目录
🍸前言
🍻一、Elasticsearch 基本属性
1.1 ES VS MySQL
1.2 ES 属性概念
1.3 ES 的增删改查
🍺二、自动补全场景
2.1 场景举例
2.2 使用数据分词器
2.3 查询的流程
2.4 整个查询流程图
🍹章末
🍸前言
上次初步了解到 Elasticsearch 的基本使用,并且完成 ES 服务安装, ES 服务浏览器插件安装, ES 可视化客户端安装,以及 IK 分词器的安装,踩了很多坑,好在全部解决了。基于以上安装配置,来熟悉下 ES 的各种属性。本地安装的链接如下:
【Elasticsearch<一>✈️✈️】简单安装使用以及各种踩坑-CSDN博客
🍻一、Elasticsearch 基本属性
1.1 ES VS MySQL
在具体使用之前,先了解下和我们常用数据库有哪些相似之处,常用的属性对比如下
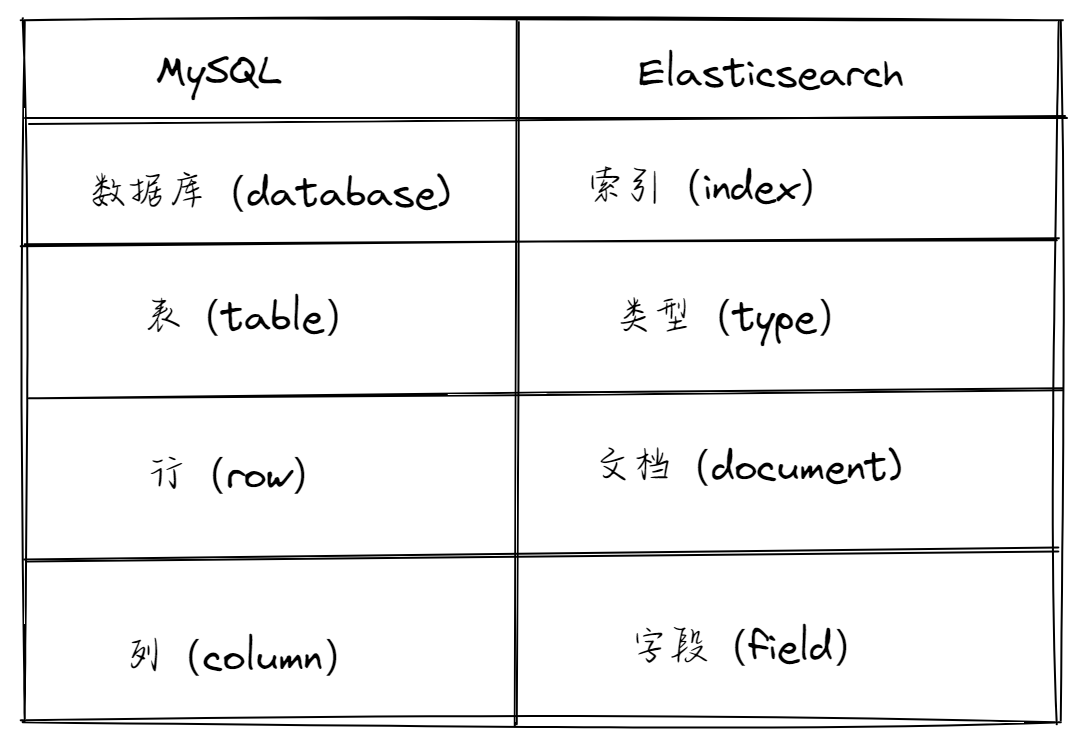
1.2 ES 属性概念
索引(index):
- Elasticsearch中的索引类似于数据库,承担容器的角色。一个索引可以包含多个文档,并且每个文档都有自己的类型和字段。
