一、开篇
二、Apache Kylin是什么?
三、为什么要使用Apache Kylin?
四、Apache Kylin的架构
五、Kylin使用案例
六、Kylin + AI展望
七、总结
一、开篇
我这个人有个习惯,每天早上起床刷牙之后要先喝一杯果汁。我只喜欢吃3种水果:苹果、梨、香蕉,所以我每天早上都在纠结是苹果+梨,还是梨+香蕉,还是苹果+梨+香蕉等等。
刚开始只有我一个人还好,早上早起几分钟榨一下挺方便。后面我女朋友也要喝,我就再早起一点,水果多了,榨的时间也变长。后面我岳父岳母也要喝,但我已经不想再早起,于是又买了台榨汁机。
到后面,我爸我妈也要喝。。我不想早起的同时也不想买榨汁机了,因为我觉得后面家里谁要喝还得继续买,承受不起了。
于是我用前面两台普通榨汁机换购了一台多功能榨汁机,这个多功能机器厉害了,我只需要提前一天放好水果,然后定个时,这样它就会把所有水果的果汁榨出来,我们想喝什么再自己混合就行。
这样除非水果种类增加了,因为放水果的槽有限,花费的时间也需要增加。不然无论多少人喝,都是够喝的。虽然占的面积比较大,但能节省我时间和金钱,值得!
而Apache Kylin与这台多功能榨汁机有异曲同工之妙~
二、Apache Kylin是什么?
1.Apache Kylin是一个大数据分析框架,可以理解为进化版的Hive,同时也是OLAP on Hadoop的一个引擎,常被用于数仓解决方案。
2.中国第一个Apache顶级开源项目,比阿里的Apache Dubbo、RocketMQ都早。
3.同样的数据量,Mysql可能是小时级别,而Hive是分钟级,而Apache Kylin则是亚秒级。
三、为什么要使用Apache Kylin?
1.从传统数据库(Mysql等)到 SQL on Hadoop(Hive、SparkSql)等,都会发现一个问题,查询时间随数据量的增大而增加。
2.查询数据量继续增大,而查询时间不变的话,就得水平拓展机器,让并行计算速率加快。但这样一方面增加了机器资源的经济成本,一方面又增加机器运维的人力成本。
3.Apache Kylin采用预计算方式,以空间换时间的方法,解决上述两个问题。让分析师把更多时间花在业务建模方面,而不是等待查询结果。
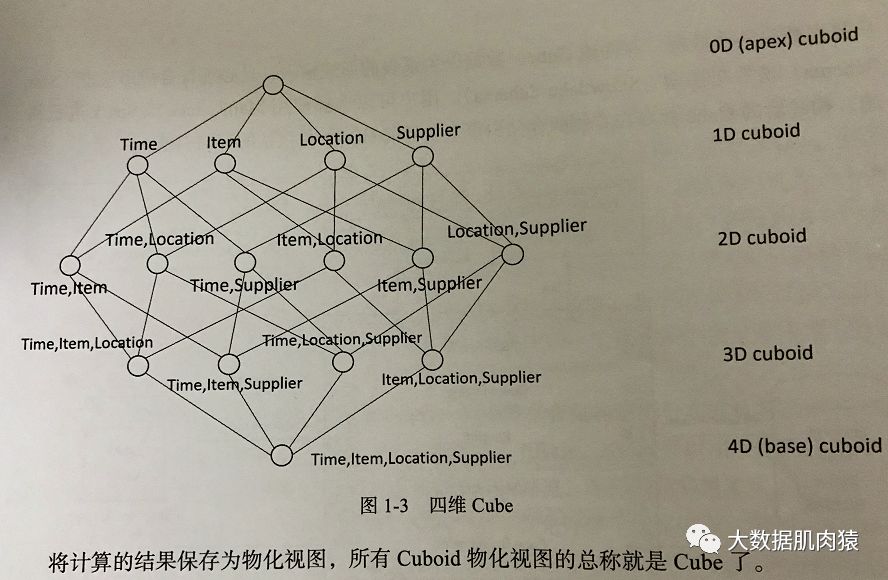
四、Apache Kylin的架构
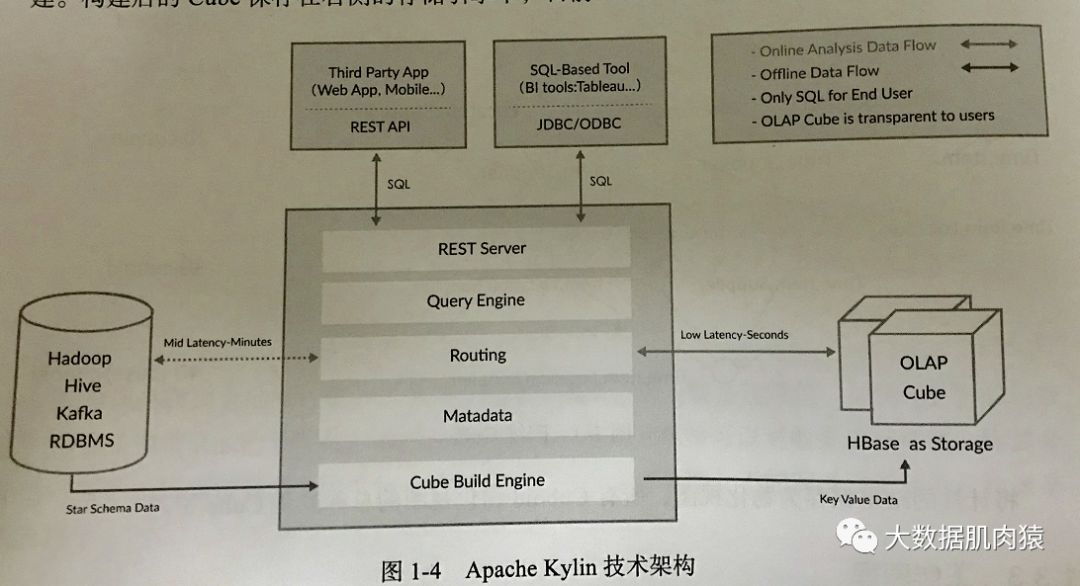
Apache Kylin权威指南(第二版)
1.首先看图的最左边,有Hadoop、Hive、Kafka等。这边是项目的数据源,可能存储在Hive、或者Mysql,又或者流式的Kafka。
2.将数据源配置好之后,由中间的计算引擎去拉,根据分析师建模配置好的维度,用户可以选择是用MapReduce或Spark进行计算,然后生成Cube。
3.将生成的Cube数据集存储到右边的HBase,等待被查询。
4.最上方的Rest api以及JDBC和ODBC就是查询入口,因为整个预计算以及Cube对用户是隐性的,所以用户只需要按照正常的查询操作就行,不用关心技术实现细节。