目录
1、生产者消息发送流程
1.1、发送原理
2、异步发送 API
2.1、普通异步发送
2.2、带回调函数的异步发送
3、同步发送 API
4、生产者分区
4.1、分区的优势
4.2、生产者发送消息的分区策略
示例1:将数据发往指定 partition
示例2:有 key 的情况下将数据发送到Kafka
4.3、自定义分区器
5、生产者提高吞吐量
6、数据可靠性
7、数据去重
1、幂等性
8、生产者事务
1、事务原理
2、使用事务
9、数据的有序
注:示例代码使用的语言是Python
1、生产者消息发送流程
1.1、发送原理
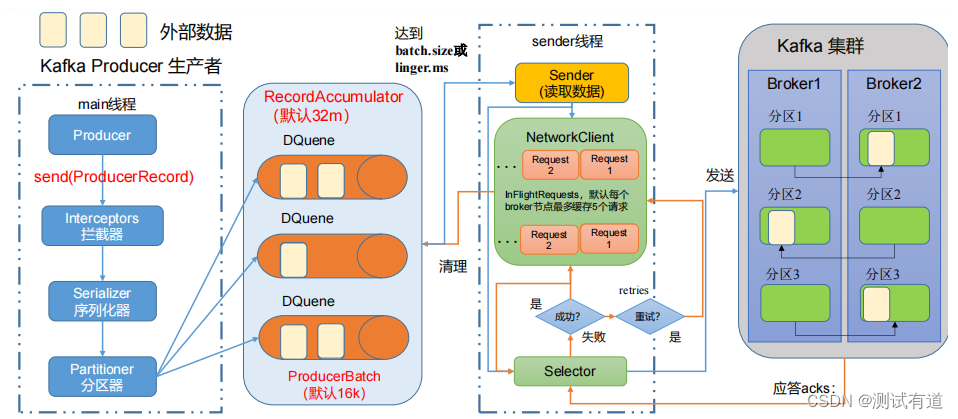
- 在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程 中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
参数说明:
- batch size:只有数据积累到batch.size之后,sender才会发送数据。默认16K
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后在发送是数据。单位ms,默认值为0ms,表示没有延迟。
- acks:
- 0:生产者发送过来的数据不需要等待应答,异步发送。
- 1:生产者发送过来的数据,需要等待Leader收到后应该。
- -1(all):生产者发送过来的数据,Leader和ISR(In-Sync Replicas)队列里面所有的节点收齐数据后应答。注:-1与all等价
2、异步发送 API
2.1、普通异步发送
示例:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 初始化生产者对象,bootstrap_servers参数传入kafka集群# 将acks的值设为0,acks=0,此方式也是异步的方式,但是生产环境中不会这样使用,因为存在数据丢失的风险# producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks=0)producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)producer.close()if __name__ == '__main__':msg = "this is profucer01"topic = "first"producer(topic, msg)2.2、带回调函数的异步发送
- 回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元 数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发 送成功,如果 Exception 不为 null,说明消息发送失败。
- 注意:消息发送失败会自动重试,不需要在回调函数中手动重试。
"""
带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),
如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
"""
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 定义发送成功的回调函数def on_send_success(record_metadata):print("消息成功发送到主题:", record_metadata.topic)print("分区:", record_metadata.partition)print("偏移量:", record_metadata.offset)# 定义发送失败的回调函数def on_send_error(excp):print("发送消息时出现错误:", excp)# 可以根据实际情况执行一些错误处理逻辑# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition).add_callback(on_send_success).add_errback(on_send_error)producer.close()3、同步发送 API
- 只需在异步发送的基础上,再调用一下 get()方法即可。或者将acks的值设为all,acks="all",此方式也是同步的方式。
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 初始化生产者对象,bootstrap_servers参数传入kafka集群# 将acks的值设为all,acks="all",此方式也是同步的方式.# producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks="all")producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)# 等待 Future 返回结果,设置超时时间为10秒future.get(timeout=10)producer.close()4、生产者分区
4.1、分区的优势
- 1、便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一 块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- 2、提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