类型(type):- 在较旧的版本中,类型类似于表,它们定义了索引中文档的结构和字段。在较新的Elasticsearch版本中,通常只有一个默认类型 "_doc"。也就是说一个索引下面建议只有一个类型。
文档(document):- 文档类似于数据库中的行。每个文档都是一个JSON对象,包含了一系列字段和对应的值。
字段(field):- 字段类似于数据库表中的列。每个字段都有一个名称和对应的值,值可以是各种类型的数据,如文本、数字、日期等。
1.3 ES 的增删改查
注:在实操之前,确保之前安装的服务都启动了
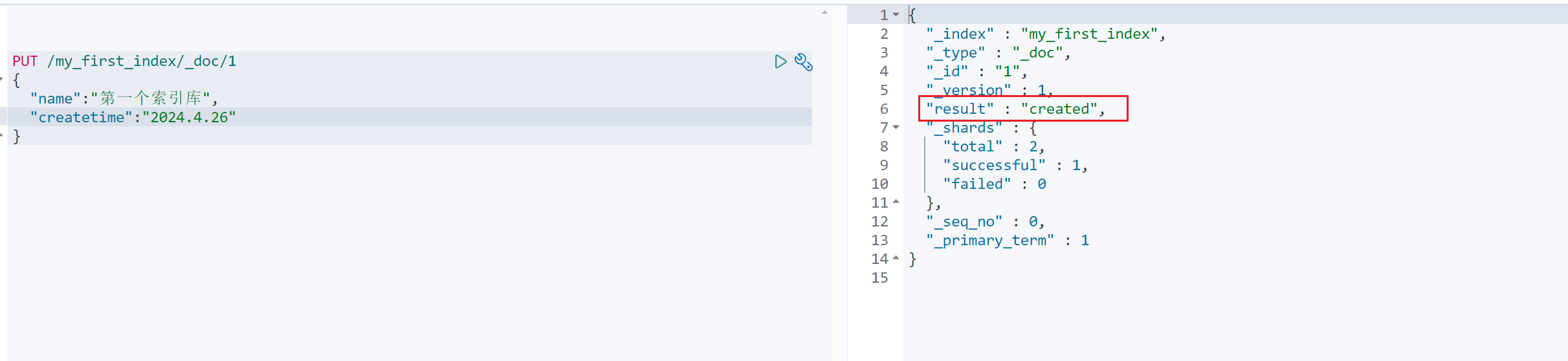
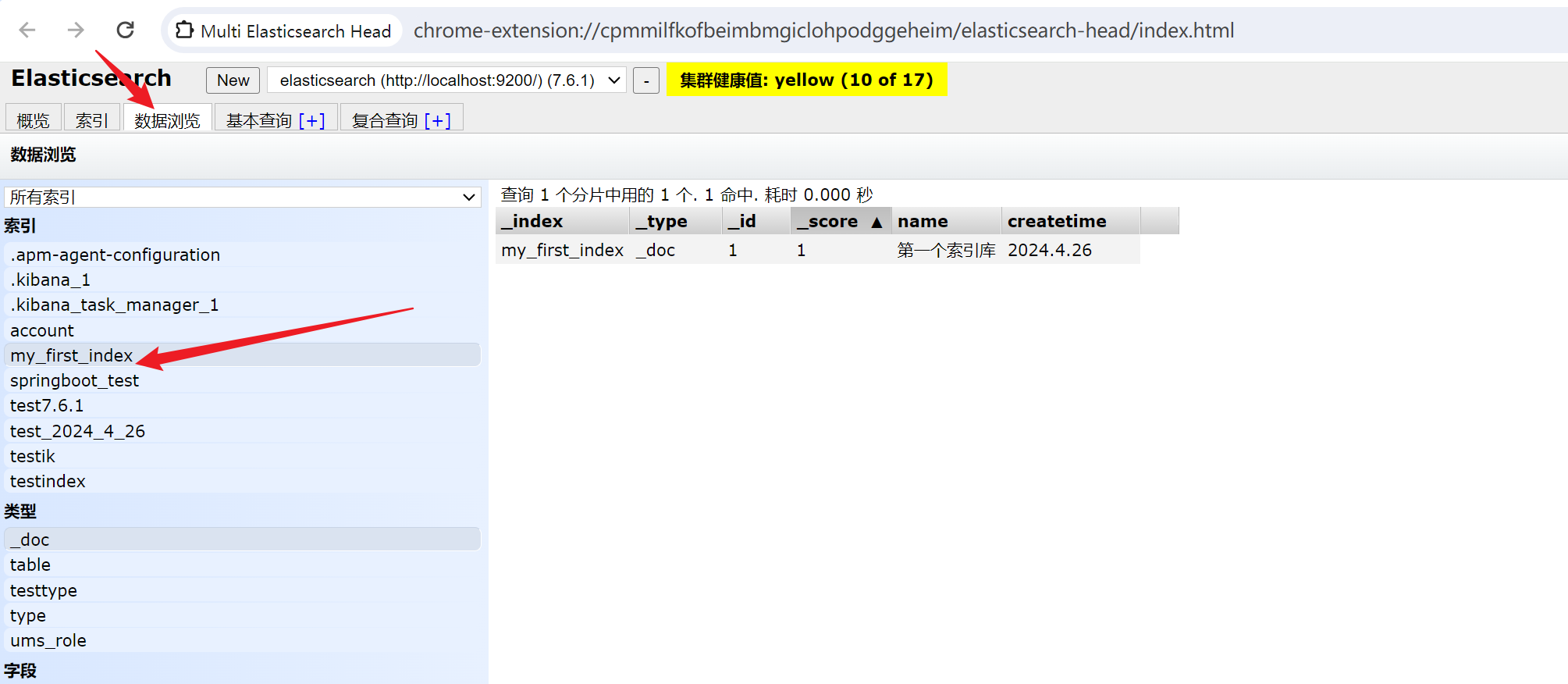
1.3.1 PUT 请求,用于创建或者更新索引,使用如下,创建了一个新的索引,到浏览器插件中也可看到具体的索引库以及库中数据的详细信息
my_first_index 创建的索引名称
_doc 7.x版本默认的_type
1 指定文档的id
{} json 数据格式的内容,类似于<k,v>,一个键对应一个值
PUT /my_first_index/_doc/1
