文章目录
- 前言
- 小总结(前文回顾)
- 第二章 多臂老虎机
- 2.2.2形式化描述
- 第三章 马尔可夫决策过程
- 3.6 占用度量 代码
- 3.6 占用度量 定理2
- 第四章 动态规划算法
- 4.3.3 策略迭代算法 代码
- 总结
前言
参考:
《动手学强化学习》作者:张伟楠,沈键,俞勇
动手学强化学习 网页版
动手学强化学习 github代码
动手学强化学习 视频
强化学习入门这一篇就够了!!!万字长文(讲的很好)
+
参考:
强化学习入门(第二版)读书笔记
小总结(前文回顾)
先简单总结一下第一章所学的知识点:
我做了一个思维导图很方便理解
之后学习完会在这里一直更新。
这里2、3、4章作者讲的非常好,就是得多读几遍,这里只做下当时学习时没弄明白的笔记。
补充一下:第2、3、4章要下载的库
#第2章
pip install numpy
pip install matplotlib
#第4章
pip install pygame
pip insatll gym
第二章 多臂老虎机
第二章的代码基本上认真看都能看懂,和伪代码一对照看,很容易就看懂了。
random.uniform(x, y) 是指在均匀分布下(所有值出现的概率相等),随机生成[x,y]内的浮点型数,包含x和y。
2.2.2形式化描述

这里"R(·|a)"通常表示在给定条件"a"的情况下,某个随机变量的概率分布函数。这里的”·"是一个占位符,代表随机变量的可能值。例如,如果我们有一个随机变量X,那么"R(x|a)"将表示在条件"a"下,随机变量X取值为x的概率。
第三章 马尔可夫决策过程
3.6 占用度量 代码
占用度量定义:
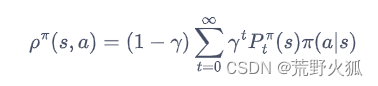
问题:红色箭头和公式对不上

