在MapReduce中,排序的目的是为了方便Reduce阶段的处理,通常是为了将相同键的键值对聚合在一起,以便进行聚合操作或其他处理。
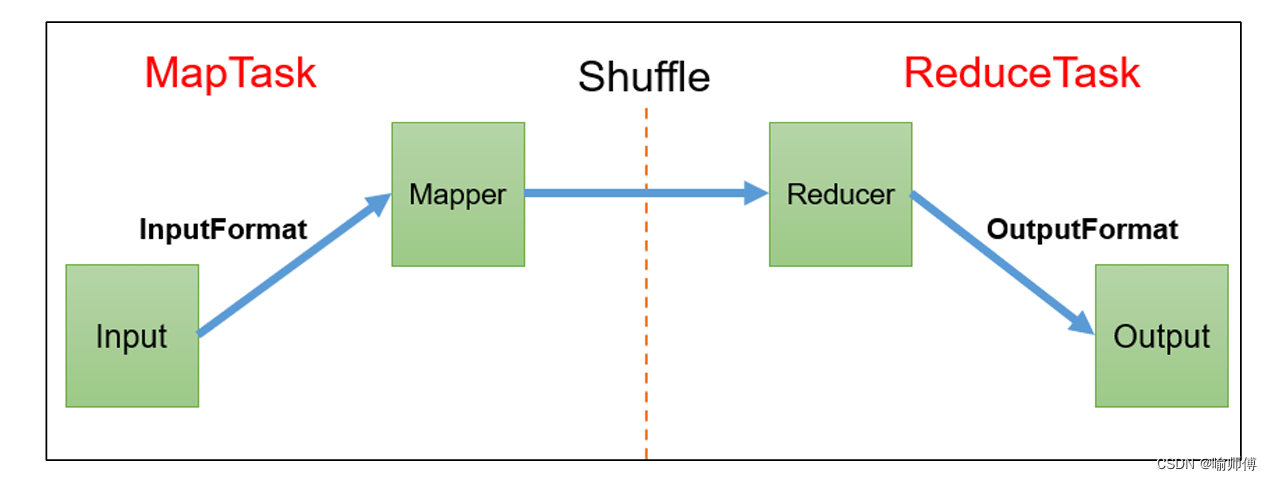
1. Map阶段的局部排序(Local Sorting):
-
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使
用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数
据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。 -
在Map阶段,通常会对
Mapper输出的键值对进行局部排序,以便后续的合并或传递给Reducer。 -
这个排序过程在每个Mapper任务内部进行,不涉及跨节点的通信。
-
一般来说,局部排序可以使用内部排序算法,比如快速排序(Quicksort)、归并排序(Mergesort)或堆排序(Heapsort)等。这些算法在排序小规模数据时都有很好的性能表现。
-
这种排序是为了将相同键的键值对聚集在一起,以便后续的合并操作或者直接传递给Reducer进行处理。
-
通常情况下,Map阶段的输出会根据键进行排序,但
并不要求所有Mapper输出的数据都需要进行全局排序。
2.Combiner阶段的局部合并(Local Merging):

-
在Map阶段输出数据到Reduce之前,可能会使用Combiner对Mapper输出的中间结果进行局部合并。
-
这个合并过程可以减少数据传输和提高效率,通常也会涉及排序以便合并相同键的键值对。
-
类似于Map阶段局部排序,可以使用内部排序算法来实现。
- 示例:


3. Shuffle和Sort阶段:
-
MapReduce框架将Mapper输出的键值对根据键进行分区(
Partition)。
mapreduce分区机制 -
每个分区的数据将被发送到相应的Reducer节点。
-
在
传输过程中,框架会对数据进行排序(Sort),以确保每个Reducer节点接收到的数据是有序的。 -
通常使用稳定的排序算法,如
归并排序,以确保相同键的键值对在排序后仍然保持相对顺序。 -
这个排序过程可以是基于键的排序,保证Reduce阶段处理的数据是按照键的顺序排列的。
4. Reduce阶段:
-
在
Shuffle和Sort阶段,数据会在传输过程中进行排序,以确保每个Reducer接收到的数据是按照键的顺序排列的。 -
因此,在
Reduce阶段,数据已经是有序的,Reduce任务只需要按照接收到的键值对的顺序进行处理即可,无需再进行额外的排序操作。 -
Reduce任务接收到来自各个Mapper的分区数据。 -
Reduce任务按照接收到的键值对的顺序进行处理,从而保证输出也是有序的。
5.排序的实现方式:
MapReduce框架通常会提供默认的排序机制,但也允许用户根据具体需求进行定制化。一般来说,排序机制的实现主要依赖于以下两个方面:
a. 键的比较器(Key Comparator):
键的比较器用于确定两个键的顺序关系,从而实现排序。通常情况下,MapReduce框架会要求用户实现一个自定义的比较器,用于比较键的大小关系。用户可以根据键的类型和排序需求来编写自定义的比较器。
b. 分区函数(Partitioning Function):
分区函数决定了键值对如何被分配到不同的Reduce任务中。
在排序过程中,分区函数会根据键的大小将键值对划分到不同的分区中,从而保证在Reduce阶段每个Reduce任务都能处理一组有序的键值对。
7.WritableComparable 排序
WritableComparable 排序是指在 Hadoop 中对自定义数据类型进行排序。在 Hadoop MapReduce 中,键值对是主要的数据单元,当 MapReduce 作业执行过程中需要排序时,通常是根据键进行排序。而要对键进行排序,键的类型必须实现 WritableComparable 接口。
WritableComparable 接口
WritableComparable 接口是 Hadoop 中的一个接口,它继承自 Writable 接口,并添加了 Comparable 接口的功能。它定义了两个方法:
write(DataOutput out):将对象的字段按照指定的顺序写入DataOutput流中,以便序列化。compareTo(T o):比较当前对象与指定对象的顺序。返回值为负数表示当前对象在指定对象之前,返回值为零表示两个对象相等,返回值为正数表示当前对象在指定对象之后。