{"name":"第一个索引库","createtime":"2024.4.26"
}
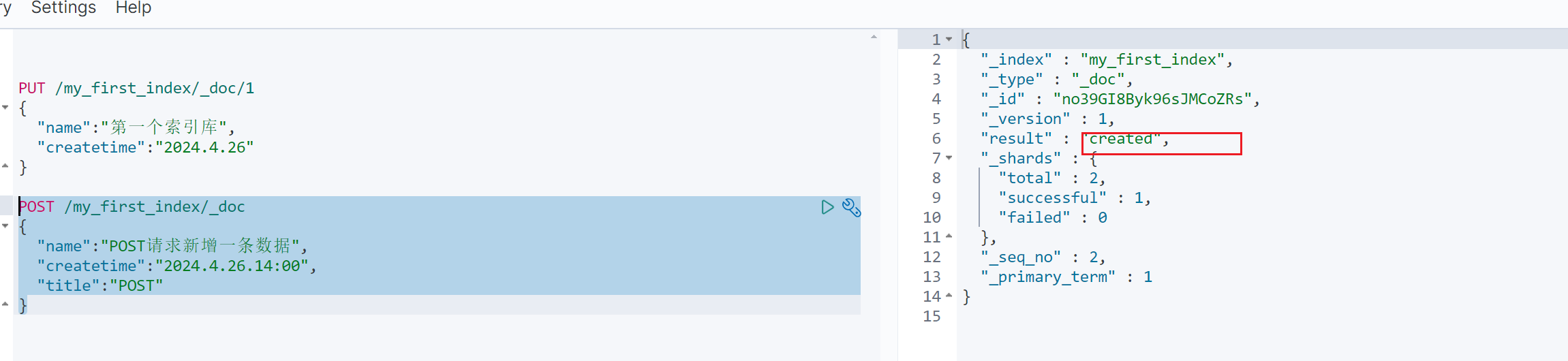
1.3.2 POST 请求, 类似于 PUT 请求,但是可以创建索引的时候不用指定文档 id,会生成一段字符作为默认文档 id,如下:通过插件也可以看到,随机生成的文档 id 是一个随机字符串
注:创建或者修改的时候,索引或者类型命名不能包含大写字母,会报错
POST /my_first_index/_doc
{"name":"POST请求新增一条数据","createtime":"2024.4.26.14:00","title":"POST"
}
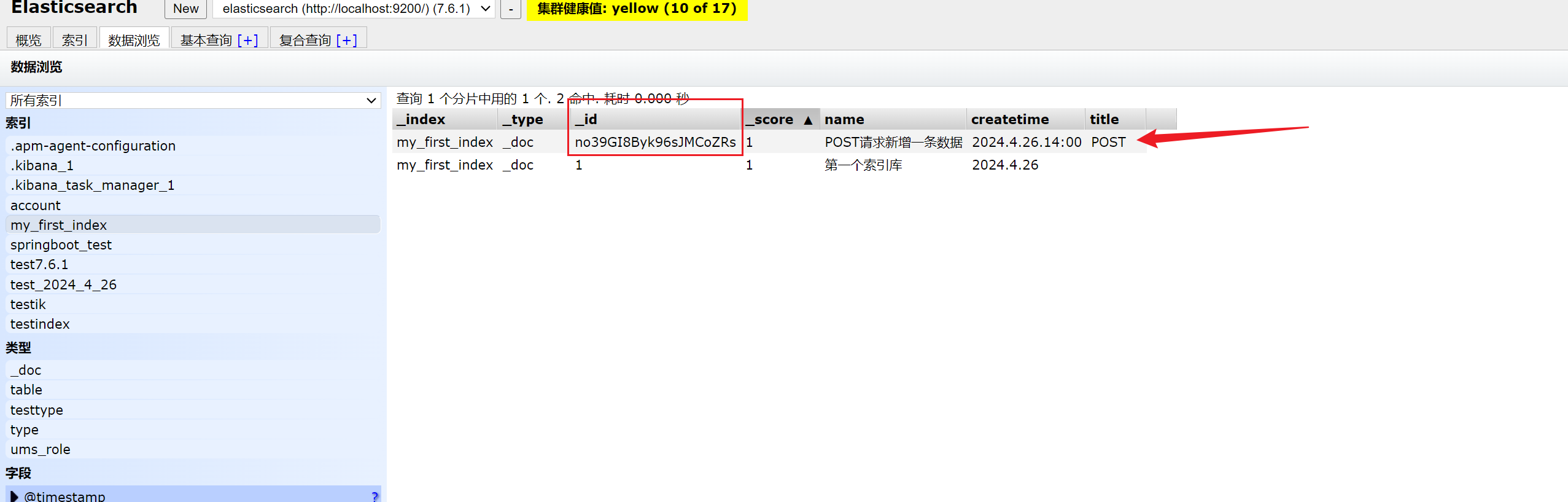
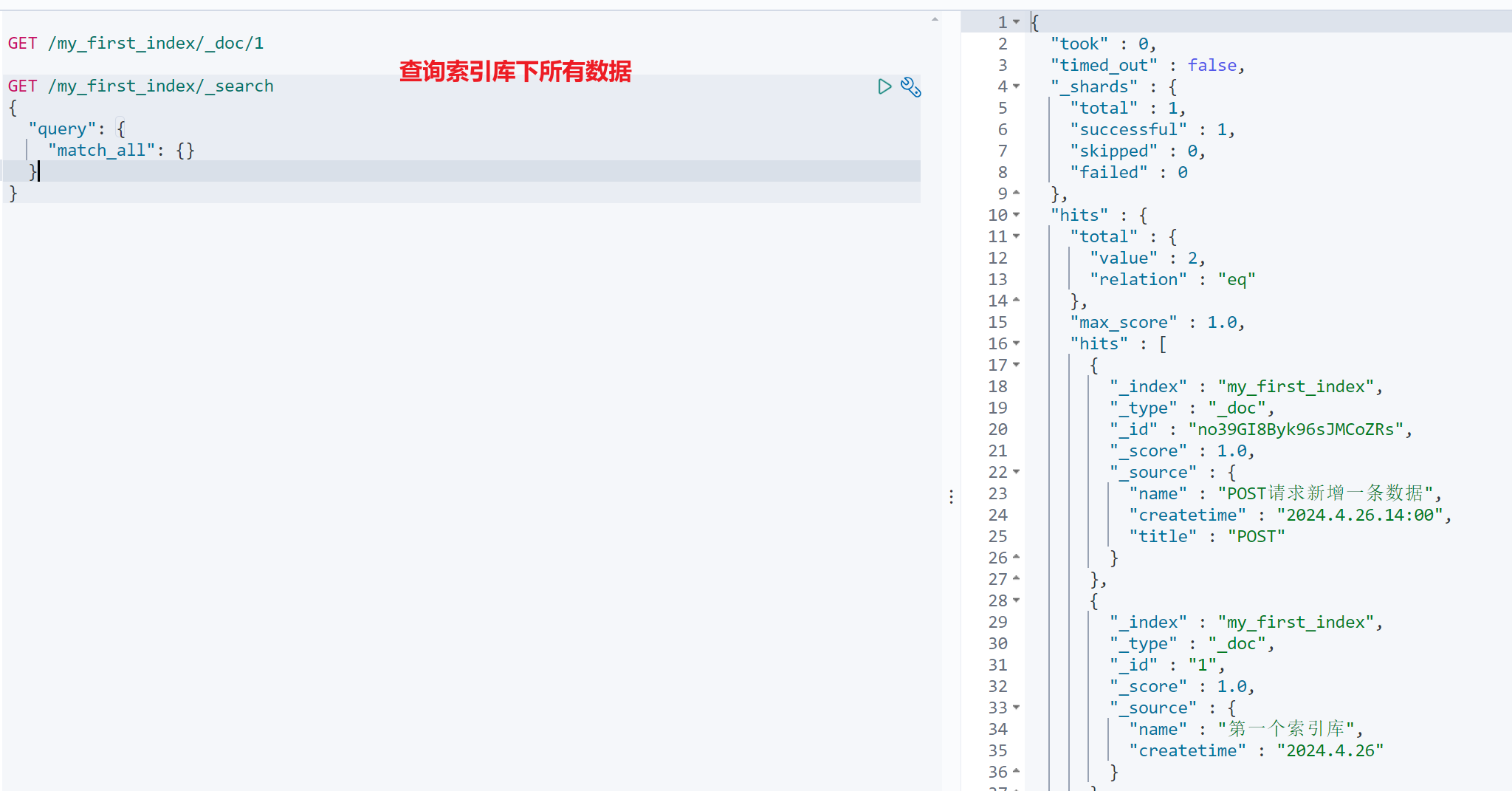
1.3.3 GET 请求,获取索引库数据信息,如下:
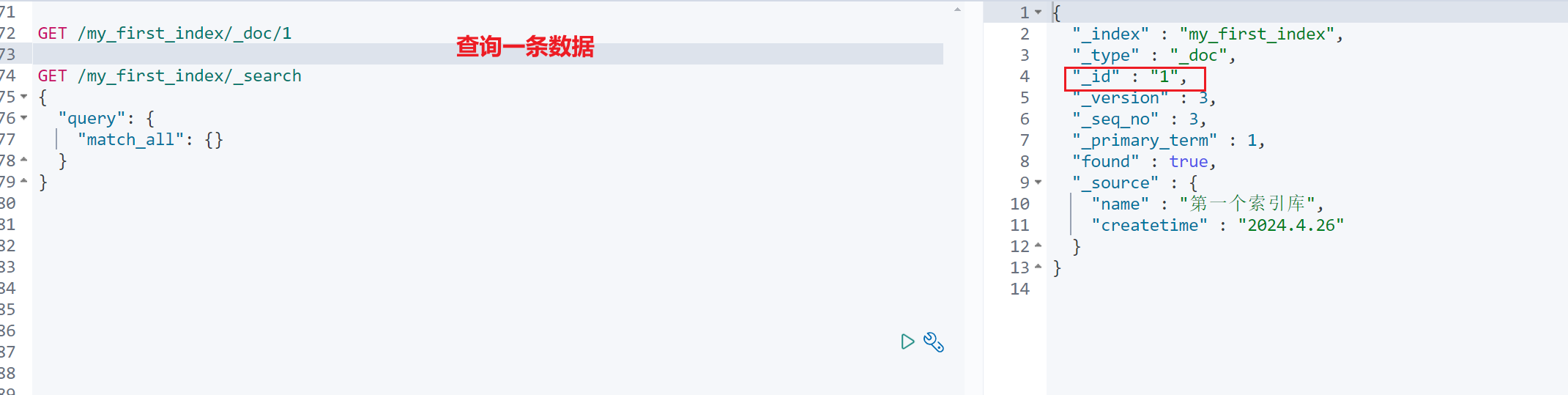
根据文档 id 查询某一条数据