4.2、生产者发送消息的分区策略
- 1、如果不指定分区,会使用默认分区策略。默认分区策略如下:
- 如果key存在的情况下,将key的hash值与topic的partition进行取余得到partition值
- 如果key不存在的情况下,会随机选择一个分区
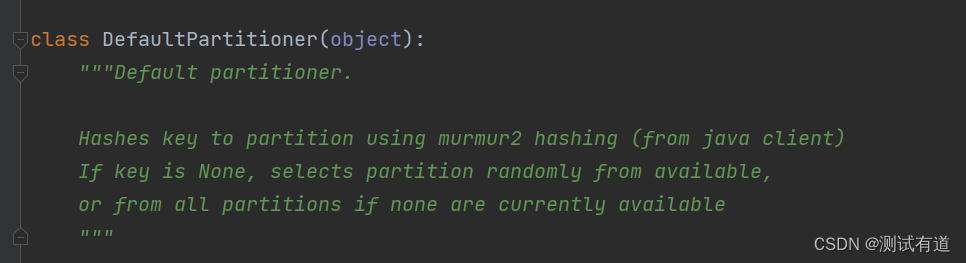
- 2、如果指明了分区,那么将会把数据发送到指定分区
示例1:将数据发往指定 partition
-
将所有数据发往分区 0 中。
# 指定分区
def producer_01(topic: str, msg: str, partition=0):""":function: 指定分区:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "this is partition"
topic = "first"
for i in range(5):producer_01(topic, msg+str(i))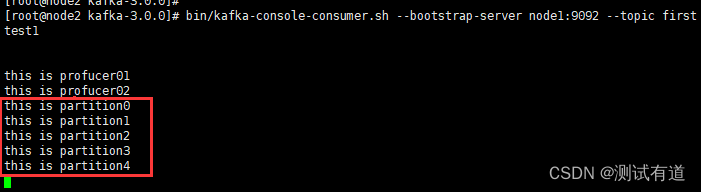
示例2:有 key 的情况下将数据发送到Kafka
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取 余得到 partition 值。
# 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值。
def producer_02(topic: str, msg: str, key: str):""":function: 指定分区:param topic: 写入数据所在的topic:param msg: 写入的数据:param key: 发送消息的key值:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, key=bytes(key, 'utf-8'), value=bytes(msg, 'utf-8'))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "this is partition"
topic = "first"
key = "a"
for i in range(5):producer_02(topic, msg+str(i), key)4.3、自定义分区器
- 可以根据实际需要,自定义实现分区器。
- 示例:自定义分区 发送过来的数据中如果包含 hello,就发往 0 号分区,不包含 hello,就发往 1 号分区。
# 自定义分区 发送过来的数据中如果包含 hello,就发往 0 号分区,不包含 hello,就发往 1 号分区。
def producer_03(topic: str, msg: str):""":function: 自定义分区:param topic: 写入数据所在的topic:param msg: 写入的数据:return:"""# 自定义分区器def my_partitioner(msg):if "hello" in str(msg):return 0else:return 1# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=my_partitioner(msg))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "hello this is partition"
msg1 = "this is partition"
5、生产者提高吞吐量
- 实际工作中,会根据实际的情况动态的调整生产者的吞吐量以适应实际需求,调整吞吐量主要是通过调整以下参数实现:
- batch.size:批次大小,默认16k
- linger.ms:等待时间,修改为5-100ms
- compression.type:压缩snappy
- RecordAccumulator:缓冲区大小,默认32m,修改为64m
"""
生产者提高吞吐量1、linger.ms:等待时间,修改为5-100ms2、compression.type:压缩snappy3、RecordAccumulator:缓冲区大小,修改为64m
"""
from kafka3 import KafkaProducer
from kafka3.errors import KafkaErrordef producer(topic: str, msg: str):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],linger_ms=5, # linger_ms设置为5mscompression_type="snappy", # 设置压缩类型为snappybuffer_memory=64*1024*1024 # 设置缓冲区大小为64MB)# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")6、数据可靠性
说明:数据的可靠性保证主要是通过acks的设置来保证的,下面说明acks在不同取值下的数据可靠性情况:
- acks=0时
- 因为生产者发送数据后就不管了,所以当Leader或Follower发生异常时,就会发生数据丢失。
- 实际使用很少
- acks=1时
- 因为生产者只需要等到Leader应答后就算完成本次发生了,但是当Leader应答完成后,还没有开始同步副本数据,Leader此时挂掉,新的Leader上线后并不会收到丢失数据,因为生产者已经认为数据发送成功了,这时就会发生数据丢失。
