从这一系列开始,我会带着大家一起了解我们的机器学习,了解我们spark机器学习中的MLIib算法库,知道它大概的模型,熟悉并认识它。同时,本篇文章为个人spark免费专栏的系列文章,有兴趣的可以收藏关注一下,谢谢。同时,希望我的文章能帮助到每一个正在学习的你们。
Spark-大数据技术与应用![]() https://blog.csdn.net/qq_49513817/category_12641739.html
https://blog.csdn.net/qq_49513817/category_12641739.html
目录
一、什么是机器学习
发展历史
机器学习模型
监督模型
无监督模型
概率模型
二、MLlib算法库
什么是MLlib算法库
MLlib的方法:
一、什么是机器学习
个人认为,机器学习是一个非常庞大的概念,不论是它本身的模型,运用它是产生的海量数据与决策,还是它那涵盖了众多的模型、算法和技术。并且随着技术的不断进步和应用领域的不断拓展,机器学习的影响力和重要性也将继续提升,所以,机器学习目前的热度高,未来很长时间内也不会衰减甚至更值得学习。
机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能核心,是使计算机具有智能的根本途径。
机器学习算法通过从数据中自动分析和学习规律,使计算机能够自动获取新知识和能力。它可以处理大量的复杂数据并从中提取出有用的信息,并根据不断的经验来改善自身的性能。机器学习算法构建一个基于样本数据的数学模型,即“训练数据”,以便在没有明确编程来执行任务的情况下进行预测或决策。
发展历史
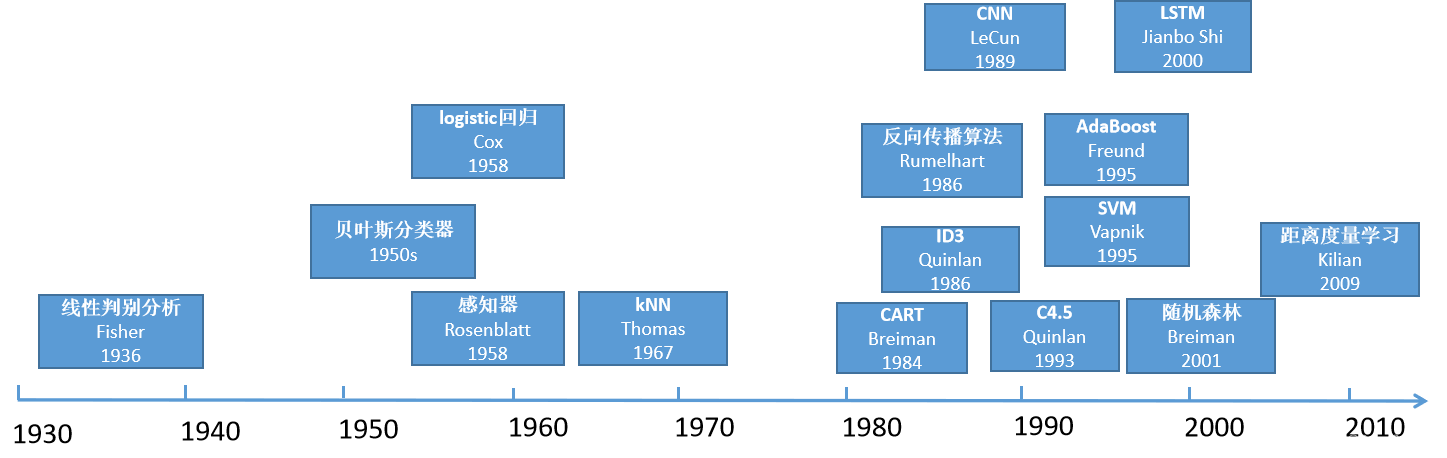
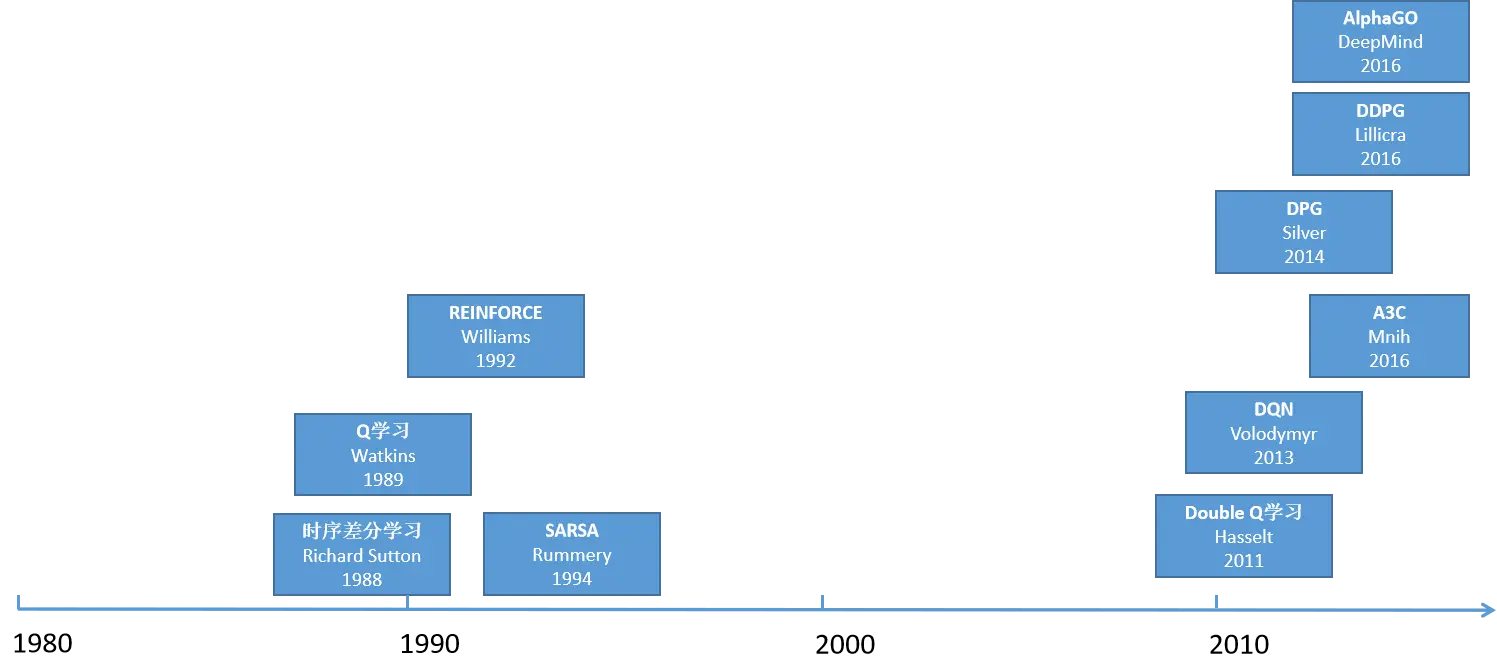