GET /my_first_index/_doc/1查询某个索引库全部数据
GET /my_first_index/_search {"query": {"match_all": {}} }
1.3.4 DELETE 请求 ,需要指定索引名称,如下:

🍺二、自动补全场景
2.1 场景举例
日常接触到的场景有很多,比如购物网站上输入”短袖“,可能会提示有”短袖 重磅“、”短袖 纯色“等等很多,其他很多网站上都可以遇到这种场景,比如经常逛的掘金社区,就以这个为模板,实操下,如下:
 2.2 使用数据分词器
2.2 使用数据分词器
将这些数据录入的时候,指定索引库使用的分词器,本地使用的是 IK 分词器,前提是已经安装好并且没有报错
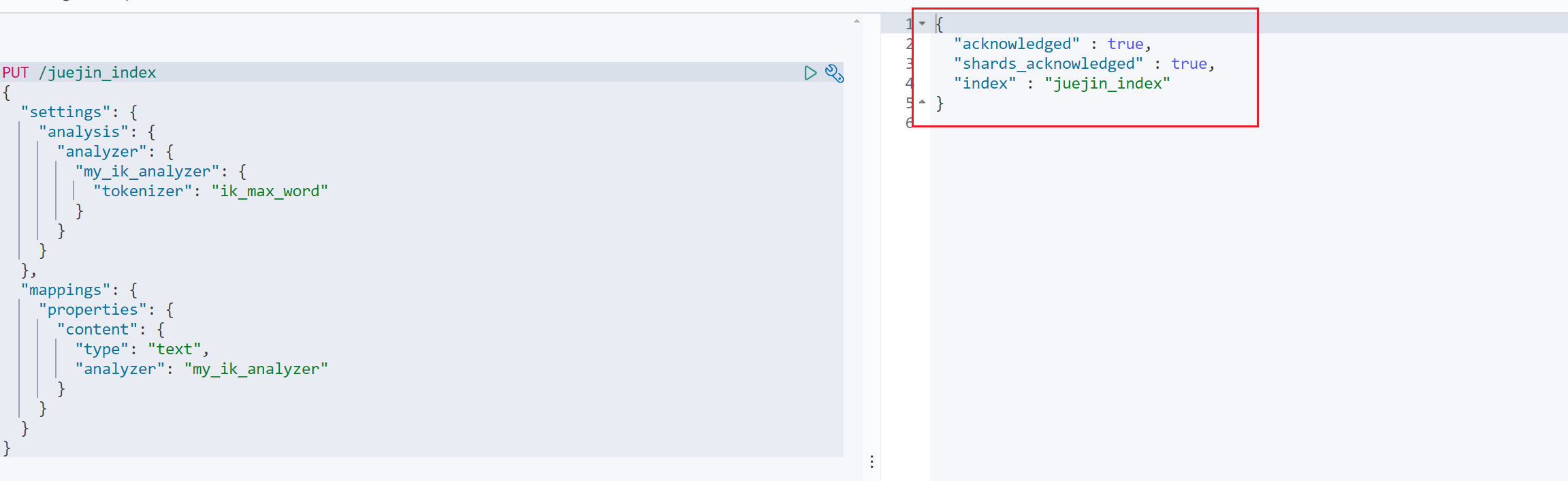
2.2.1 创建索引库,指定分词器
创建索引库的时候,指定该索引库的设置,这里指定的是第一种分词模式
IK 分词器有两种分词颗粒度
ik_max_word对应着 IK 分词器的细粒度模式,它会尽可能地将文本切分成最小的词语单元。ik_smart对应着 IK 分词器的搜索引擎模式,它会根据文本的内容和上下文进行智能分词,提高搜索结果的相关性和效率。
