目录
一、前提准备工作
hadoop%E9%9B%86%E7%BE%A4-toc" style="margin-left:120px;">启动hadoop集群
二、实验过程
1.虚拟机安装先设置端口转发
2.上传对应文件
3.编写Java应用程序
4. 编译打包程序
5. 运行程序
三、算法设计和分析
算法设计
算法分析
四、实验总结
实验目的:给定一份英文文本,统计每个字符在文本中出现的频率
完成时间:2024-4-22
一、前提准备工作
hadoop%E9%9B%86%E7%BE%A4">启动hadoop集群
第一步:首先登陆ssh,之前设置了无密码登陆,因此这里不需要密码;再切换目录至/usr/local/hadoop ;再启动hadoop,如果已经启动hadoop请跳过此步骤。命令如下:
ssh localhost
cd /usr/local/hadoop
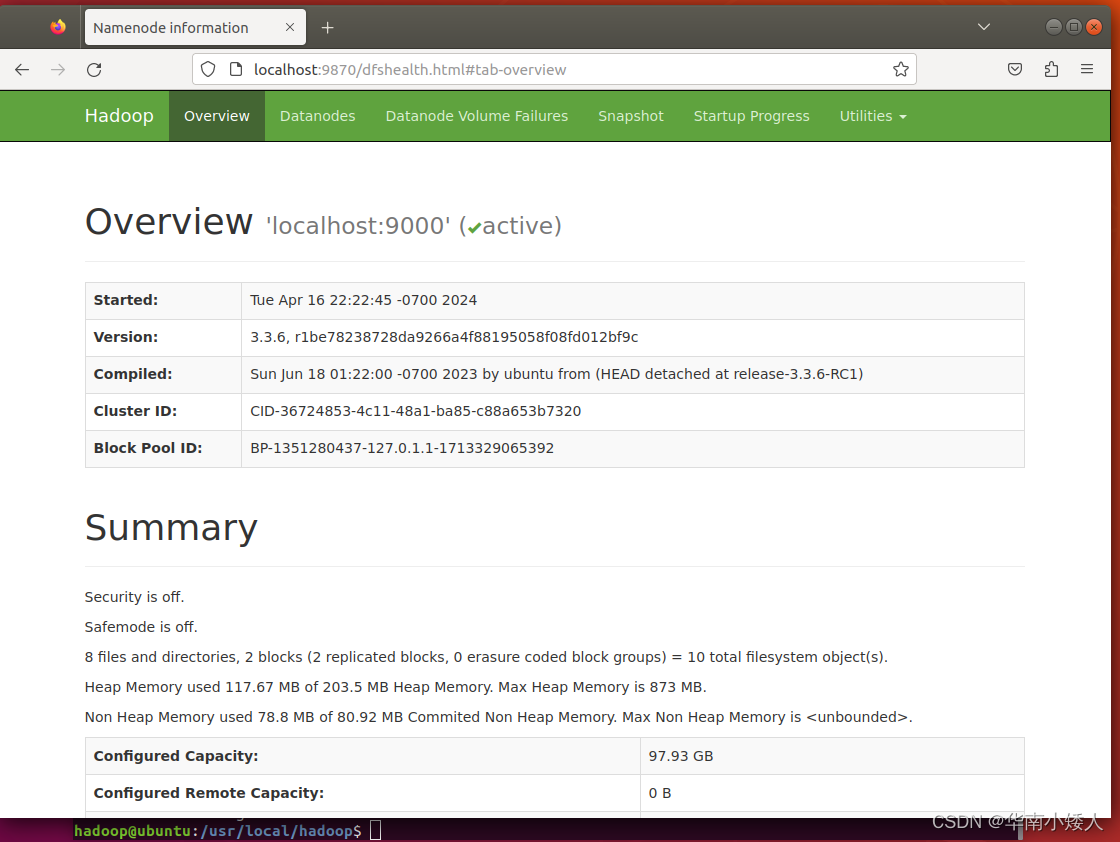
./sbin/start-dfs.sh启动成功,输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示hadoop启动成功,截图如下:

访问web界面
二、实验过程
