前言
大型语言模型(LLM)虽然在生成文本方面表现出色,但仍然存在一些局限性:数据是静态的,而且缺乏垂直细分领域的知识。为了克服这些限制,有时候会进行进一步的模型训练和微调。在实际应用中,我们也常常会运用到RAG技术。
什么是RAG
RAG(Retrieval-Augmented Generation)是一种融合了检索(Retrieval)和生成(Generation)的自然语言处理技术,用于增强大型语言模型(LLM)的性能。RAG的核心思想是让模型在生成回答时,不仅依赖于其内部知识,还能利用外部的信息源,如数据库或知识库,来提供更准确、更丰富的答案。
RAG的基本工作流程通常包括以下几个步骤:
检索(Retrieve):根据用户的查询,从外部知识源检索相关的上下文信息。这通常涉及到使用嵌入模型将用户查询转换为向量,并在向量数据库中执行相似性搜索,以找到最相关的信息。
增强(Augment):将检索到的上下文信息与用户原始查询结合,形成一个新的增强提示(prompt),这个提示将用于引导语言模型生成回答。
生成(Generate):最后,将增强后的提示输入到大型语言模型中,生成最终的回答。
RAG在多种应用场景中都非常有用,包括但不限于问答系统、事实核查、内部工具等。通过RAG,大型语言模型能够提供更加准确和上下文相关的回答,从而提高整体的AI应用性能。
1. 检索(Retrieve)
1.1 检索(Retrieve)之使用搜索引擎
搜索引擎是一种常用的快速检索与查询相关文档的工具,使用搜索引擎可以为语言模型提供更准确的上下文信息,帮助生成更准确的回答。
例如,一些AI厂商在其产品中提供了联网功能,调用搜索引擎进行关键字搜索。用户可以在其产品中输入查询,系统将自动在互联网上进行搜索,并将互联网上的相关结果用于生成回答,极大地丰富了回答的准确性和深度。
下图来自Kimi的网页:

另外,许多企业级应用也采用搜索引擎(如Elasticsearch)来完成站内的检索任务。Elasticsearch是一个基于Lucene的搜索引擎,通过分布式、RESTful风格的搜索和分析引擎,能够即时地存储、搜索和分析大量数据。
然而,关键字搜索的局限性在于它只能快速检索到与用户查询的相同关键字的文档,而无法处理语义相近但关键字不同的情况。
1.2 检索(Retrieve)之文本嵌入(embedding)技术
为了解决语义识别的问题,文本嵌入(embedding)技术应运而生。
在自然语言处理(NLP)中,文本嵌入技术能够将文本字符串转化为高维空间的向量表示,从而衡量不同文本之间的相似性和相关性。这些向量捕捉了文本的含义,并且可以用于进行比较、搜索和聚类等自然语言处理任务。
embedding模型
以OpenAI为例。OpenAI目前最新的embedding模型为其3代,即text-embedding-3-small和text-embedding-3-large。 默认情况下,对于text-embedding-3-small模型,嵌入向量的维度将是1536;对于text-embedding-3-large模型,维度将是3072。用户可以根据需要通过传递dimensions参数来调整嵌入的维度,以在速度和准确率之间取得平衡。
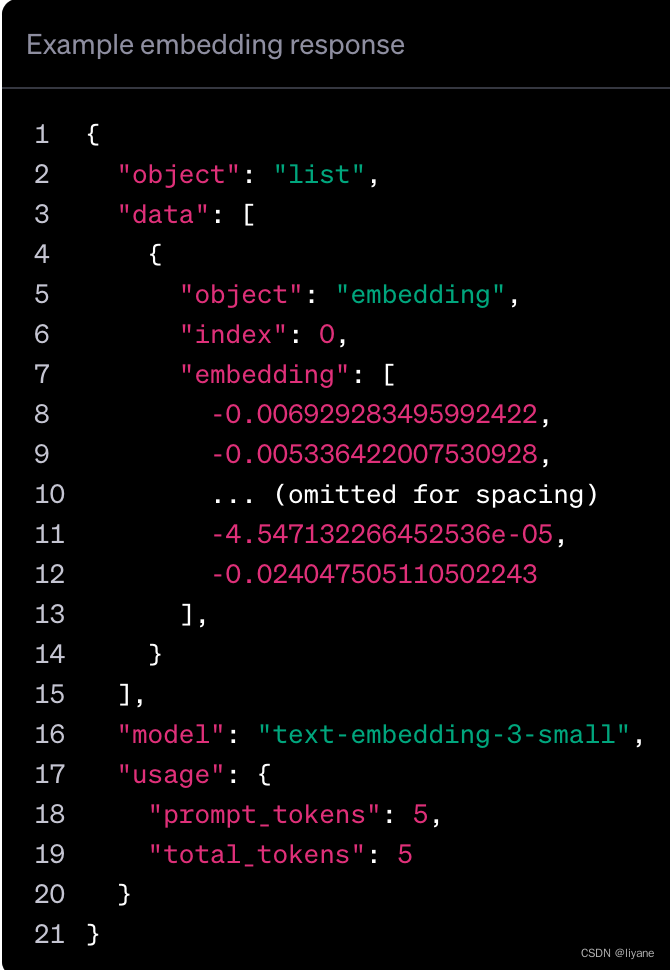
下图来自OpenAI网站,为embedding接口的返回结果:
向量数据库
随着AI的发展,处理向量数据的向量数据库变得越来越重要。这些数据库专门设计用于存储、管理和检索向量形式的数据。
使用向量数据库的过程包括分割文档,计算文本段落的embedding,存储原始数据和对应的embedding,并利用用户提出的查询进行相似性搜索。
2. 增强(Augment)
现在我们将检索到的上下文信息与用户原始查询结合,形成一个新的增强提示(prompt),这个提示将用于引导语言模型生成回答。
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。已知信息:
{context}用户问:
{query}如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
3. 生成(Generate)
最后,将增强后的提示输入到大型语言模型中,生成最终的回答。
后续
在接下来的文章中,我将使用LlamaIndex技术来实现RAG,进一步探讨RAG在实际应用中的实现。
参考
OpenAI embeddings
OpenAI cookbook - Get embeddings from dataset
OpenAI cookbook - Vector databases