PUT /juejin_index {"settings": {"analysis": {"analyzer": {"my_ik_analyzer": {"tokenizer": "ik_max_word"}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "my_ik_analyzer"}}} }
2.2.2 数据录入
采用批量插入的方式,在最后两个数据中加入了两个扰乱字符串,如下:
POST /_bulk
{"index":{"_index":"juejin_index"}}
{"name":"可视化方案 前端"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化编辑器"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化拖拽软件"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化表单设计"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化大屏前端"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化工作流引擎"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化大屏屏幕适配"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化数学软件"}
{"index":{"_index":"juejin_index"}}
{"name":"可视化大屏特效"}
{"index":{"_index":"juejin_index"}}
{"name":"123可视化"}
{"index":{"_index":"juejin_index"}}
{"name":"可以视为化学武器"}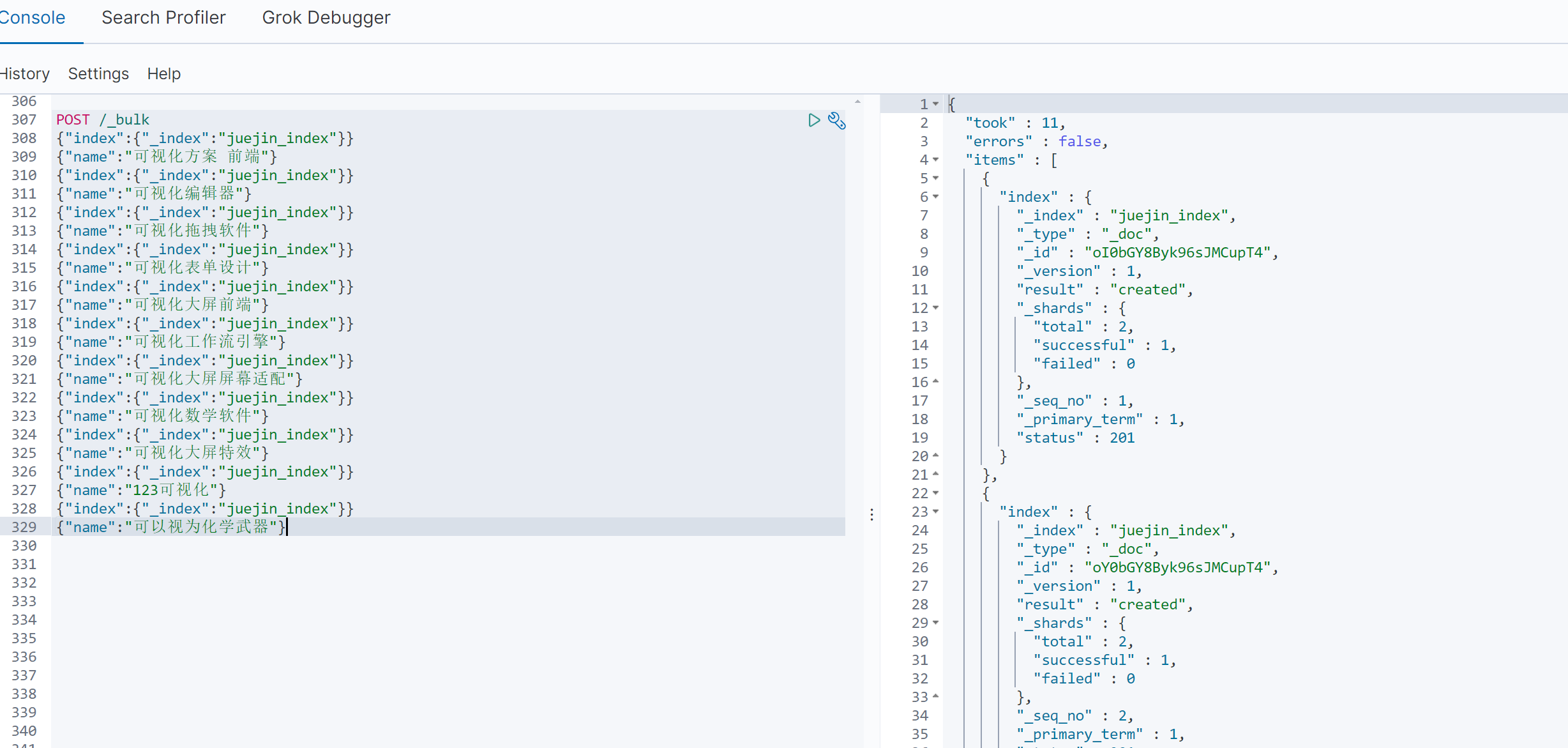
2.2.3 查询测试
查询,”可视化“,相应的会有哪些提示,排名前三如下,排序是根据每个词条的匹配分数值从大到小排列,比如:
”123可视化“ 有 14.6% 的把握
”可视化大屏“ 有 13.2% 的把握