机器学习的发展可以追溯到上世纪50年代。1952年,Arthur Samuel在IBM开发了第一个自我学习程序,这标志着机器学习的起步。此后,随着技术的发展,机器学习领域不断取得突破,包括感知机、最近邻算法、决策树、随机森林等算法的提出,以及深度学习的兴起。这些创新推动了机器学习在各个领域的应用和发展。
有监督学习:
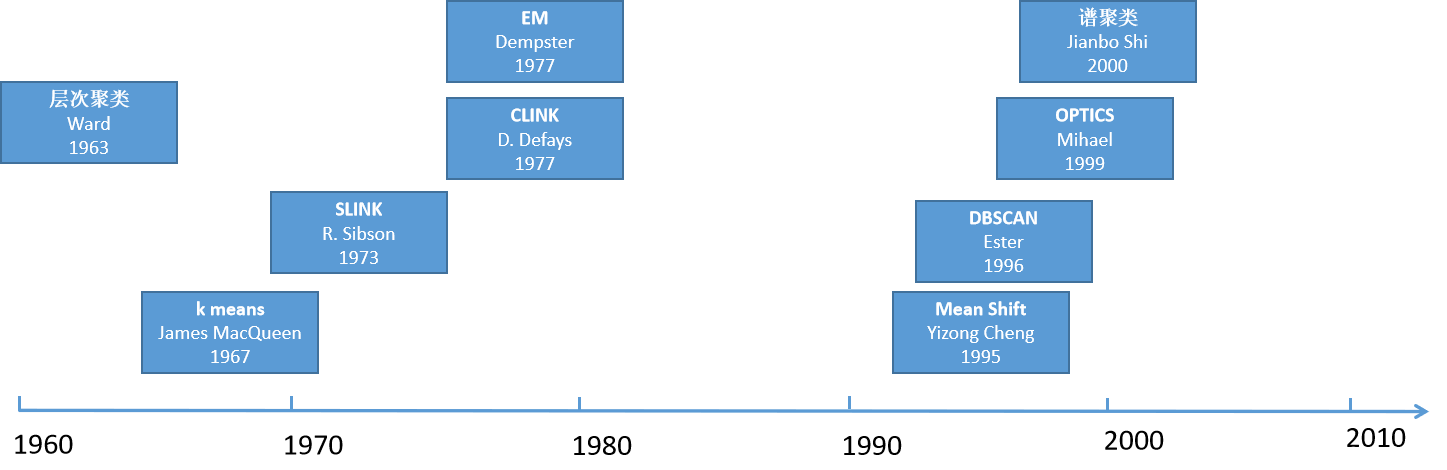
聚类:
概率图模型:

深度学习:
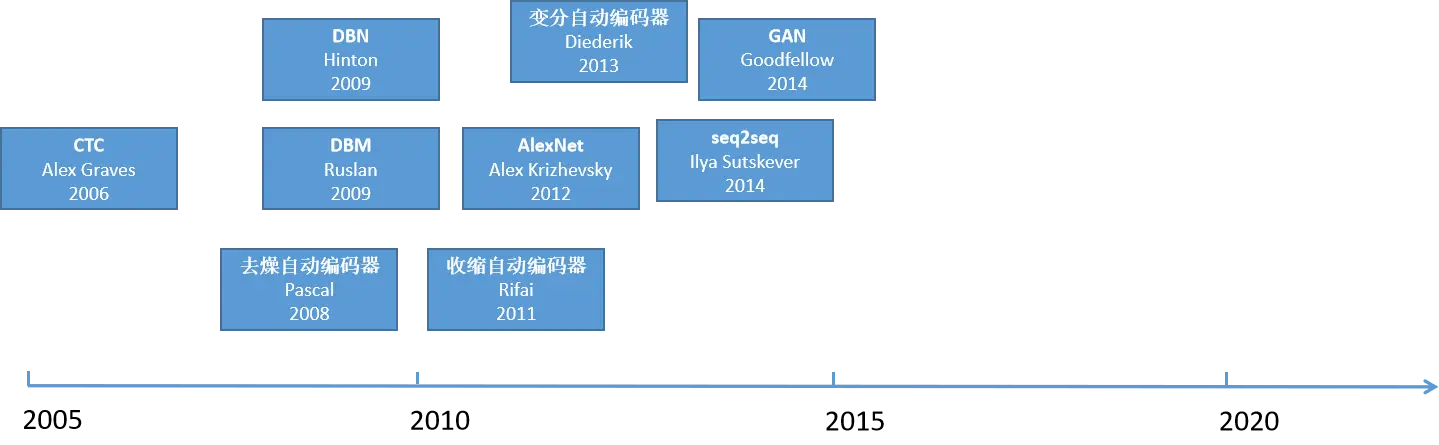
强化学习:
机器学习模型
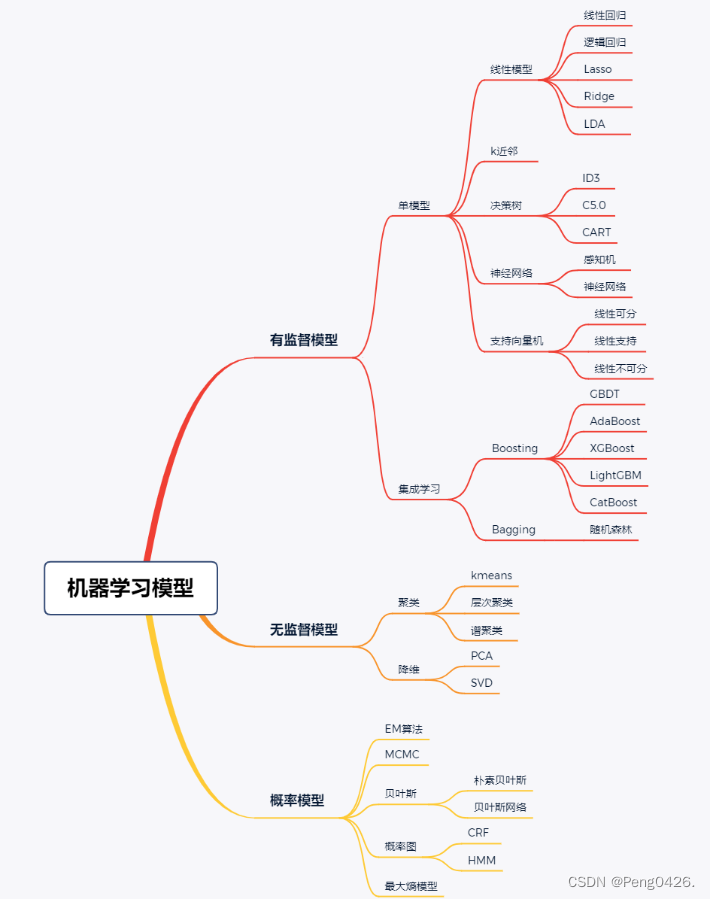
机器学习模型图
监督模型
工作原理:
- 数据标注:在监督学习中,训练数据集中的每个样本都被标注了一个目标值或标签。这些标签可以是分类标签(如类别名称)或回归值(如连续的数字)。
- 模型训练:算法使用这些带有标签的数据来训练模型。它学习如何根据输入特征预测目标值。
- 预测与评估:一旦模型训练完成,它就可以用于对新的、未标注的数据进行预测。预测的准确性通常通过评估指标(如准确率、召回率、F1分数等)来衡量。
在监督模型中,我们常用的算法有:
- 线性回归:用于预测一个连续的目标值,基于输入特征与目标值之间的线性关系。
- 逻辑回归:虽然名字中有“回归”,但实际上是一种分类算法,用于预测二分类或多分类问题。
- 支持向量机(SVM):通过找到一个超平面来最大化不同类别之间的间隔,从而进行分类。
- 决策树:通过一系列的问题和答案来进行预测,每个问题都基于一个输入特征。
- 随机森林:由多个决策树组成,通过集成多个树的预测结果来提高准确性。
- 神经网络:模拟人脑中的神经元结构,通过多层网络进行学习和预测。
广泛应用在:
- 图像识别:识别图像中的物体或场景。
- 自然语言处理:情感分析、文本分类、机器翻译等。
- 金融领域:信用风险评估、股票价格预测等。
- 医疗诊断:基于医疗图像或患者数据预测疾病。
