 2 p s + 1 ⌋ × ⌊ H − k + 2 p s + 1 ⌋ O = \left\lfloor \frac{W - k + 2p}{s} + 1 \right\rfloor \times \left\lfloor \frac{H - k + 2p}{s} + 1 \right\rfloor O=⌊sW−k+2p+1⌋×⌊sH−k+2p+1⌋
其中, ⌊ x ⌋ \left\lfloor x \right\rfloor ⌊x⌋表示向下取整。
例如,如果我们的输入图像是5x5,卷积核是3x3,步幅是1,没有填充( p = 0 p = 0 p=0),那么输出特征图的大小将是:
O = ⌊ 5 − 3 + 2 × 0 1 + 1 ⌋ × ⌊ 5 − 3 + 2 × 0 1 + 1 ⌋ = 3 × 3 O = \left\lfloor \frac{5 - 3 + 2 \times 0}{1} + 1 \right\rfloor \times \left\lfloor \frac{5 - 3 + 2 \times 0}{1} + 1 \right\rfloor = 3 \times 3 O=⌊15−3+2×0+1⌋×⌊15−3+2×0+1⌋=3×3
这意味着我们将得到一个3x3的特征图,其中每个元素都是卷积核在输入图像上相应位置的卷积结果。
卷积操作通过局部连接和参数共享,有效地捕捉了输入数据的局部特征,并且减少了模型的参数数量,使得网络更加高效。这与全连接层形成了鲜明的对比,全连接层在处理高维数据时参数数量庞大,且无法有效地捕捉局部特征。因此,在处理图像和视频数据时,卷积神经网络(CNN)成为了首选的模型架构。
二、分组卷积的简述
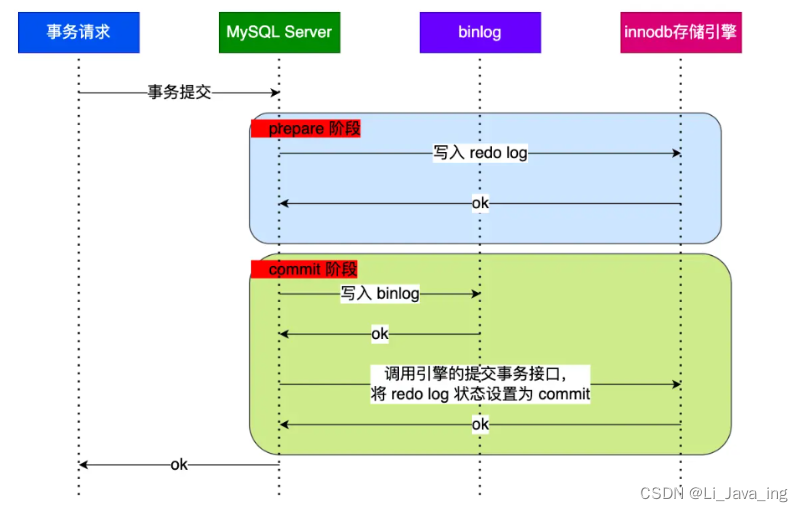
分组卷积(Grouped Convolution)是一种特殊的卷积形式,它在深度神经网络中用于减少参数数量和计算量,同时也能够增加模型的非线性。在分组卷积中,输入特征图和卷积核被分成若干组,每一组内部进行常规的卷积操作,而不同组之间不进行交叉运算。
分组卷积的基本操作:
- 输入特征图分组:假设输入特征图的深度为 D D D,将其分为 G G G组,每组包含 D G \frac{D}{G} GD个通道。