”可视化编辑器“ 有 12.3% 的把握
GET /juejin_index/_search
{"query": {"match": {"name": "可视化"}}
}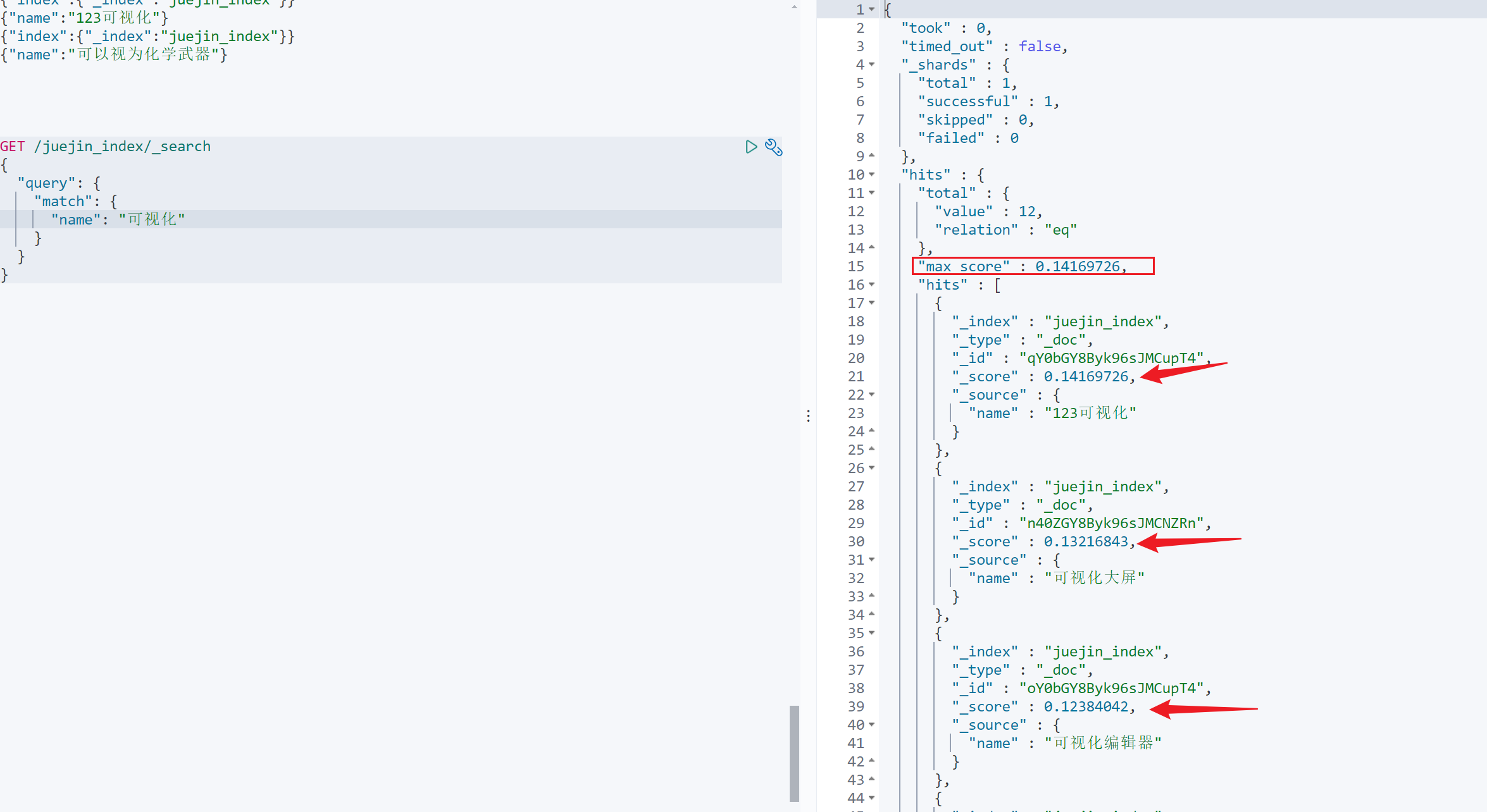
- took: 查询执行的时间,以毫秒为单位。
- timed_out: 表示查询是否超时。
- _shards: 关于索引分片的信息,包括总分片数、成功分片数、跳过的分片数和失败的分片数。
- total: 总分片数。
- successful: 成功的分片数。
- skipped: 被跳过的分片数。
- failed: 失败的分片数。
- hits: 匹配的文档信息。
- total: 匹配的文档总数。
- value: 匹配的文档数。
- relation: 与匹配文档数相关的关系,例如 "eq" 表示相等。
- max_score: 匹配文档中最高的分数。
- hits: 实际匹配的文档数组,每个文档包含以下信息:
- _index: 文档所属的索引。
- _type: 文档类型,在此处为 "_doc"。
- _id: 文档的唯一标识符。