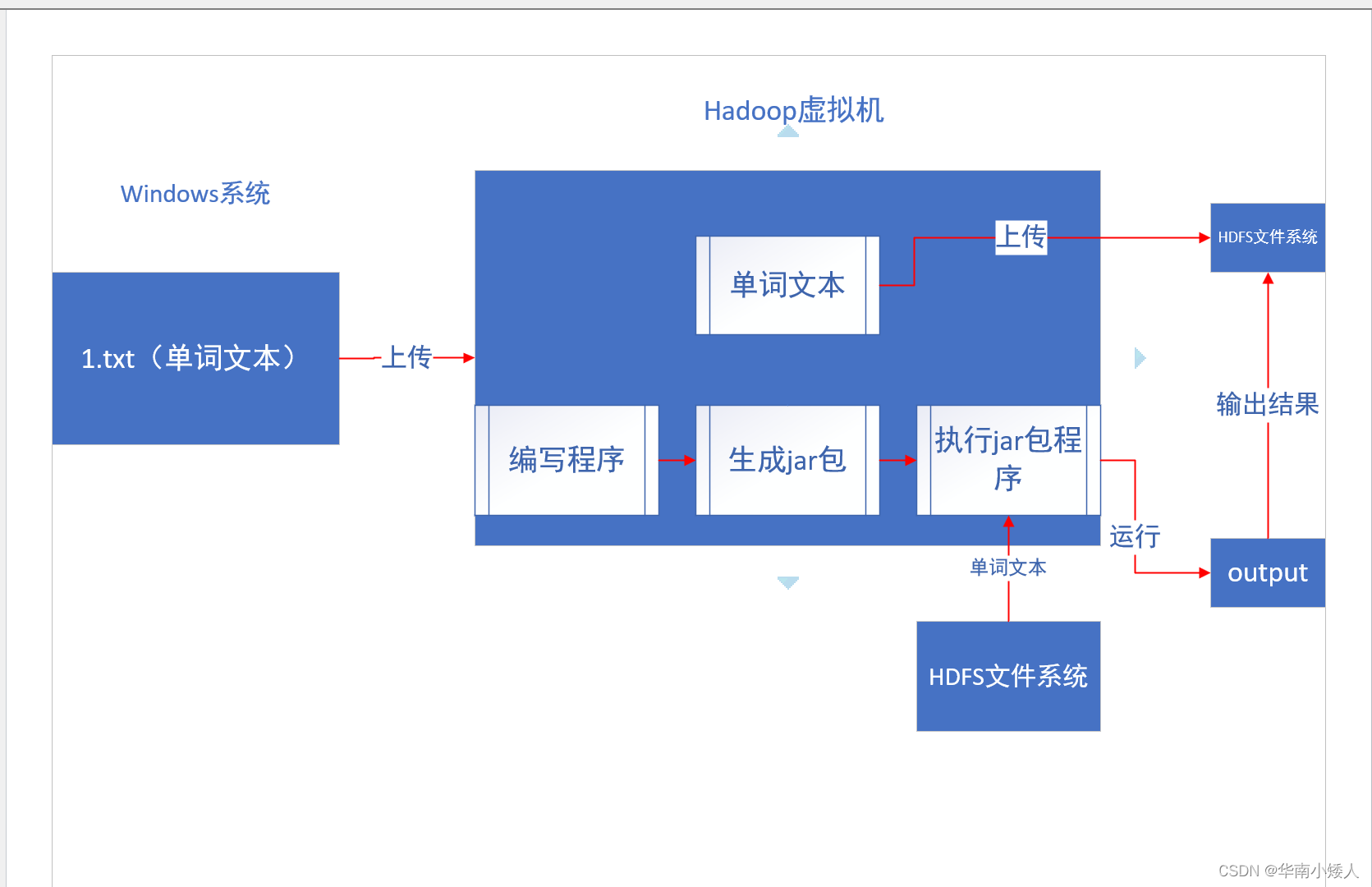
实验流程图:
1.虚拟机安装先设置端口转发
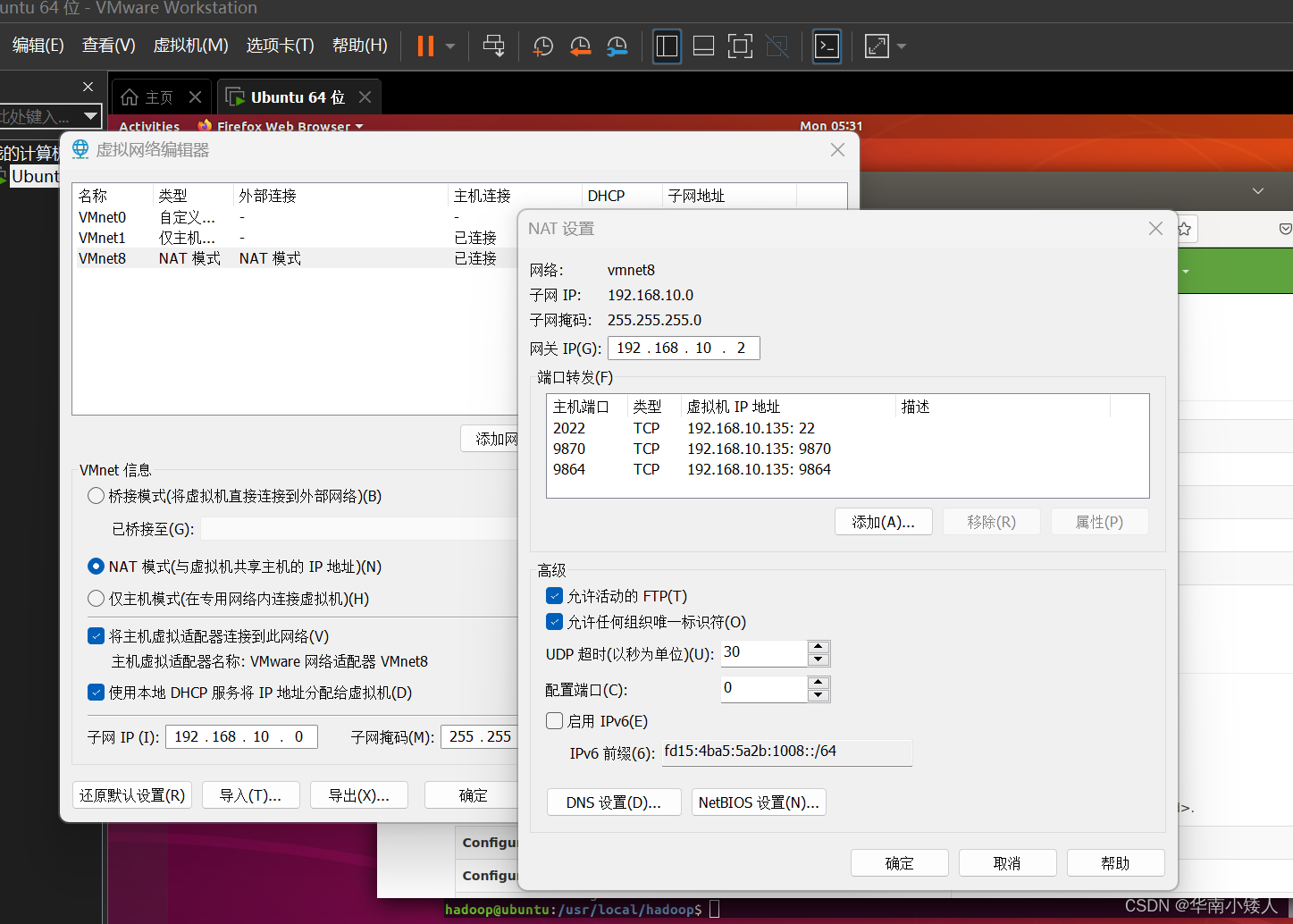
虚拟机设置端口转发SSH使用22端口,将虚拟子机的22端口映射到主机的2022端口;9870端口是hadoop的web查看端口;9864是hadoop提供的下载文件的端口,虚拟机机IP地址根据自身实际情况来更改
2.上传对应文件
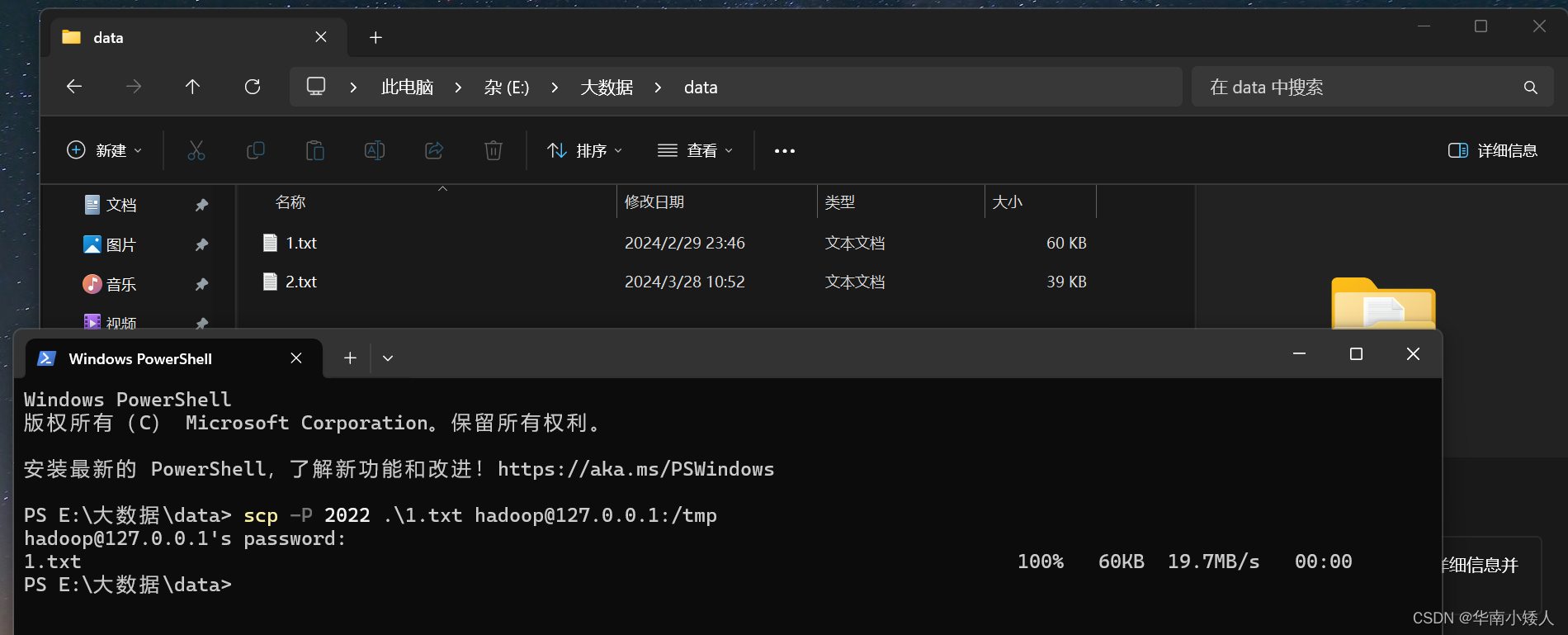
上传Windows对应的英文文件到Linux虚拟机中去,使用scp命令将文件上传到虚拟子机的/tmp目录,如图所示
通过ls命令进行查看,前后对比,发现文本成功上传
ls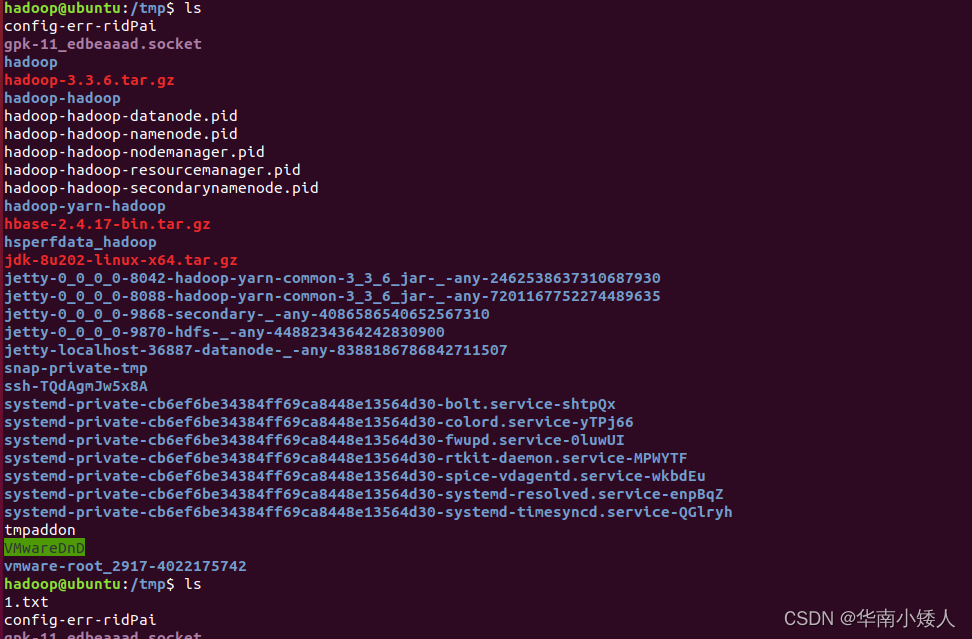
3.编写Java应用程序

如果遇到这个问题,可以按照这个步骤进行解决
具体情况可参考这篇彻底解决关于gedit的Unable to init server: Could not connect: Connection refused-CSDN博客
xhost local:gedit
export DISPLAY=:0
