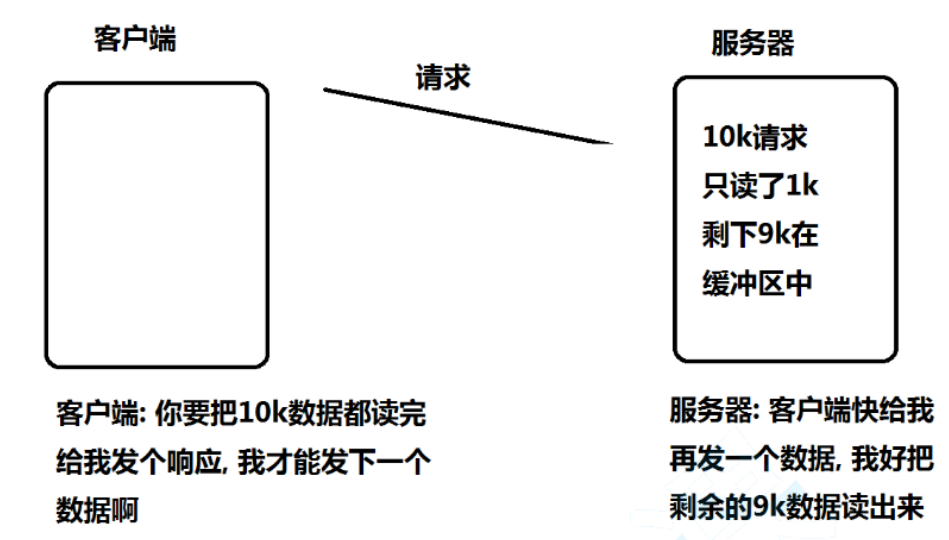
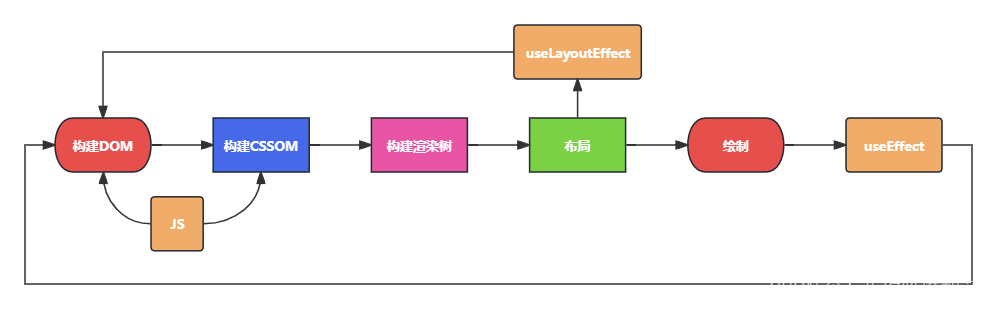
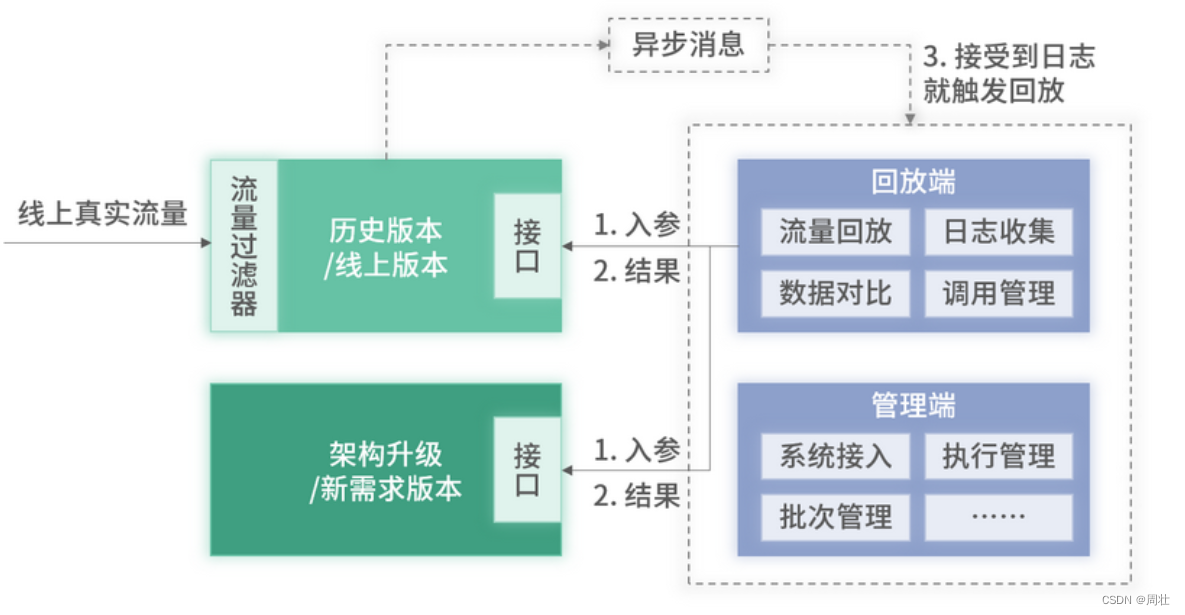
迭代加深搜索(Iterative Deepening Search, IDS)是一种结合了广度优先搜索(BFS)和深度优先搜索(DFS)的搜索策略,它通过重复执行深度限制的深度优先搜索来实现。每次迭代,深度限制增加,直到达到目标节点或搜索空间耗尽。下面是 V 哥的一些理解,分享给大家。
工作原理
- 初始化:设置深度限制为0或1,从根节点开始搜索。
- 深度限制的DFS:执行深度优先搜索,但只搜索到当前的深度限制。如果找到目标节点,则终止搜索。
- 迭代:如果当前深度限制下没有找到目标,则增加深度限制,再次执行深度优先搜索。
- 终止条件:当找到目标节点或搜索空间耗尽时,停止迭代。
特点
- 时间复杂度:IDS的时间复杂度与最优策略(BFS或DFS)相当,但通常比单独的DFS或BFS更优。
- 空间复杂度:与DFS相同,因为它在任何时候只存储一个路径在栈上。
- 完备性:IDS是完备的,如果存在解,它最终会找到它。
- 最优性:与BFS相比,IDS在找到目标节点时使用的节点和边更少,但可能需要更多的时间来处理这些节点。
示例
假设我们有一个简单的树状结构,我们想要找到深度为3的节点。使用IDS,我们会这样操作:
- 设置深度限制为1,执行DFS,不找到目标。
- 增加深度限制到2,再次执行DFS,仍然不找到目标。
- 增加深度限制到3,执行DFS,找到目标节点。
应用
IDS常用于搜索算法中,特别是在解谜游戏(如八数码问题)、人工智能中的路径规划问题,以及任何需要在树或图中找到特定节点的场景。
注意事项
- IDS在实际应用中可能需要根据问题的特性进行调整,以优化性能。
- 在某些情况下,IDS可能不如专门的BFS或DFS有效,尤其是在搜索空间非常大或目标节点非常深的情况下。
迭代加深搜索是一种实用的搜索策略,它结合了BFS和DFS的优点,提供了一种平衡时间和空间复杂度的解决方案。
在Java中实现迭代加深搜索(Iterative Deepening Search, IDS),你可以使用递归方法来执行深度限制的深度优先搜索(Depth-Limited Search, DLS)。以下是一个简单的Java实现示例,它使用了一个简单的树结构来展示如何实现IDS。
类定义
首先,我们定义了一个简单的树节点类TreeNode,用于构建树结构:
class TreeNode {String data; // 节点存储的数据TreeNode left; // 指向左子节点的指针TreeNode right; // 指向右子节点的指针TreeNode(String data) {this.data = data;left = null;right = null;}
}
迭代加深搜索
IterativeDeepeningSearch类中包含了执行IDS的核心方法:
public static void iterativeDeepeningSearch(TreeNode root, String target, int depthLimit) {// 检查根节点是否为空if (root == null) {return;}// 如果深度限制足够大,说明搜索空间没有限制,直接使用深度优先搜索if (depthLimit < Integer.MAX_VALUE) {depthFirstSearch(root, target, 