- 卷积核分组:同样,将卷积核的深度也分为 G G G组,每组包含与输入特征图相同数量的通道,即每组有 D G \frac{D}{G} GD个卷积核。
- 独立卷积:对每组输入特征图和卷积核进行独立的卷积操作。每组内部的卷积操作与标准的卷积相同。
- 输出特征图拼接:将每组卷积操作的结果拼接起来,形成输出特征图。如果每组卷积操作后输出的特征图深度为 M M M,则最终输出特征图的深度为 G × M G \times M G×M。
应用场景:
分组卷积在以下场景中特别有用:
- 减少参数和计算量:分组卷积通过将输入特征图和卷积核分组,减少了每组的参数数量和计算量。这在设计轻量级网络或移动设备上的应用时非常有用。
- 多路特征学习:分组卷积允许网络同时学习多个独立的特征表示,这有助于网络捕捉更丰富的特征。
- 残差网络(ResNet):在残差网络中,分组卷积可以用来减少连接两个残差块之间的shortcut路径上的参数数量。
计算例子:
假设我们有一个输入特征图,其大小为 H × W × D H \times W \times D H×W×D,其中 D = 64 D = 64 D=64,我们想要应用一个 3 × 3 × 64 3 \times 3 \times 64 3×3×64的卷积核,但是使用分组卷积,将输入特征图和卷积核分为 G = 4 G = 4 G=4组。
每组包含 D G = 64 4 = 16 \frac{D}{G} = \frac{64}{4} = 16 GD=464=16个通道。因此,每组内的卷积操作是一个 3 × 3 × 16 3 \times 3 \times 16 3×3×16的卷积。
如果每组卷积操作后输出的特征图深度为 M M M,则最终输出特征图的深度为 G × M = 4 × M G \times M = 4 \times M G×M=4×M。
分组卷积的参数数量为:
Params = k × k × D G × M × G = 3 × 3 × 16 × M × 4 \text{Params} = k \times k \times \frac{D}{G} \times M \times G = 3 \times 3 \times 16 \times M \times 4 Params=k×k×GD×M×G=3×3×16×M×4