监督学习模型是机器学习中的核心组成部分,它通过学习带有标签的数据来建立预测模型,并在各种实际应用中发挥着重要作用。
无监督模型
工作原理:
无监督学习模型通过对大量无标签数据进行迭代计算,自动地发现数据的结构和模式。这些模型通常基于数据的相似性、距离或其他度量来构建,从而将数据分组或降维。
在无监督模型中,我们常用的算法有:
- 聚类算法:如K-均值聚类(K-means)和层次聚类。这些算法将数据点划分为不同的组或簇,使得同一簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。
- 降维算法:如主成分分析(PCA)和自编码器。这些算法用于减少数据的维度,同时保留数据中的主要特征或结构。降维有助于减少计算复杂性、消除噪声并可视化高维数据。
广泛应用在:
- 图像处理:用于图像分割、特征提取和异常检测。
- 社交网络分析:识别社区、用户群体和社交模式。
- 市场分析:通过聚类分析消费者行为和市场趋势。
- 自然语言处理:用于文本聚类和主题建模。
无监督学习模型为处理未标记数据提供了强大的工具,能够发现数据中的结构和模式,为各种实际应用提供了有力支持。
概率模型
工作原理:
在机器学习中,概率模型通过给定的数据来估计和计算不同事件或结果发生的概率。这通常涉及到数据的统计分析和概率推断,以确定模型参数的最优值。一旦模型建立完成,它就可以用于预测新数据的行为或结果,并根据概率分布给出相应的预测概率。
常用的算法有:
-
朴素贝叶斯算法:这是一种基于贝叶斯定理和特征条件独立假设的分类方法。它常用于文本分类、垃圾邮件过滤等任务。朴素贝叶斯算法根据先验概率和特征条件概率来计算后验概率,从而进行分类。根据应用场景的不同,朴素贝叶斯算法可以分为GaussianNB、MultinomialNB和BernoulliNB等变种。
-
