LLaMA3 8B版本的表现已经能和GPT-4还有Claude3这些大佬一较高下了!想象一下70B版本得有多牛,是不是得飞上天和太阳肩并肩了?
不过,原版的LLaMA3主要是用英文世界的语料喂大的,虽然它对中文也能点头哈腰,但因为中文语料不够丰盛,所以用中文和它聊天时,它的表现就像是个刚学中文的老外,还有点懵。
现在社区里出现了好些用中文语料二次训练的LLaMA3项目,数量多得跟星星似的。这种开源社区的热情固然让人热血沸腾,但我这心里啊,就像吃了颗没熟的葡萄,有点酸溜溜的。
首先,我得打个问号,这一波Chinese-LLaMA3的训练热潮,是不是有点炒作的嫌疑?大家争先恐后地想要坐上中文版的头把交椅,但这训练质量、语料的靠谱程度、安全性啥的,真的能让人放心吗?再说了,中文语料和英文语料在知识层面是不是能无缝对接,基于训练团队的语料质量,最终的成果能否在中文上和英文一样溜?
我还有个疑问,如果LLaMA3的能力可以用分数来衡量,那是不是意味着任何团队做的中文训练,最后都得给个相同的分数?最后,我们真的非得要个中文版的LLaMA3吗?用非中文版的难道就不能满足我们的需求了?中文训练后的模型,还能不能和原版的保持同样的默契?
就我个人而言,我觉得吧,现在已经是2024年了,我们可能真的不需要一个Chinese-LLaMA3。我之前看过一篇文章,研究团队发现,用中文语料训练的模型在中文交互下的表现,还不如把中文prompt翻译成英文后再给LLaMA3来得效果好。
从感性的角度来看,这种情况也不难理解。中文世界的语料,无论是数量还是质量,都还比不上英文世界的语料。而且,中文语料训练出的结果,并不能像人脑那样,和英文语料训练出的结果直接画上等号。
那我们能不能通过优化应用架构,来达到更好的效果呢?其实,我们只需要一个中文语境下的大模型作为中间的Agent,让两个大模型手拉手,一起实现我们的目标。
在适当的开发工具中(类似各种agnent,比如coze,longchain),我们只需要搭建一个简单的workflow,里面包含三个过程节点:先把中文翻译成英文,再传给LLaMA3,最后把结果从英文翻译回中文。
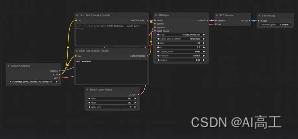
这个workflow里有两个LLM,其中LLaMA3是目标模型,我们还需要一个在中英翻译方面特别强悍的大模型作为中介。根据当前的业务场景,它能提供system prompt,翻译出行业的专业术语。
在用户端,后台架构的这些变化对前端用户来说几乎是透明的,用户该怎么聊天还是怎么聊天,一点感觉都没有。但在结果的表现上,却能享受到LLaMA3的加持,变得更聪明。
基于同样的道理,将来如果出现了更强大的大模型,我们只需要替换workflow中的节点,而无需在应用后台做大规模的调整和开发。这样一来,我们就能像换衣服一样轻松地跟上时代的步伐了!