1, depthLimit);} else {// 否则,开始迭代加深搜索int currentDepth = 1; // 当前搜索的深度boolean found = false; // 是否找到目标do {// 执行深度限制的深度优先搜索found = depthFirstSearch(root, target, currentDepth, currentDepth);// 如果当前深度没有找到目标,增加深度限制currentDepth++;} while (!found && currentDepth < Integer.MAX_VALUE); // 直到找到目标或搜索空间耗尽}
}
深度限制的深度优先搜索
depthFirstSearch是一个辅助方法,用于执行带有深度限制的DFS:
private static boolean depthFirstSearch(TreeNode node, String target, int currentDepth, int depthLimit) {// 检查节点是否为空或当前深度是否超出深度限制if (node == null || currentDepth > depthLimit) {return false;}// 如果当前节点包含目标数据,返回trueif (node.data.equals(target)) {return true;}// 否则,递归搜索左子树和右子树// 搜索时,当前深度加1return depthFirstSearch(node.left, target, currentDepth + 1, depthLimit) ||depthFirstSearch(node.right, target, currentDepth + 1, depthLimit);
}
主函数
在main函数中,我们创建了一个树结构,并调用了iterativeDeepeningSearch方法来开始搜索:
public static void main(String[] args) {// 创建树结构TreeNode root = new TreeNode("A");// ... 构建树的其他部分// 定义要搜索的目标String target = "G";// 开始迭代加深搜索,初始深度限制为1iterativeDeepeningSearch(root, target, 1);// 如果搜索过程中找到了目标,打印消息if (depthFirstSearch(root, target, 1, Integer.MAX_VALUE)) {System.out.println("Target found!");} else {System.out.println("Target not found.");}
}
在main函数的最后,我们调用了depthFirstSearch方法,这次没有深度限制,来最终确认目标是否被找到。这是因为在实际的IDS实现中,一旦确定了目标所在的最小深度,就可以无限制地搜索以找到目标。
注意
- depthLimit参数在iterativeDeepeningSearch方法中用于控制搜索的深度。如果这个值设置为Integer.MAX_VALUE,则表示没有深度限制,搜索将退化为普通的深度优先搜索。
- currentDepth参数在depthFirstSearch方法中用于跟踪当前的递归深度,确保搜索不会超出设定的深度限制。
- found变量用于标记是否找到目标节点,如果找到,则终止搜索。
这个实现展示了IDS的基本思想,即通过逐渐增加深度限制来重复执行深度优先搜索,直到找到目标节点或搜索整个树。