这比标准卷积的参数数量 k × k × D × M k \times k \times D \times M k×k×D×M要少得多,其中 k k k是卷积核的大小。
分组卷积的一个典型例子是AlexNet,它是第一个在大规模图像识别竞赛中取得突破性成果的深度学习模型。AlexNet在网络的某些层使用了分组卷积,以减少计算量并允许更大的网络容量。
三、转置卷积的简述
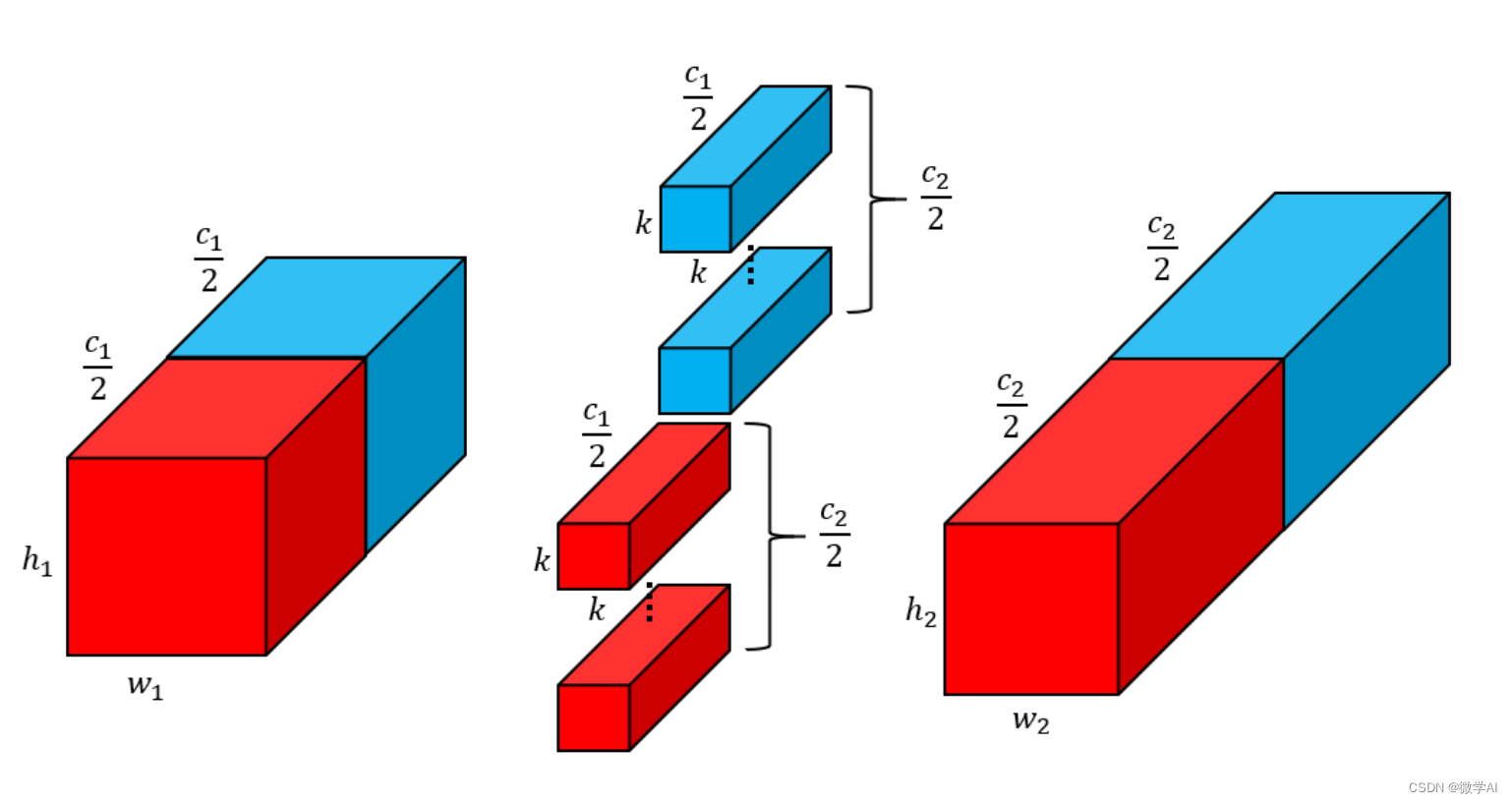
转置卷积(Transposed Convolution),也称为反卷积(Deconvolution)或分数步长卷积(Fractionally Strided Convolution),是一种特殊的卷积形式,它用于在卷积神经网络(CNN)中上采样特征图。与常规卷积操作不同,常规卷积会通过滑动窗口和步幅来减小特征图的尺寸,转置卷积则可以增加特征图的尺寸。
转置卷积的基本操作:
- 填充和步幅:转置卷积首先对输入特征图进行填充(zero-padding),然后应用步幅(stride)大于1的卷积。这种操作使得输出特征图的尺寸大于输入特征图。
- 卷积核:转置卷积使用的卷积核与常规卷积相同,但是应用的方式不同。在转置卷积中,卷积核在输入特征图上的滑动方式使得输出特征图的尺寸增加。
- 上采样:通过填充和步幅的操作,转置卷积实现了上采样的效果,即将输入特征图的尺寸扩大。
应用场景:
转置卷积在以下场景中特别有用:
- 图像上采样:在生成图像或语义分割任务中,转置卷积用于将低分辨率图像上采样到高分辨率。
- 特征图维度恢复:在卷积神经网络中,转置卷积可以用于在池化操作之后恢复特征图的尺寸。
- 密集预测任务:在需要生成像素级预测的任务中,如语义分割,转置卷积用于将低维特征图映射到高维空间。
计算例子:
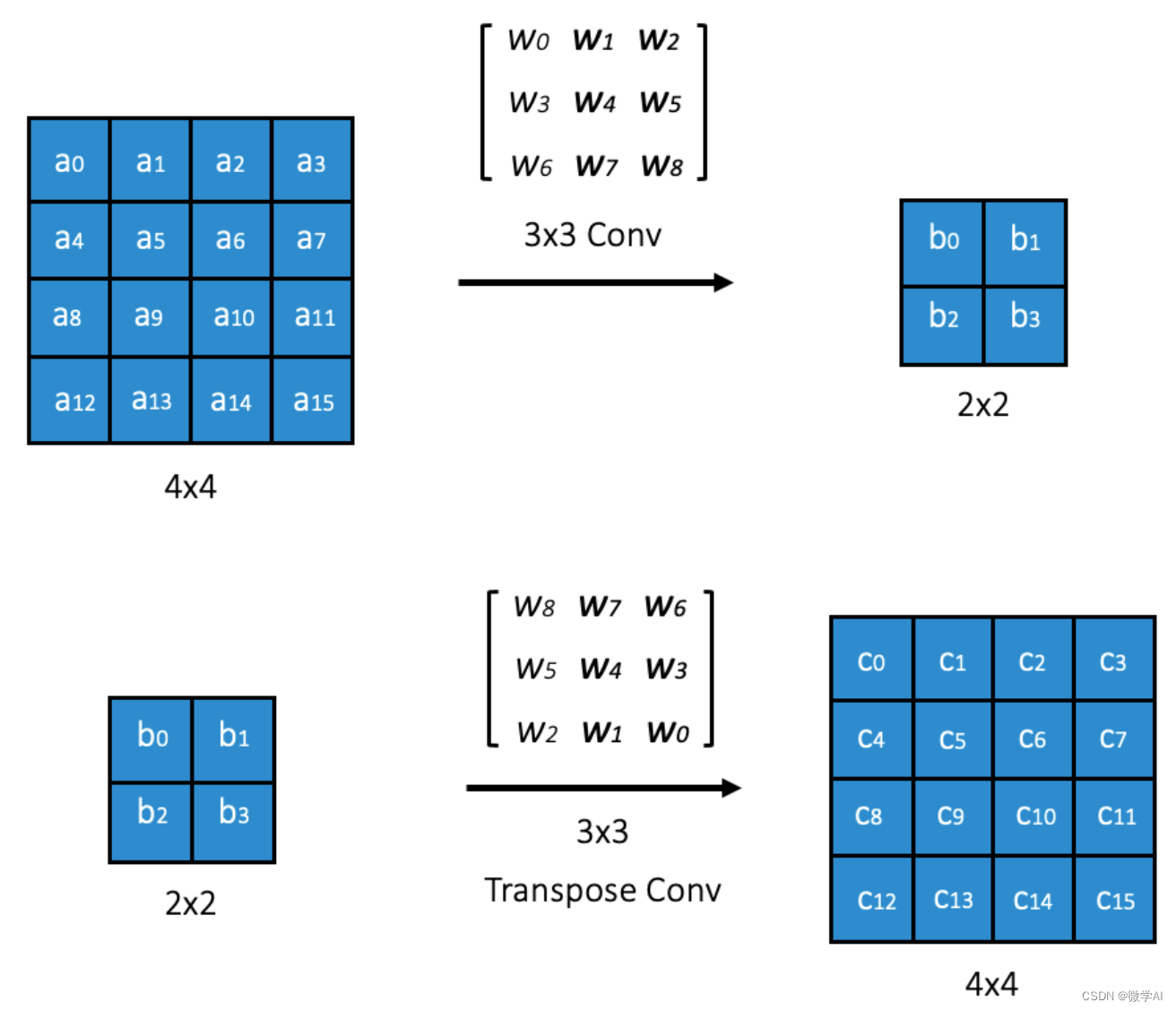
假设我们有一个 2 × 2 2 \times 2 2×2的输入特征图,我们想要通过转置卷积将其上采样到 4 × 4 4 \times 4 4×4的尺寸。我们可以使用一个 3 × 3 3 \times 3 3×3的卷积核,步幅为2,无填充( p = 0 p = 0 p=0)。
转置卷积的输出大小 O O O可以通过以下公式计算:
O = ( I − 1 ) × s − 2 p + k O = (I - 1) \times s - 2p + k O=(I−1)×s−2p+k
其中, I I I是输入特征图的尺寸, s s s是步幅, p p p是填充, k k k是卷积核的尺寸。
在我们的例子中,输入特征图的尺寸是 2 × 2 2 \times 2 2×2,步幅 s = 2 s = 2 s=2,填充 p = 0 p = 0 p=0,卷积核尺寸 k = 3 k = 3 k=3,所以输出特征图的尺寸是:
O = ( 2 − 1 ) × 2 − 2 × 0 + 3 = 4 O = (2 - 1) \times 2 - 2 \times 0 + 3 = 4 O=(2−1)×2−2×0+3=4
这意味着输出特征图的尺寸将是 4 × 4 4 \times 4 4×4。
转置卷积的一个典型例子是在生成对抗网络(GANs)中,用于将低维特征向量转换为高分辨率的图像。在GANs的生成器部分,转置卷积用于逐步上采样特征图,最终生成与真实图像尺寸相同的合成图像。
四、空洞卷积的简述
空洞卷积(Dilated Convolution),也称为扩张卷积,是一种卷积操作的变体,它通过在卷积核之间插入“空洞”来增加感受野,而不增加参数数量或计算量。这种操作允许卷积层在保持相同参数数量的同时,覆盖更大的输入区域,从而捕捉更广泛的上下文信息。
空洞卷积的基本操作:
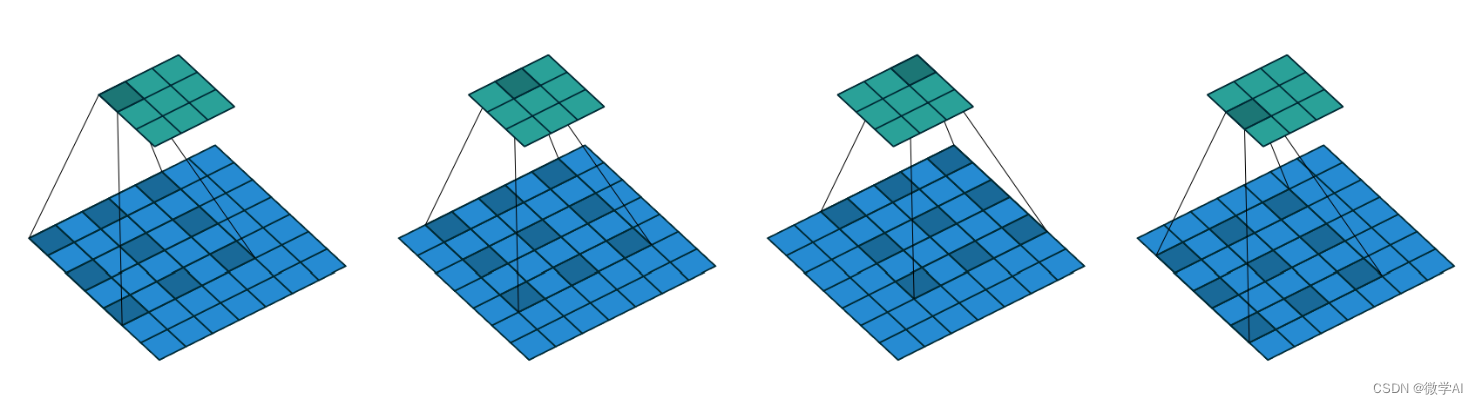
- 定义空洞率:空洞卷积通过一个称为“空洞率”(dilation rate)的参数来控制卷积核之间的间隔。空洞率定义了卷积核中的元素之间的间隔大小。例如,对于一个3x3的卷积核和空洞率2,卷积核的有效大小相当于5x5,但实际上只有9个参数。
- 应用卷积核:在应用卷积核时,根据空洞率在输入特征图上跳过一些像素。这相当于在卷积核之间插入“空洞”,从而在不增加参数数量的情况下增加感受野。
- 计算输出:除了跳过像素外,空洞卷积的计算方式与传统卷积相同。每个卷积核的元素与输入特征图上的相应元素相乘,然后将乘积求和得到输出特征图的一个元素。
应用场景:
空洞卷积在以下场景中特别有用:
- 增加感受野:在保持计算成本不变的情况下,空洞卷积允许网络捕捉更广泛的上下文信息,这对于需要大感受野的任务(如语义分割)非常有用。