- 实际使用:一般用于传输普通日志
- acks=-1时
- 因为生产者需要等到Leader和Follower都收到数据后才算完成本次数据传输,所以可靠性高,但是当分区副本只有1个或者ISR应答的最小副本设置为1,此时和acks=1时效果一样,存在数据丢失的风险。
- 实际使用:对可靠性要求较高的场景中,比如涉及到金钱相关的场景
综上分析:要想使得数据完全可靠条件=ACK级别设置为1 + 分区副本数大于等于2 + ISR应答最小副本数大于等于2(min.insync.replicas 参数保证)
Python代码设置acks
# acks取值:0、1、"all"
producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks=0)7、数据去重
- 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2;可以保证数据不丢失,但是不能保证数据不重复。
- 最多一次(At Most Once)= ACK级别设置为0;可以保证数据不重复,但是不能保证数据不丢失。
那么如何保证数据只存储一次呢?这就需要使用幂等性。
1、幂等性
1、幂等性:
- 1、幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
- 2、精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
2、幂等性实现原理:
- 具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。
- 其 中PID是Kafka每次重启都会分配一个新的;
- Partition 表示分区号;
- Sequence Number 每次发送消息的序列号,是单调自增的。
- 注意:幂等性只能保证的是在单分区单会话内不重复。
3、使用幂等性
- 开启参数 enable_idempotence 默认为 true,false 关闭。
- 目前的 kafka3 库并不支持直接设置生产者的幂等性。在 Kafka 中启用幂等性需要使用 kafka-python 或其他支持 Kafka 协议的库。
- 以下是使用 kafka-python 库设置生产者的幂等性的示例代码:
from kafka import KafkaProducer# 创建 KafkaProducer 实例,开启幂等性
producer = KafkaProducer(bootstrap_servers="127.0.0.1:9092",acks="all", # 设置 acks 参数为 "all",要求所有副本都确认消息enable_idempotence=True
)8、生产者事务
说明:开启事务必须开启幂等性。
1、事务原理
存储事务信息的特殊主题:__transaction_state_分区_Leader
- 默认有50个分区,每个分区负责一部分事务。
- 事务划分是根据transaction.id的hash值%50,计算出该事物属于哪个分区。
- 该分区Leader副本所在的broker节点即为这个transaction.id对应的Transaction Coordinator节点。
注意事项:生产者在使用事务功能之前,必须先自定义一个唯一的transaction.id。有了该transaction.id,即使客户端挂掉了,它重启之后也能继续处理未完成的事务。
2、使用事务
from kafka import KafkaProducer
from kafka.errors import KafkaError# 创建 KafkaProducer 实例,开启事务
producer = KafkaProducer(bootstrap_servers="127.0.0.1:9092",enable_idempotence=True # 开启幂等性
)# 初始化事务
producer.init_transactions()# 开始事务
producer.begin_transaction()try:# 发送事务性消息for i in range(3):key = b"my_key"value = b"my_value_%d" % iproducer.send("my_topic", key=key, value=value)# 提交事务producer.commit_transaction()except KafkaError as e:# 回滚事务producer.abort_transaction()print(f"发送消息失败: {e}")finally:# 关闭 KafkaProducer 实例producer.close()9、数据的有序性
说明:数据的有序性只能保证单分区有序,分区与分区之间是无序的。
1、Kafka在1.x版本之前保证数据单分区有序,条件如下:
- max.in.flight.requests.per.connection=1 (不需要开启幂等性)
2、Kafka在1.x版本之后保证数据单分区有序,条件如下:
- 未开启幂等性
- 设置:max.in.flight.requests.per.connection=1
- 开启幂等性
- 设置:max.in.flight.requests.per.connection 小于等于5
- 原因:因为在Kafka1.x以后,启用幂等性,Kafka服务端会缓存生产者发来的最近5个request的元数据,所以至少可以保证最近5个request的数据都是有序的。