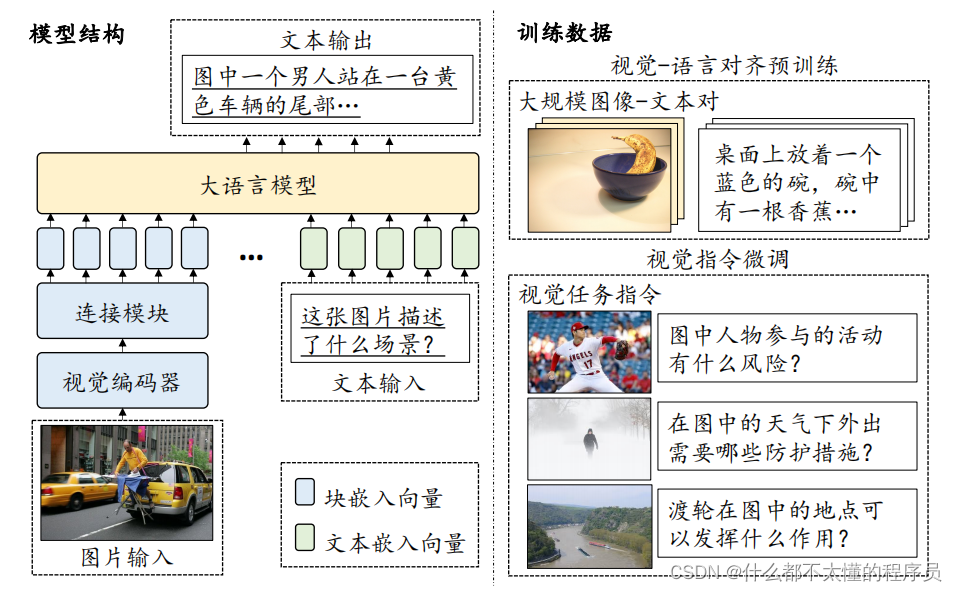
多模态大语言模型(Multimodal Large Language Model, MLLM)主要是指那些能够处理和整合多种模态信息(比如文本、图像和音频)的大语言模型。本节内容将以视觉-语言大语言模型为例,对相关技术进行介绍,类似的技术也可扩展到其他模态(如音频-语言)。多模态大语言模型的模型结构和训练数据如下图所示。通常来说,多模态大语言模型主要由一个用于图像编码的视觉编码器和一个用于文本生成的大语言模型所组成,进一步这两个模型通过连接模块进行组合,从而将视觉的表示对齐到文本语义空间中。在文本生成的过程中,图像首先被分割成图像块(Patch),然后通过图像编码器和连接模块转换成图像块嵌入,以得到大语言模型可以理解的视觉表示。随后,图像块嵌入和文本嵌入进行拼接并输入到大语言模型中,使大语言模型可以自回归地生成文本回复。下面将讨论多模态大语言模型的训练、评测、代表性模型,以及应用建议与未来方向。
训练过程
多模态大语言模型的训练过程主要包括两个阶段:视觉-语言对齐预训练和视觉指令微调。
视觉-语言对齐预训练
为了训练多模态大语言模型,一般重用已有的视觉编码器和大语言模型。由于视觉模型和语言模型之间存在较大的语义空间差异,因此视觉-语言对齐预训练旨在利用大规模“图像-文本对”(简称图文对)进行端到端训练,进而对齐两种不同的语义空间。为了提高对齐性能,选择合适的训练策略和数据非常重要。下面给出一些经验性的训练策略:
(1)如果图文对数量不足够大(例如少于 1M),通常只更新连接模块;
(2)如果训练数据规模相对较大,且包括高质量文本语料或具有细粒度标注的图像-文本对,可以微调大语言模型以提升性能;
(3)如果图文对的数量非常大(例如 1B 规模),可以进一步微调视觉编码器。以上方案均来源于经验性的实验,在使用中仍需进一步验证确定。
视觉指令微调
在视觉-语言对齐预训练之后,下一阶段需要进行视觉指令微调,旨在提高多模态大语言模型遵循指令和解决任务的能力。一般来说,视觉指令微调的输入包括一张图像和一段任务描述文本,输出是对应的文本回复。为了构造高质量的视觉指令数据,可以将图像自带的描述文本输入给大语言模型(如GPT-4),通过特定的提示(如“根据图像描述生成一段图像相关的对话”)来引导大语言模型自动化地合成视觉指令;或者基于已有的视觉-语言任务数据集,利用特定的问题模板将原有任务数据转化为视觉指令(如“请参考图片回答以下问题并给出详细解释”。
多模态大语言模型的评测
在介绍完多模态大语言模型的构建方法后,下面进一步讨论如何评测多模态大语言模型的多模态能力,将从评测维度、评测范式和评测基准三个方面进行介绍。
评测维度