- _score: 文档匹配得分,表示与查询条件的相关性。
- _source: 包含文档原始内容的字段,以及其他自定义字段(如果有)。在这个例子中,"name" 是一个自定义字段,包含了文档的名称信息。
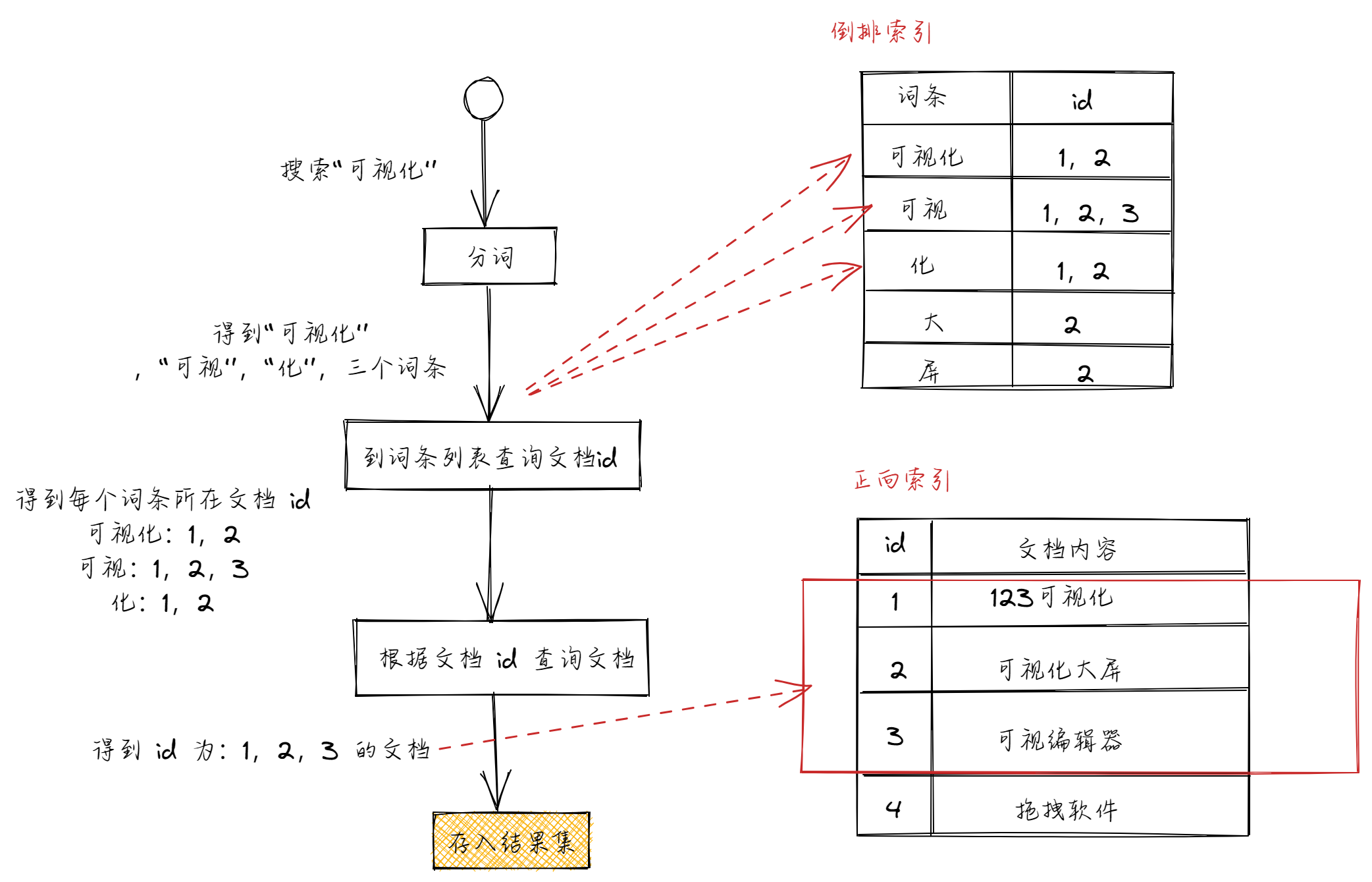
2.3 查询的流程
数据从录入到查询的过程都有哪些
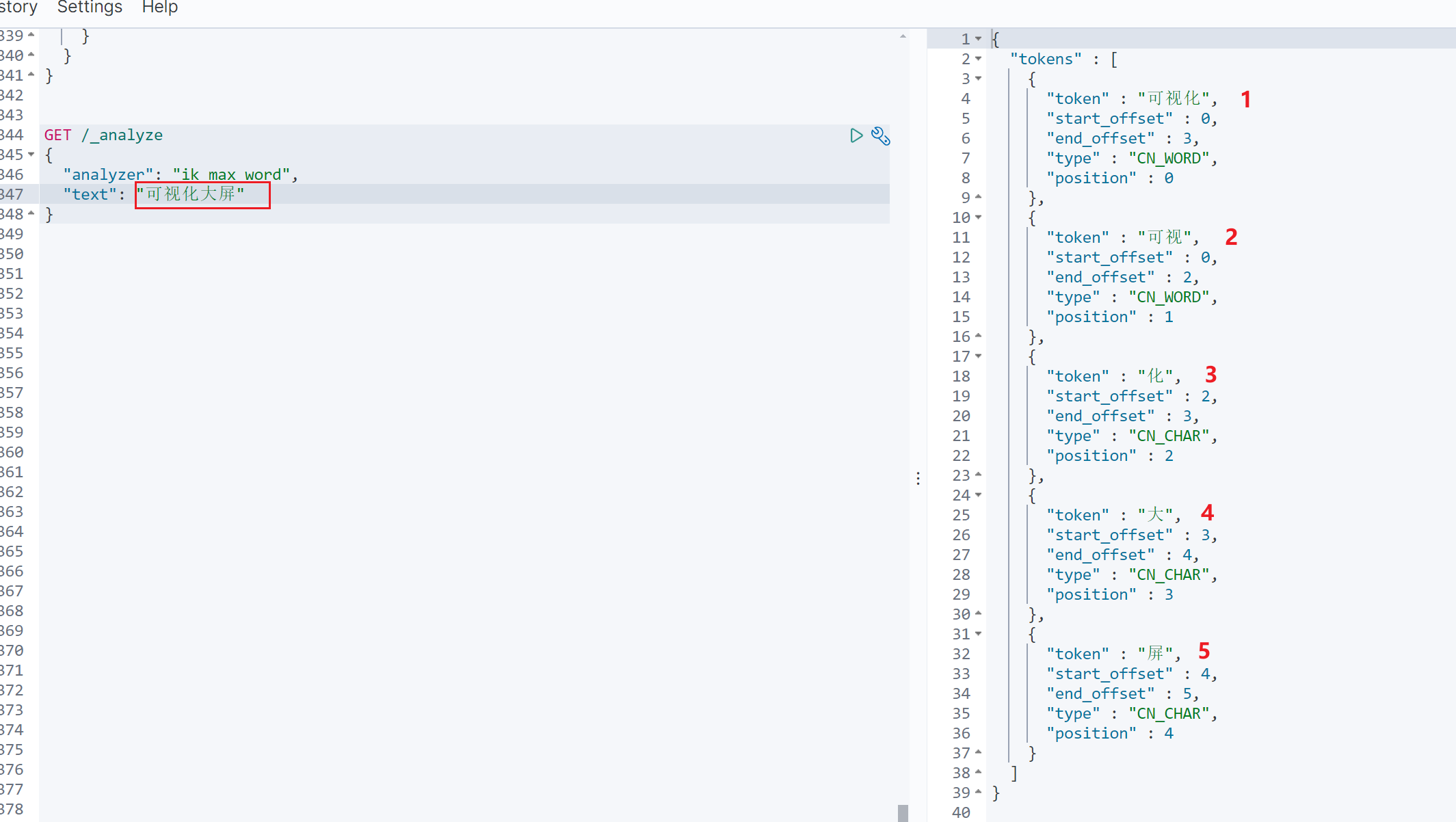
2.3.1 分词录入,这里使用的 IK 分词器,首先会对字符串拆分,如下:
”可视化大屏“ 这个字符串可以拆分为 这几个词条:{”可视化“,”可视“,”化“,”大“,”屏“},然后记录每个词条对应的文档 id,剩余的字符串也都是如此。
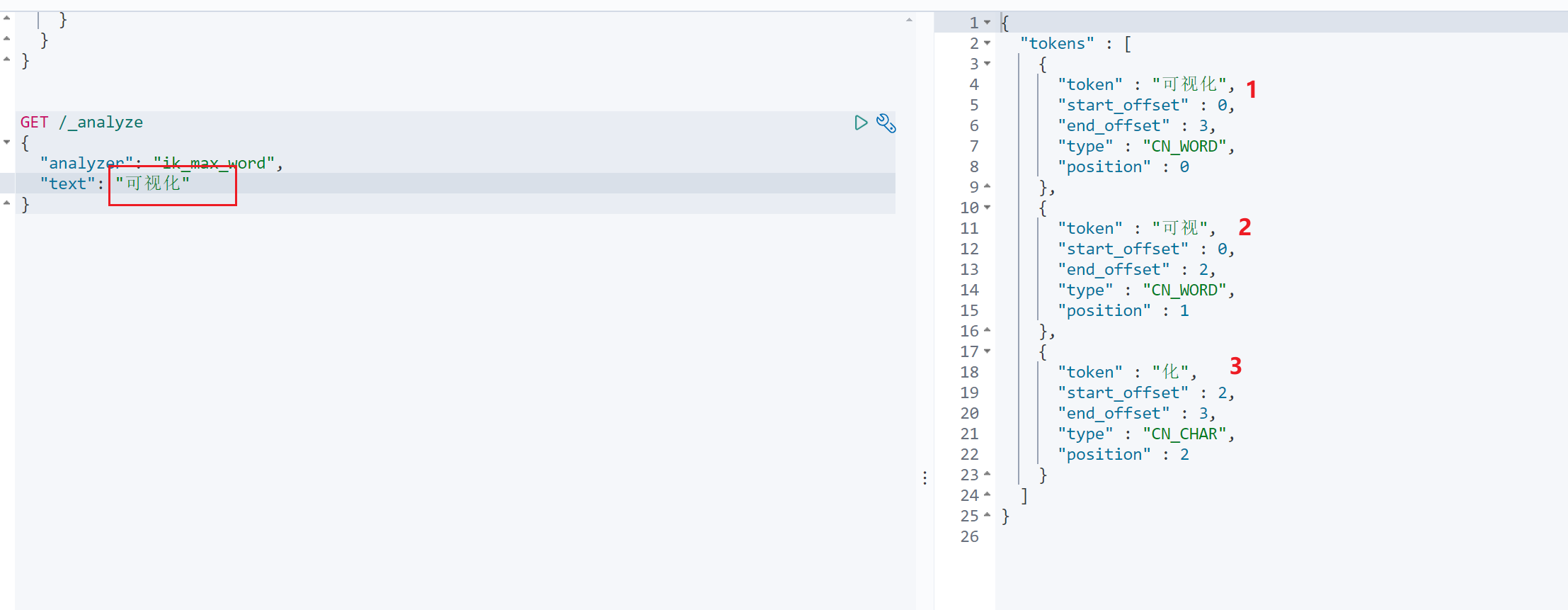
2.3.2 用户输入词汇拆分,IK 分词器会将”可视化“拆分为如下:
”可视化“会拆分为如下词条:{”可视化“,”可视“,”化“},然后根据这些词条到词条列表中查询对应的文档id
2.4 整个查询流程图
从用户输入”可视化“开始,流程大概如下:
🍹章末
文章到这里就结束了~