隐马尔可夫模型(Hidden Markov Model, HMM):HMM是一种统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。HMM常被用于时序数据的建模,如语音识别、自然语言处理等。
-
最大熵模型:最大熵原理是一种选择概率模型的原则,它认为在满足约束条件的模型集合中,选择熵最大的模型是最好的模型。最大熵模型可以用于各种分类和回归任务。
-
概率图模型:包括一系列基于图结构的概率模型,如马尔可夫随机场、信念网络等。这些模型通过图来表示变量之间的关系,并利用图论和概率论的方法来进行推理和学习。
-
混合高斯模型(Gaussian Mixture Model, GMM):GMM是一种概率模型,它假设所有数据都是由有限个高斯分布混合而成的。GMM常用于聚类分析和密度估计。
-
期望最大化算法(Expectation-Maximization, EM):EM算法是一种迭代方法,常用于概率模型中的参数估计。它通过在E步(期望步)计算期望,然后在M步(最大化步)最大化这个期望,来找到参数的最优估计。
-
变分推断(Variational Inference):这是一种在概率图模型中进行近似推断的方法。它通过优化一个易于处理的分布来近似难以处理的真实后验分布。
-
蒙特卡洛方法:这是一种基于随机抽样的统计方法,用于估计复杂函数的积分和解决各种概率问题。在机器学习中,蒙特卡洛方法常用于模型参数的估计和复杂概率分布的计算。
二、MLlib算法库
什么是MLlib算法库
MLlib是Spark的机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模的数据集。它提供了一组丰富的机器学习算法和工具,用于数据预处理、特征提取、模型训练和评估等任务。MLlib是基于Spark的分布式计算引擎构建的,可以处理大规模数据集,并利用分布式计算的优势来加速机器学习任务的执行。