xhost local:gedit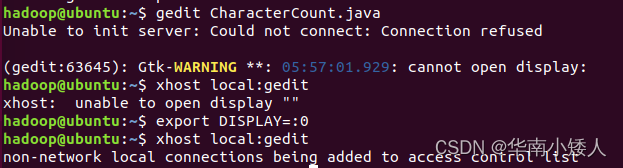
如图,出现"non-network local connections being added to access control list",表示问题已解决
向该文件中输入完整的程序代码,具体如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class CharacterCount {// Mapper 类,处理输入文件的每一行,并将字符逐个传递给 Reducerpublic static class CharMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);// map 方法将输入的每一行文本拆分为字符,并将每个字符写入上下文public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 将输入行转换为小写以实现不区分大小写String line = value.toString().toLowerCase();for (int i = 0; i < line.length(); i++) {char c = line.charAt(i);// 检查字符是否为字母或数字,如果是,则将其写入上下文进行统计if (Character.isLetter(c) || Character.isDigit(c)) {context.write(new Text(String.valueOf(c)), one);}}}}// Reducer 类,接收来自 Mapper 的字符统计数据并进行合并public static class CharReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();// reduce 方法将相同字符的统计数据合并为总数,并写入输出上下文public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}// 主函数,设置作业的配置信息,并运行 MapReduce 任务public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = new Job(conf, "character