这一部分的估计实际概率就相当于

原因:
这样就和公式对应了。
3.6 占用度量 定理2
问题 :不理解这个定理2是什么意思。

目前自己理解为:
分母上的a’为:除了状态s目前的动作a外的其他动作。
这里分母为能访问到状态s下的其他动作的概率的和。
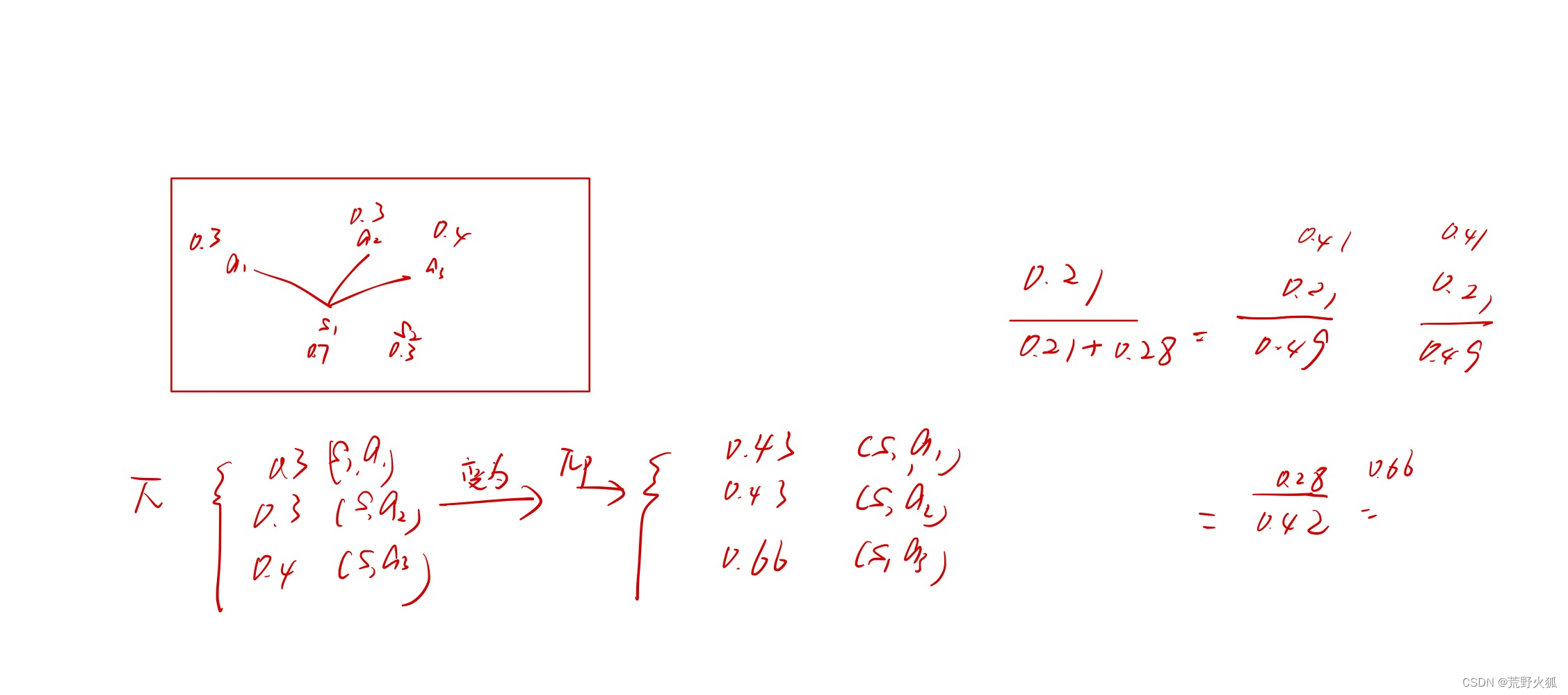
但没有具体程序,也没有实际例子,不能断定。
第四章 动态规划算法
4.5冰湖环境中,需要改成如下代码。
import gym
env = gym.make("FrozenLake-v1", render_mode="human")
env = env.unwrapped # 解封装才能访问状态转移矩阵P
env.reset() # 重置环境
env.render() # 环境渲染,通常是弹窗显示或打印出可视化的环境
4.3.3 策略迭代算法 代码
公式为:
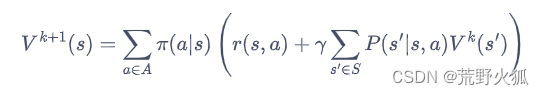
问题:
1、是因为这个环境是基于模型的,所以要乘以状态转移概率吗?
2、这里+= 用了累加,可公式中只有对状态转移函数进行了累加求和,这个r回报没有进行累加求和,为什么代码里用了+=的形式,而不是先+=后面的状态转移函数再进行单独的相加r?
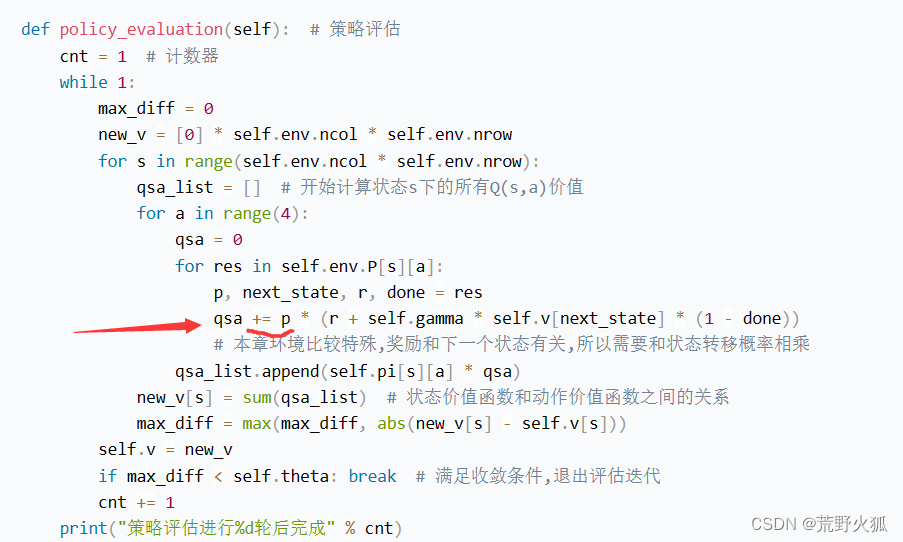
原因:这里的r(s,a)根据先前书上的定义,r(s,a)=E(r|S=s,A=a),也就是说这个已经是求过期望后的了。
如果它是求过期望前:则公式为这样:
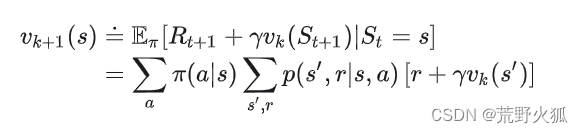
那么两个问题就迎刃而解了。这里qsa有点迷惑性质
1、这里的p对应的是p(s’|s,a)。
若不是基于模型的,或者说不是这个算法的,大概率是没有这个p的,看每个算法的公式异同了。
2、这里的累加放在这里就对应第二个累加求和的符号。
总结
其余代码多看两遍就理解了,和伪代码都对的上。