MLlib提供了丰富的算法实现,包括线性回归、逻辑回归、决策树、随机森林、梯度提升树、K-means聚类等,以及用于特征提取、转换和选择的工具。此外,MLlib还支持使用管道(Pipeline)API将多个机器学习步骤组合成一个统一的流程,从而简化模型训练和调优的过程。
MLlib的方法:
| 方法 | 作用 | 使用方式 |
|---|---|---|
| 分类 | 用于预测离散型目标变量 | 使用MLlib的分类算法(如逻辑回归、决策树、随机森林等)训练模型,然后对新的数据进行预测。 |
| 回归 | 用于预测连续型目标变量 | 使用MLlib的回归算法(如线性回归、决策树回归等)训练模型,用于预测数值型结果。 |
| 聚类 | 用于将数据划分为具有相似性的不同簇 | 利用MLlib的聚类算法(如K-means)对数据进行分组,发现数据中的结构和模式。 |
| 协同过滤 | 用于推荐系统中的用户或物品的相似度计算 | 应用MLlib的协同过滤算法,根据用户的历史行为和其他用户的相似性生成推荐。 |
| 特征工程 | 提取、转换和选择特征,提高模型性能 | 使用MLlib的特征化工具进行特征提取、降维、转换和选择,优化特征表示。 |
| 管道(Pipeline) | 构建、评估和调整机器学习管道 | 利用MLlib的管道API,将多个机器学习步骤组合成一个统一的流程,方便管理和调优。 |
| 模型持久化 | 保存和加载模型,以便复用和部署 | 使用MLlib的持久化功能,将训练好的模型保存到文件或数据库中,方便后续的预测和部署。 |
最后,MLlib是基于Spark的分布式计算引擎构建的,因此在使用MLlib时,我们需要熟悉Spark的基本概念和编程模型,如RDD(弹性分布式数据集)和DataFrame等。通过编写Spark应用程序,我们可以利用MLlib提供的算法和工具来处理大规模数据集,并进行高效的机器学习任务。