count");job.setJarByClass(CharacterCount.class);job.setMapperClass(CharMapper.class);job.setReducerClass(CharReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出路径System.exit(job.waitForCompletion(true) ? 0 : 1); // 运行作业并等待完成}
}
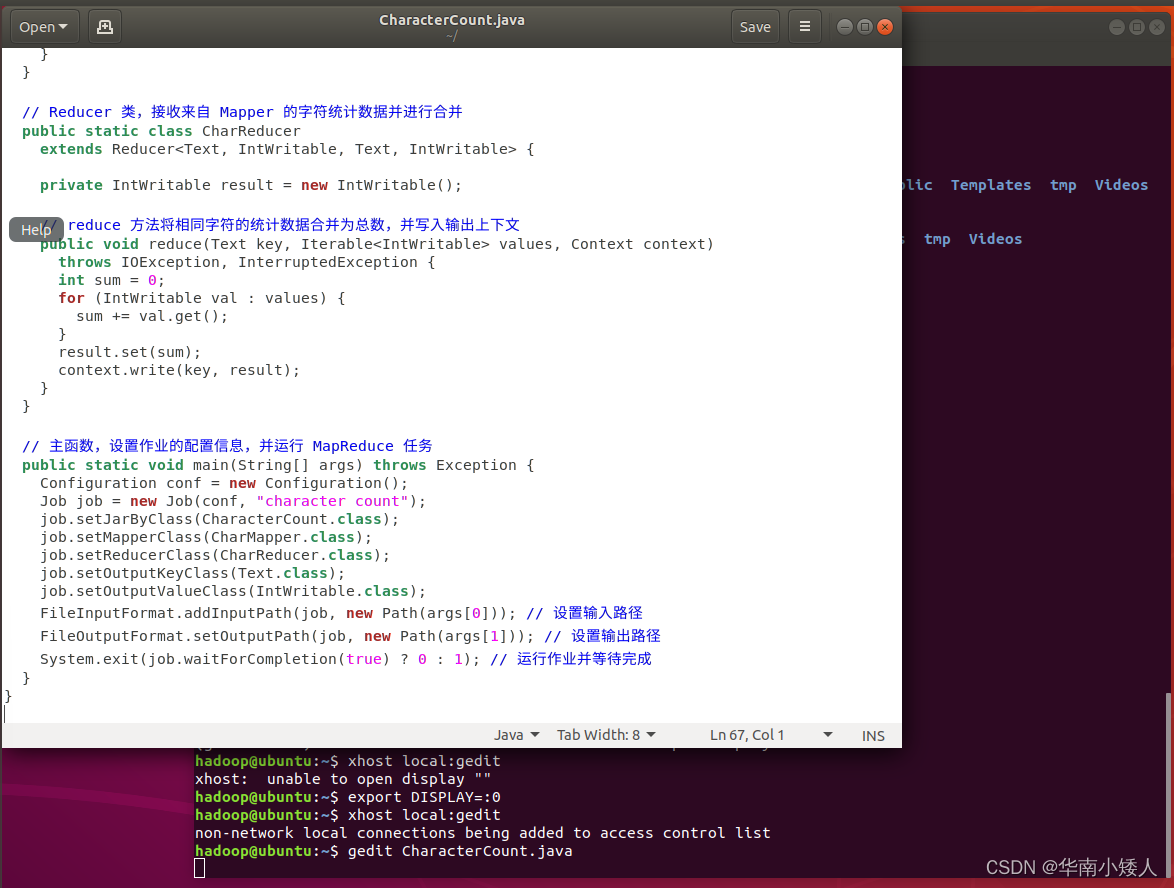
4. 编译打包程序
编译
javac -classpath `/usr/local/hadoop/bin/hadoop classpath` CharacterCount.java 
打包
jar cf CharacterCount.jar *.class
5. 运行程序
在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
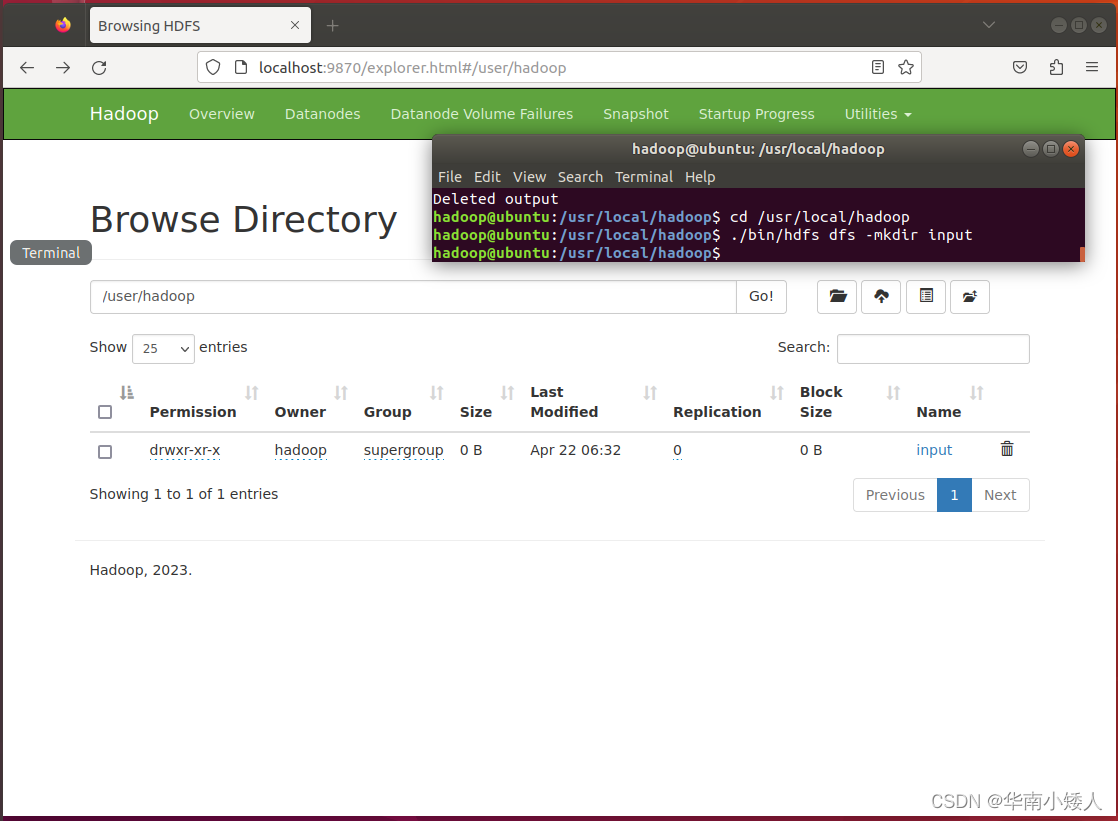
然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir input可以打开web进行查看,已成功建立input目录