- 保持分辨率:在传统的卷积神经网络中,多次卷积和池化操作会逐渐降低特征图的分辨率。空洞卷积可以在不降低分辨率的情况下增加感受野,这对于需要高分辨率输出的任务很有帮助。
- 减少参数数量:对于资源受限的环境,如移动设备,空洞卷积提供了一种在不增加参数数量的情况下增加模型容量的方法。
计算例子:
假设我们有一个 7 × 7 7 \times 7 7×7的输入特征图,我们想要应用一个 3 × 3 3 \times 3 3×3的卷积核,但使用空洞卷积,设置空洞率为2。
在标准卷积中, 3 × 3 3 \times 3 3×3卷积核会覆盖输入特征图上连续的 3 × 3 3 \times 3 3×3区域。但在空洞卷积中,由于空洞率为2,卷积核在输入特征图上的覆盖区域将变成 7 × 7 7 \times 7 7×7,但仍然只有9个参数。
空洞卷积的输出特征图大小 O O O可以通过以下公式计算:
O = I + 2 p − k − ( k − 1 ) × ( d − 1 ) s + 1 O = \frac{I + 2p - k - (k - 1) \times (d - 1)}{s} + 1 O=sI+2p−k−(k−1)×(d−1)+1
其中, I I I是输入特征图的尺寸, p p p是填充, k k k是卷积核的尺寸, d d d是空洞率, s s s是步幅。
在我们的例子中,输入特征图的尺寸是 7 × 7 7 \times 7 7×7,卷积核尺寸 k = 3 k = 3 k=3,空洞率 d = 2 d = 2 d=2,无填充( p = 0 p = 0 p=0),步幅 s = 1 s = 1 s=1,所以输出特征图的尺寸是:
O = 7 + 2 × 0 − 3 − ( 3 − 1 ) × ( 2 − 1 ) 1 + 1 = 5 O = \frac{7 + 2 \times 0 - 3 - (3 - 1) \times (2 - 1)}{1} + 1 = 5 O=17+2×0−3−(3−1)×(2−1)+1=5
这意味着输出特征图的尺寸将是 5 × 5 5 \times 5 5×5。
空洞卷积的一个典型例子是在DeepLab系列网络中,它是一种用于语义分割的卷积神经网络架构。DeepLab利用空洞卷积来增加感受野,从而能够捕捉到更大范围的上下文信息,提高分割的准确性。