通过实现 WritableComparable 接口,可以指定如何比较自定义数据类型的对象,并且在 Hadoop MapReduce 作业中进行排序。
示例
假设有一个自定义的键类型 CustomKey,其中包含两个字段 value1 和 value2,需要根据 value1 字段进行排序。为了实现这个排序功能,需要按照以下步骤进行:
CustomKey类实现WritableComparable<CustomKey>接口,并重写其中的方法write和compareTo。- 在
compareTo方法中,指定按照value1字段进行排序的逻辑。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;public class CustomKey implements WritableComparable<CustomKey> {private int value1;private int value2;// 省略构造函数和其他方法@Overridepublic void write(DataOutput out) throws IOException {out.writeInt(value1);out.writeInt(value2);}@Overridepublic void readFields(DataInput in) throws IOException {value1 = in.readInt();value2 = in.readInt();}@Overridepublic int compareTo(CustomKey o) {// 按照 value1 字段进行比较if (this.value1 < o.value1) {return -1;} else if (this.value1 > o.value1) {return 1;} else {// 如果 value1 相等,则按照 value2 字段进行比较return Integer.compare(this.value2, o.value2);}}
}
通过实现 WritableComparable 接口并重写 compareTo 方法,可以指定在 Hadoop MapReduce 作业中对 CustomKey 对象进行排序的逻辑。然后,将 CustomKey 类用作 MapReduce 作业的输出键类型,作业执行过程中就会根据指定的排序逻辑对键进行排序。
6.示例
假设我们有一个文本文件,其中包含一些单词及其出现的次数。我们希望使用MapReduce来对这些单词按照字母顺序进行排序,并统计每个单词出现的总次数。
1. Map阶段:
假设我们有以下输入数据:
apple 1
banana 2
apple 3
banana 1
cat 2
在Map阶段,我们的Mapper任务将处理这些数据,并生成中间键值对。每个键值对的键是单词,值是该单词出现的次数。
Mapper的输出可能如下所示(假设我们有两个Mapper任务):
Mapper 1输出:
apple 1
banana 2
Mapper 2输出:
apple 3
banana 1
cat 2
每个Mapper输出的键值对按照键进行局部排序。
2. Combiner阶段:
在本地,Combiner会对Mapper输出的中间结果进行合并,以减少数据传输量。假设Combiner合并后的结果如下:
apple 4
banana 3
cat 2
Combiner合并了相同键的键值对,并将它们的值相加。
3. Shuffle和Sort阶段:
MapReduce框架将Combiner输出的键值对根据键进行分区,并在传输过程中进行排序。假设我们有两个Reducer节点,并且我们使用哈希分区函数将键值对分配到Reducer节点。
Reducer 1接收到的分区数据:
apple 4
banana 3
Reducer 2接收到的分区数据:
cat 2
在传输过程中,数据已经根据键进行了排序。
4. Reduce阶段:
每个Reducer按照接收到的键值对的顺序进行处理。假设我们的Reduce函数只是简单地将每个单词的总次数进行累加。
Reducer 1输出:
apple 4
banana 3
Reducer 2输出:
cat 2
每个Reducer的输出都是按照键的顺序排列的。
这就是一个简单的MapReduce排序机制的示例。在这个过程中,数据在Map阶段进行了局部排序,然后在Shuffle和Sort阶段进行了全局排序,最终在Reduce阶段输出了有序的结果。
总结:
排序是MapReduce中非常重要的一个环节,它决定了在Reduce阶段如何对键值对进行处理。通过合适的排序机制,可以确保Reduce任务能够高效地处理数据,并且保证处理结果的正确性。