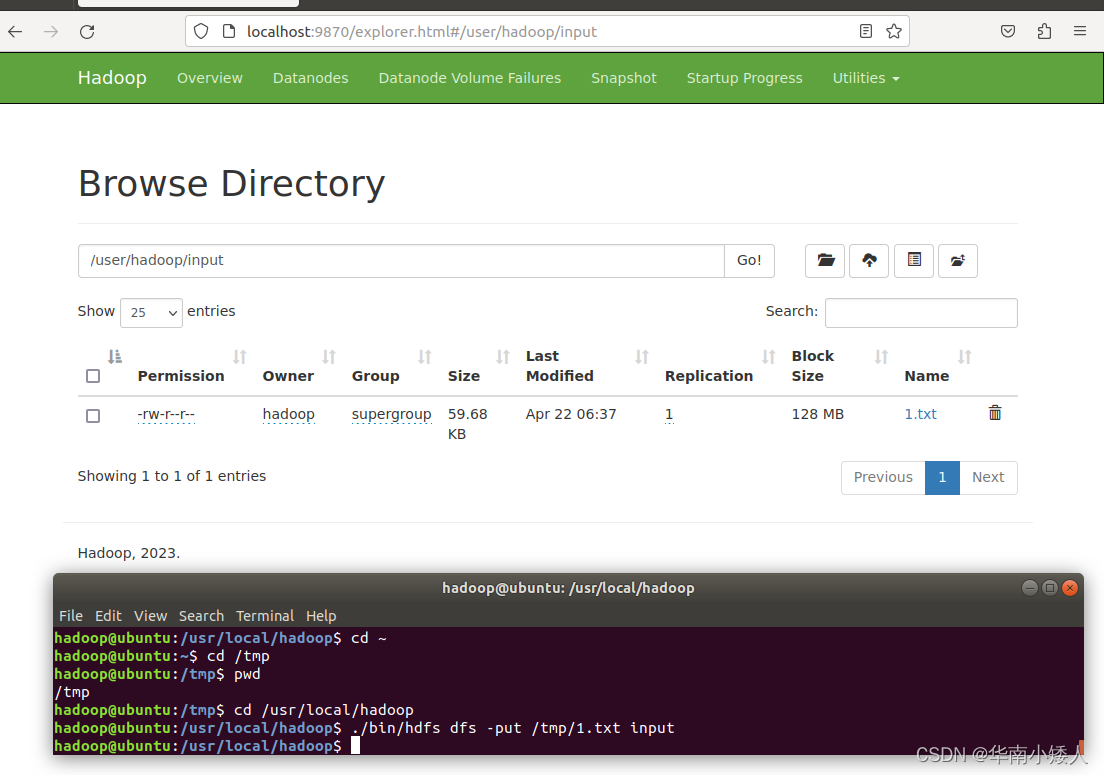
然后,把Linux中1.txt(此处位于“/tmp”目录下),上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put /tmp/1.txt input可以打开web页面进行查看,已成功上传至input目录
HDFS中已经存在目录“/user/hadoop/output”,则使用如下命令删除该目录:
cd /usr/local/hadoop
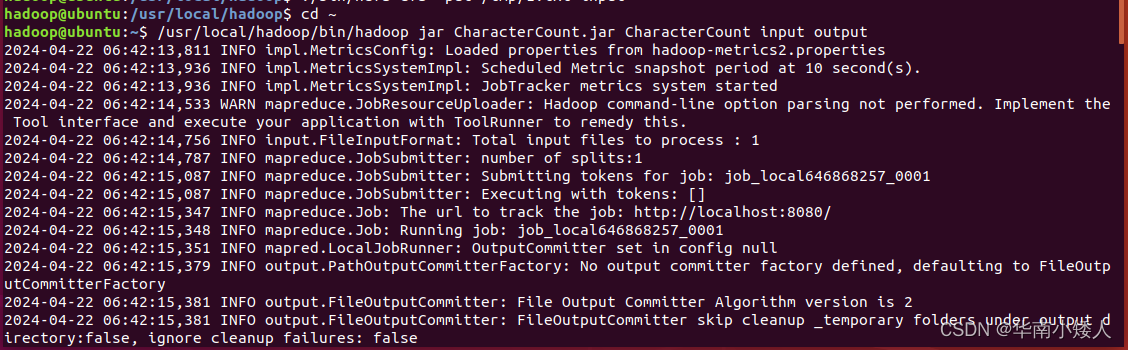
./bin/hdfs dfs -rm -r /user/hadoop/output现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下
cd ~
/usr/local/hadoop/bin/hadoop jar CharacterCount.jar CharacterCount input output
统计计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看结果:
cd /usr/local/hadoop
./bin/hdfs dfs -cat output/*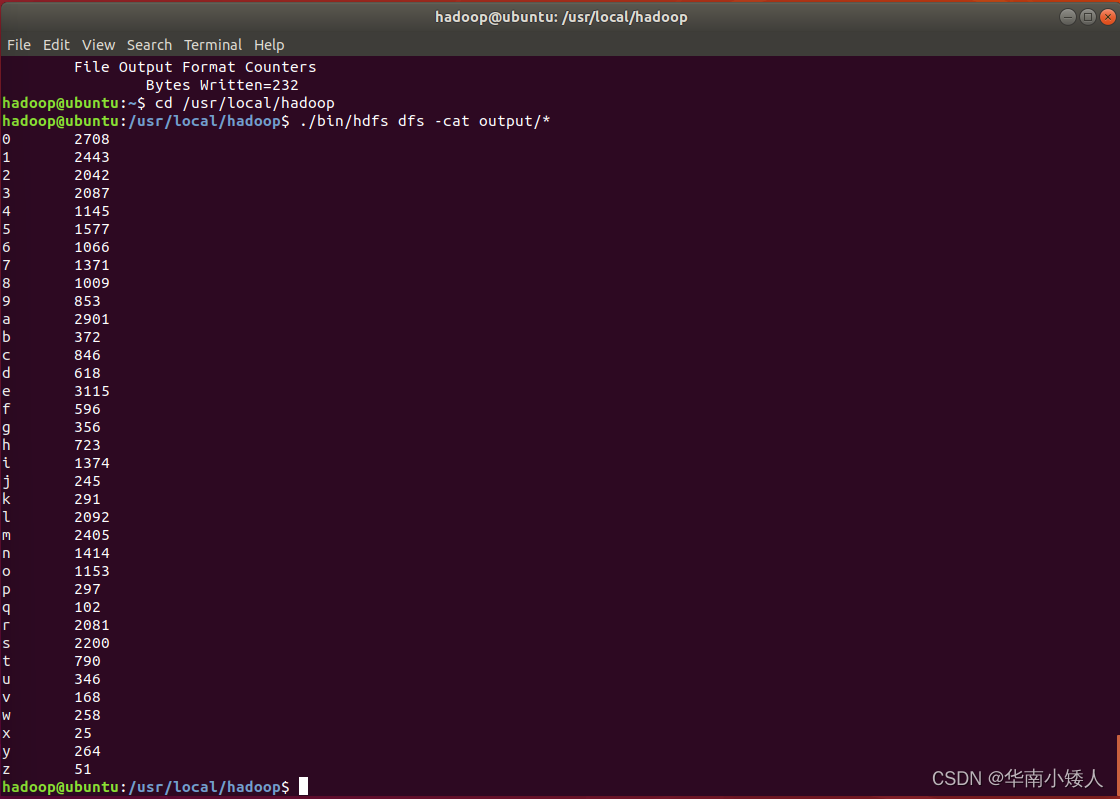
三、算法设计和分析
算法设计
Mapper阶段:
- 每行文本被分割成字符,并且每个字符被映射为键值对
(字符, 1)。- 在这个阶段,我们忽略了非字母和非数字的字符,只关注英文字母和数字的统计。
Reducer阶段:
- Reducer接收到相同字符的键值对列表。
- 它将这些值求和,以计算每个字符在整个文本中的出现次数。
- 最后,输出结果为
(字符, 出现次数)的键值对。
算法分析
- 可扩展性:Hadoop MapReduce框架具有良好的可扩展性,可以处理大规模数据集。
- 并行处理:Map阶段可以并行处理不同的文本行,而Reducer阶段可以并行处理不同的字符组。
- 容错性:Hadoop提供了自动的任务重试和容错机制,以处理节点故障或其他异常情况。
- 局限性:这个算法对于包含大量非字母和非数字字符的文本可能不太适用,因为它忽略了这些字符,导致统计不准确。此外,这个实现不考虑分布式环境下的性能优化,比如使用Combiner来减少中间数据传输量。
