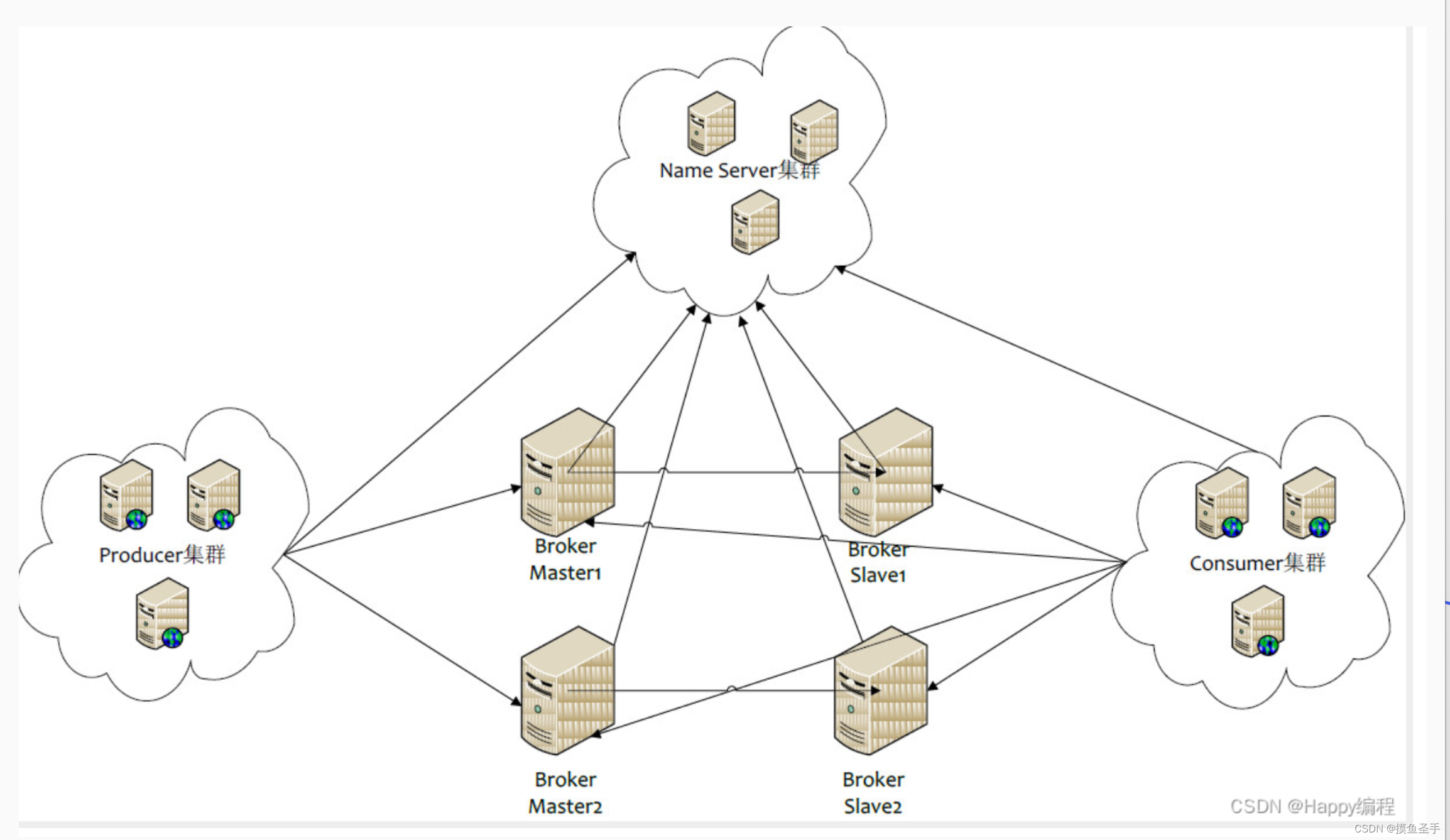
1 ffmpeg 硬件解码
使用硬件解码后不要transfer到内存,使用cuda转化nv12 -> bgr24
转化完毕后cuda里面存了一份bgr24
2 gpumat 和 cuda 互操作
如果需要opencv gpumat直接使用cuda内存,则可以手动构造gpumat
可以使用gpumat的各种函数
uchar3* cuda_rgb_data; // 假设这是您的CUDA内存中存储RGB数据的指针
int width, height; // 图像的宽和高
cv::cuda::GpuMat gpu_rgb(cuda_rgb_data, height, width, CV_8UC3, cudaStream_t stream = 0);
uchar3* cuda_rgb_data_r = reinterpret_cast<uchar3*>(gpu_rgb.ptr(0)); // 获取R通道指针
uchar3* cuda_rgb_data_g = reinterpret_cast<uchar3*>(gpu_rgb.ptr(1)); // 获取G通道指针
uchar3* cuda_rgb_data_b = reinterpret_cast<uchar3*>(gpu_rgb.ptr(2)); // 获取B通道指针
ptr(0)、ptr(1)和ptr(2)分别获取了R、G、B三个通道的数据指针。
使用reinterpret_cast将uchar指针转换为uchar3,便于在CUDA内核中以RGB像素的形式访问。
在CUDA内核中使用GpuMat数据:
在CUDA内核函数中,直接使用获取的CUDA指针访问GpuMat中的RGB数据。
__global__ void cuda_kernel(uchar3* cuda_rgb_data_r, uchar3* cuda_rgb_data_g, uchar3* cuda_rgb_data_b, ...)
{// 假设 blockIdx.x 和 threadIdx.x 分别表示当前线程处理的图像位置的行和列索引int row = blockIdx.x * blockDim.x + threadIdx.x;int col = blockIdx.y * blockDim.y + threadIdx.y;if (row < height && col < width) // 检查索引是否有效{// 通过指针访问GpuMat中的RGB数据uchar3 rgb_pixel = make_uchar3(cuda_rgb_data_r[row * width + col].x,cuda_rgb_data_g[row * width + col].y,cuda_rgb_data_b[row * width + col].z);// ... 使用rgb_pixel进行CUDA内核计算 ...}
}
至此,将GpuMat中的RGB数据暴露给了CUDA内核,可以直接在内核中进行访问和处理。
需要显示时,有两种方式,互操作opengl渲染,不用把cuda内存
3 cuda 与 opengl 互操作
1 首先初始化GLFW并创建一个OpenGL窗口。
2 注册并初始化一个OpenGL纹理,用于接收CUDA处理后的RGB图像数据。
3 使用CUDA-OpenGL Interop库注册这个OpenGL纹理,以便CUDA可以直接访问和写入。
4 在CUDA端,假设有一个内核cuda_process_rgb已经处理了RGB图像,并将结果存储在设备内存d_processed_img中。
5 使用cudaGraphicsMapResources、 cudaGraphicsSubResourceGetMappedArray和cudaMemcpyToArray将CUDA端的RGB图像数据复制到已注册的OpenGL纹理中。
6 在主渲染循环中,绑定纹理并使用一个简单的四边形以及相应的着色器程序来渲染纹理。
以下是示例代码,并不完整
#include <iostream>
#include <vector>
#include <GLFW/glfw3.h>
#include <cuda_runtime.h>
#include <cuda_gl_interop.h>// CUDA kernel to process RGB image (omitted for brevity)
__global__ void cuda_process_rgb(uchar3* d_img, int width, int height);int main()
{// Initialize GLFW and create an OpenGL windowif (!glfwInit()){std::cerr << "Failed to initialize GLFW" << std::endl;return -1;}glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 4);glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 6);glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);glfwWindowHint(GLFW_RESIZABLE, GL_FALSE);GLFWwindow* window = glfwCreateWindow(800, 600, "CUDA-OpenGL Interop Example", nullptr, nullptr);if (!window){std::cerr << "Failed to create GLFW window" << std::endl;glfwTerminate();return -1;}glfwMakeContextCurrent(window);// Initialize GLEW (if needed)glewExperimental = GL_TRUE;if (glewInit() != GLEW_OK){std::cerr << "Failed to initialize GLEW" << std::endl;glfwTerminate();return -1;}// Create an OpenGL texture for renderingGLuint gl_tex;glGenTextures(1, &gl_tex);glBindTexture(GL_TEXTURE_2D, gl_tex);glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, nullptr);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);// Register the OpenGL texture for CUDA-OpenGL interopcudaGraphicsResource* cuda_tex_res;cudaGraphicsGLRegisterImage(&cuda_tex_res, gl_tex, GL_TEXTURE_2D, cudaGraphicsRegisterFlagsSurfaceLoadStore);// CUDA processing: assume you have a pre-allocated CUDA device memory buffer for the processed RGB imageuchar3* d_processed_img;cudaMalloc(&d_processed_img, width * height * sizeof(uchar3));// Call your CUDA kernel to process the image (omitted here)// cuda_process_rgb<<<...>>>(d_processed_img, width, height);// Copy the processed RGB image from CUDA to the registered OpenGL texturecudaArray* cu_array;cudaGraphicsMapResources(1, &cuda_tex_res, 0);cudaGraphicsSubResourceGetMappedArray(&cu_array, cuda_tex_res, 0, 0);cudaMemcpyToArray(cu_array, 0, 0, d_processed_img, width * height * sizeof(uchar3), cudaMemcpyDeviceToDevice);cudaGraphicsUnmapResources(1, &cuda_tex_res, 0);// Set up a simple shader program and vertex data for rendering a full-screen quad (omitted for brevity)while (!glfwWindowShouldClose(window)){glClear(GL_COLOR_BUFFER_BIT);// Bind the texture and render a full-screen quad using your shader program// ...glfwSwapBuffers(window);glfwPollEvents();}// Clean up resourcescudaFree(d_processed_img);cudaGraphicsUnregisterResource(cuda_tex_res);glDeleteTextures(1, &gl_tex);glfwTerminate();return 0;
}
总结
整个流程是一旦数据到了cuda内核,就不要轻易下载到内存,直接在cuda里面进行操作,一直到渲染完毕,后面在给出完整的代码示例