多模态大语言模型的评测任务主要可以被划分为两类:视觉感知和视觉认知任务。具体来说,视觉感知任务旨在评测模型对于图像内容的基本理解能力,而视觉认知任务要求模型根据图像内容完成相对复杂的推理任务。视觉感知任务常用的评测数据集主要关注于对图像整体特征(如主题、风格等)或图中物体特征(如颜色、数量、位置关系等)的识别和分类。特别地,模型对于图片的感知结果与图片实际内容可能存在差异,这种现象被称为幻象问题,可以进行专门的幻象评测(如使用物品幻象评测基准 POPE)。视觉认知任务主要关注于利用语言模型中的语义知识和图像中的视觉感知信息,进而完成更复杂的视觉相关推理任务。其中,视觉问答(Visual Question Answering, VQA)是被广泛用于评测的认知任务,其通过构造和图片内容相关的推理问题来测试模型性能。问题涉及的内容可以是给出的图片中物体之间的空间位置关系(如“图中的碗是在绿色苹果的右侧吗?”)、常识知识(如“图中的人物应该通过哪种动作才能打开这扇门,推还是拉?”)或场景文字(如“图中车辆的车牌号是多少?”)等。
评测基准
为了更全面地评测多模态大语言模型,学术界发布了多个综合评测基准。这些评测基准整合了已有的多模态数据集,并且增加了借助人类或大语言模型进行标注的评测任务。其中,三个常用的评测基准包括:
(1)MME主要包括了从公开途径获得的图片配上手工收集的自然语言问题,这些问题的答案形式被限定为是或否,用于评测多模态大模型在 14 个视觉感知和认知任务上的表现;
(2)MMBench 基于现有数据集,手工构造了 2,974 条用于评测多模态能力的多项选择题,总共涵盖了 20 类不同的多模态任务;
(3)MM-Vet 首先定义了 6 项基础的多模态能力,之后将这些能力组合为 16 种不同的复杂多模态任务,之后收集了 200 张图片和 218 个文本问题用于评测。
代表性的多模态大语言模型
近年来,学术界和工业界涌现出了多种多模态大语言模型。下面介绍一些具有代表性的多模态大语言模型。
MiniGPT-4
MiniGPT-4 是较为早期的开源多模态大语言模型,主要包括三个组件:CLIP 和 Q-Former 组成的视觉编码器,对齐视觉和语言特征表示的线性层,以及大语言模型 Vicuna。MiniGPT-4 的训练经历两个阶段:首先是视觉-语言对齐的预训练阶段,此阶段主要使用了来自 LAION, SBU 和 Conceptual Captions的大量图文对数据集,针对模型的线性层进行训练,旨在为模型建立初步的跨模态理解能力。进一步,在视觉指令微调阶段,作者收集了 3,500 条高质量的详细图片描述,并将其组织成对话形式进行模型微调,以提高模型的语言流畅度和对话交互能力。这一阶段也仅针对线性层进行训练。
LLaVA
LLaVA 也是早期的开源多模态大语言模型之一,其模型结构与 MiniGPT-4 类似,但视觉编码器部分仅由 CLIP 组成。LLaVA 在视觉-语言对齐预训练阶段,从 CC3M 中收集了 595K 图文对数据来训练线性层;在视觉指令微调阶段利用 ChatGPT 改写了 COCO 数据集中的图文对,创建了 158K 条复杂视觉指令数据,涵盖了图像描述、看图对话和视觉推理等类型的任务,然后使用这些数据同时训练大语言模型和线性层。LLaVA 后续还推出了 LLaVA-1.5 和 LLaVA-Plus等加强版本。其中,LLaVA-1.5 增加了视觉-语言表示对齐的线性层的参数,并在训练数据中加入了更多任务相关数据(如知识问答和场景文字识别)以进一步提升模型能力。