总体而言,这个算法在处理大型英文文本时表现良好,但在处理非英文文本或需要更精确统计的情况下可能需要进一步改进
四、实验总结
在本次实验中,我们使用Hadoop MapReduce框架统计了给定英文文本中每个字符的出现频率;整个过程可以分为几个步骤:
1. 准备工作:启动Hadoop集群,并上传所需文件
2. 编写Java应用程序:我们编写了一个Java程序,其中包括Mapper和Reducer类,分别用于处理输入文本和进行字符统计
3. 编译打包程序:将Java程序编译成可执行的Jar包
4. 运行程序:在Hadoop集群上运行MapReduce任务,将输入文本分析并得出结果
5. 算法设计和分析:我们设计了一个简单但有效的算法,利用MapReduce框架对文本进行字符频率统计,并分析了算法的可扩展性、并行处理能力和容错性
总的来说,本次实验通过运用Hadoop MapReduce框架,成功地统计了英文文本中字符的出现频率。实验流程涵盖了从集群准备到Java程序编写、编译、执行,再到算法分析与优化的完整过程。实验不仅验证了MapReduce在分布式环境下处理大数据的高效性和可扩展性,也揭示了算法在特定场景下的局限性和潜在优化空间。通过这次实践,我们深化了对MapReduce编程模型的理解,并积累了宝贵的分布式计算经验