在当前的检测项目中,需要一个高效且准确的算法来处理大量的图像数据。经过一番研究和比较,初步选择了YOLOv5作为算法工具。YOLOv5是一个基于深度学习的检测算法,以其快速和准确而闻名。它不仅能够快速处理图像数据,还能提供较高的检测准确率。
配置环境
环境准备: 在进行YOLOv5的训练和预测之前,我们需要确保环境已经准备好。以下是具体的步骤:
-
创建虚拟环境: 使用conda创建一个新的虚拟环境,命名为yolov5。
conda create -n yolov5 python=3.8 -
激活虚拟环境: 激活刚刚创建的yolov5虚拟环境。
conda activate yolov5 -
安装依赖包: 安装必要的依赖包,这里以GPU环境为例。
pip install ultralytics -
克隆YOLOv5项目: 从GitHub克隆YOLOv5项目。
git clone https://github.com/ultralytics/yolov5 -
进入项目目录: 进入克隆的YOLOv5项目目录。
cd yolov5 -
安装项目依赖: 安装项目中的依赖包。
pip install -r requirements.txt注意:
requirements.txt中的troch版本需要与你的硬件资源和CUDA版本相匹配。如果不匹配,可能无法启动GPU进行训练。
通过以上步骤,我们确保了环境已经准备好,可以顺利进行YOLOv5的训练和预测。接下来,将介绍如何进行训练。
训练
使用官方数据或者自己按照coco格式进行标注的数据都可以很简单的开始进行训练。如果是自我标注数据的话,数据格式:
images:文件夹里放原始图片;labels:文件夹里放标注的标签文件;
训练是深度学习模型的核心环节,它决定了模型的性能和准确性。YOLOv5提供了强大的训练功能,允许用户根据自己的需求进行定制。以下是一个基本的训练命令示例,以及每个参数的含义:
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
-–data coco.yaml:指定训练数据集的配置文件。-–epochs 300:设置训练的轮数(epoch)。-–weights:指定预训练模型的权重,如果使用空字符串,则不加载预训练权重。-–cfg yolov5n.yaml:指定配置文件,用于定义模型的结构和训练参数。-–batch-size 128:设置每次迭代处理的图像数量
以上命令可以再现 YOLOv5 COCO 的效果。模型和数据集将从 YOLOv5 的最新版本中自动下载。在 V100 GPU 上,模型可选YOLOv5n/s/m/l/x,对应 的训练时间分别为 1/2/4/6/8 天(使用多 GPU 训练将更快)。尽可能使用大的 --batch-size 值(16,32,64,128),或者传递 --batch-size -1 以启用 YOLOv5 的自动批量处理功能。显示的批量大小适用于 V100-16GB GPU。训练的时候也可以加入预训练模型和多GPU--weights ./pre-models/yolov5m.pt --device 0,1
可选的预训练模型如下表所示,按照精度和推理时间选择适合自己的模型:
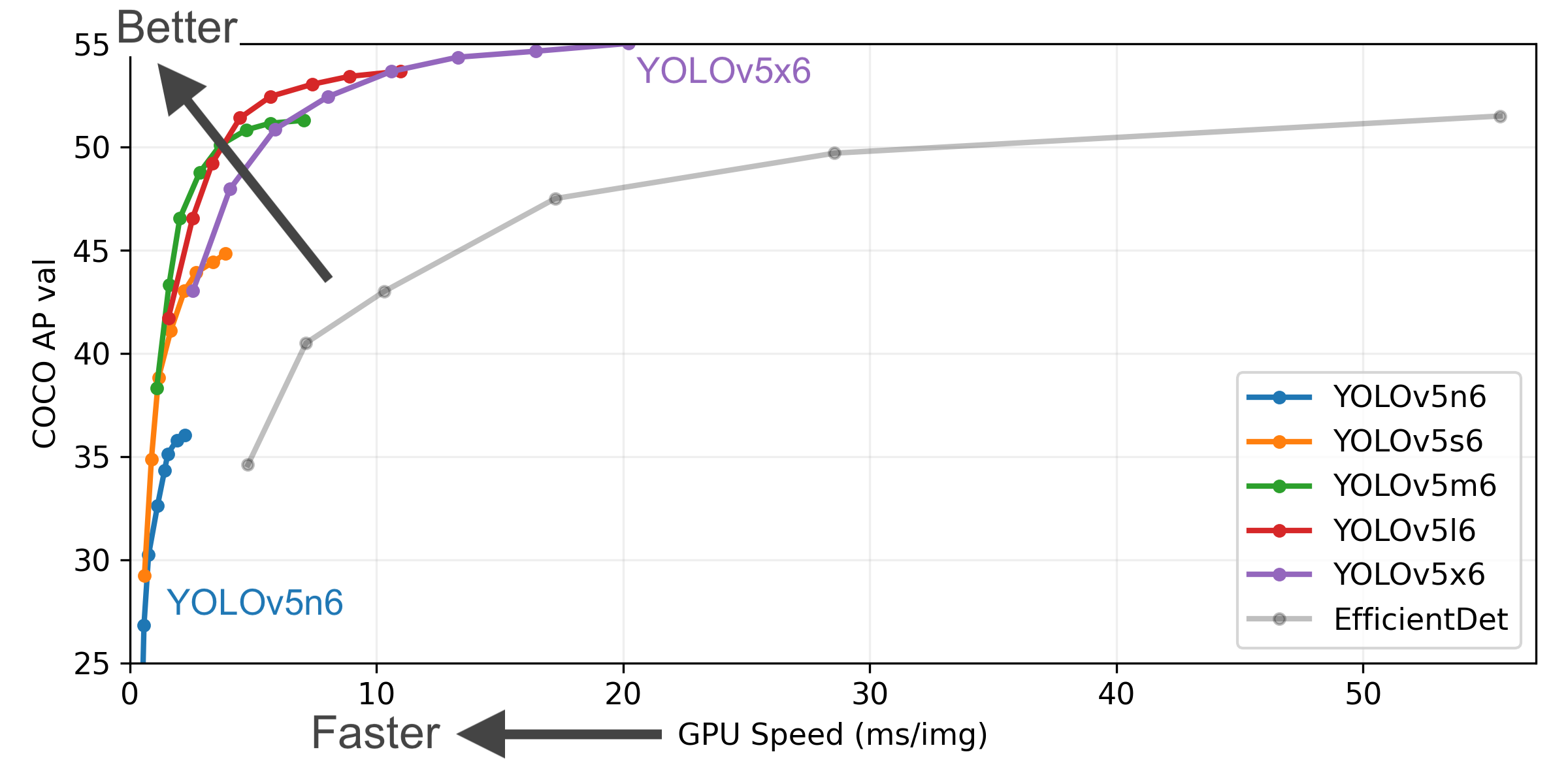
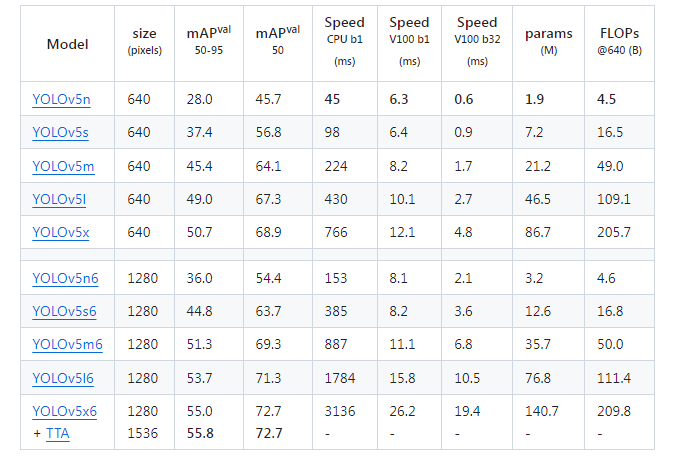
- 所有检查点均按照默认设置训练了 300 个epoch。
- Nano 和 Small 模型采用了 hyp.scratch-low.yaml 的超参数配置,而其他模型则采用了 hyp.scratch-high.yaml。
- mAPval 值指的是在 COCO val2017 数据集上,单模型单尺度的评估结果。 通过以下命令可以复现这一结果:
python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - 速度是在 AWS p3.2xlarge 实例上,对 COCO val 图像集进行平均测量的。NMS 时间(约每张图像 1 毫秒)未计入其中。 使用以下命令复现速度测试:
python val.py --data coco.yaml --img 640 --task speed --batch 1 - TTA(测试时间增强)包括反射和尺度增强。 通过以下命令可以复现 TTA:
python val.py --data coco.yaml --img 1536 --iou 0.7 --augment
预测
预测是深度学习模型的最终目的,它将训练好的模型应用于实际数据,以实现目标检测。YOLOv5提供了便捷的预测功能,可以快速对图像或视频进行目标检测。
使用项目已有的detect.py文件进行预测
detect.py可在各种不同的来源上执行推理任务,它会自动从最新的 YOLOv5 版本中下载所需的模型或者使用已训练好的模型,并将推断结果保存到 runs/detect 文件夹中。
python detect.py --weights yolov5s.pt --source img.jpg # image
weights:指定模型的权重文件,这里使用预训练的yolov5s模型,如果本地有的话就不下载,如果没有的话就网上进行下载;source:除了图片,YOLOv5还支持多种输入源,包括视频、网络摄像头、屏幕截图等。可以根据需要选择合适的输入源。0: # webcamimg.jpg# imagevid.mp4# videoscreen# screenshotpath/# directorylist.txt# list of imageslist.streams# list of streams'path/*.jpg'# glob'https://youtu.be/LNwODJXcvt4'# YouTube'rtsp://example.com/media.mp4'# RTSP, RTMP, HTTP stream
使用torch.hub进行预测
YOLOv5 PyTorch Hub 提供自动推理服务。所需的模型将从最新的 YOLOv5 版本自动下载。
import torch# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom# Images
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list# Inference
results = model(img)# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
上述内容就是从网络上下载模型并进行推理,如果想使用自己的模型的话进行推理,这里对其进行了封装,代码如下:
import os
import sys
import json
import torch
import numpy as npCURRENT_DIR = os.path.abspath(os.path.dirname(__file__)) + '/'class Detector:"""implement detector"""def __init__(self):# load modelself.model = torch.hub.load(os.path.join(CURRENT_DIR, './'), 'custom',path=os.path.join(CURRENT_DIR, './yolov5s.pt'),source='local', device='cpu')def detect_img(self, img_file):"""detect from inputArgs:file, Path, PIL, OpenCV, numpy, list"""# inferenceresults = self.model(img_file)crops = results.crop(save=False) # cropped detections dictionaryreturn cropsif __name__ == '__main__':dt = Detector()img = sys.argv[1]detect_res = dt.detect_img(img)print(detect_res)
这里使用results.crop是因为这个返回的信息会比较多,返回的结果包含预测的标签,置信度,以及检测区域等,便于后续业务逻辑处理。
总结
YOLO系列算法是检测算法里面非常实用的一种工具项目,能够在工业界得到很好的使用。本文介绍了一下Yolov5的训练及预测流程,便于大家使用以及后续自己回顾使用。