GPT-4V
OpenAI 在 2023 年 3 月的技术报告中首次介绍了 GPT-4V 的多模态能力,针对照片、截图、图表等多种图片形式,GPT-4V 均能有效回答与其相关的自然语言问题。2023 年 9 月,OpenAI 正式发布了 GPT-4V 的系统概述,重点介绍了其在安全性对齐方面的进展,能够有效避免有害内容的输出。2023年11月6日,OpenAI 向公众开放了 GPT-4V 的 API 接口。已有评测工作表明,GPT-4V 不仅在文本任务上领先此前的模型,在传统 VQA 任务(例如 OK-VQA)以及针对多模态大模型的复杂评测基准(如 MMMU)上的表现也都处于领先水平。
Gemini
2023 年12月14日,谷歌推出了 Gemini 系列大模型,其中发布了多模态模型 Gemini Pro Vision 的 API。技术报告中提到,Gemini 采用的是纯解码器架构,能够处理文本、音频和视觉模态的输入,并能生成文本或图像的输出。它的训练数据涵盖了从网页、书籍、代码到图像、音频和视频等多样的数据来源。在各种评测基准上的测试结果表明,Gemini 不仅在文本生成和理解方面表现出色,还能够完成视频理解、音频识别等其他模态任务。
总结
基于以上讨论,我们对多模态大语言模型给出了以下应用建议和未来方向。
应用建议
现有的评测结果表明,闭源模型(如 GPT-4V、Gemini 等)的通用多模态数据处理能力普遍优于开源的多模态大语言模型。然而,闭源模型不利于进行端到端或者增量式的应用开发。因此,对于特定的多模态任务场景,如果能够针对性地构造高质量多模态指令数据并对开源模型进行训练,也是一个重要的技术路线。此外,由于真实应用场景较为复杂,直接利用多模态大语言模型可能并不能有效应对所有复杂案例,还可以考虑让多模态大模型学习使用其他工具(如图像分割模型等),从而加强多模态模型的任务效果。
未来方向
尽管目前的多模态大语言模型已经初步具备了基于视觉信息进行推理的能力,但是其在复杂多模态应用场景下的效果仍然非常受限,如基于多图的复杂逻辑推理问题、细粒度的语义理解问题等。为了加强多模态模型的复杂推理能力,可以构造覆盖场景更广且更加复杂的视觉指令集合以强化模型本身的视觉推理能力,而更为本质的问题是去思考多模态大模型的建立方法与学习机制。例如,Gemini 从头对于多模态数据进行混合预训练,而不是将多模态组件直接向大语言模型进行对齐。此外,多模态大语言模型可能输出虚假或有害的信息(如物体幻象),这会对于模型的安全性造成很大影响。针对这一问题,既需要在模型
层面分析幻象的导致原因(如图片侧防御能力较弱等),也可以通过收集类似红队攻击或幻象识别的视觉指令,用来微调多模态大语言模型以增强其健壮性。


![[leetcode] 58. 最后一个单词的长度](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)