原文在 AddressSanitizer: A Fast Address Sanity Checker
还有一些讨论在:http://stackoverflow.com/questions/11806469/clang-with-faddress-sanitizer-on-windows
摘要
内存访问问题,如buffer越界访问,使用已经释放的内存等,一直都是诸如C,C++等编程语言所面对的大问题。目前有很多内存错误检测方法,但可能慢,也可能功能太有限,或者两者都有。
这篇论文论述地址消毒技术,一种新的内存错误检测技术。我们的工具检查对于堆,栈,全局变量的越界访问,以及释放后使用问题。它使用了一种特殊而简单的内存分配器以及代码实现,可以很方便的在任何编译器,二进制转换系统甚至硬件中实现。
地址消毒兼顾运行效率和功能的全面性,它平均仅降低系统73%的运行速度,并且它在错误发生的时刻(而不是之后)精确定位问题。它目前已经发现了吃肉么浏览器超过300个隐藏问题,以及其他软件的问题。
介绍
业界有很多内存问题定位工具,这些工具有着不同的速度,内存消耗,可检测的错误类型,检测到一个问题的概率,支持的平台等等。很多工具可以成功的定位多种问题但是将引发过高负载,或者运行流畅但只能检查较少问题。地址消毒技术,一种兼顾性能和功能的新型工具。地址消毒技术可以找到越界错误(关于堆,栈,全局变量)以及释放后使用错误,仅降低系统73%的运行速度和消耗3.4倍的内存。这使得它是个全面测试C/C++应用程序的好的选择。
地址消毒技术由两部分组成:一个模块和一个运行时库。这个模块修改代码去检查每次内存访问的阴影状态,并且在栈和全局变量周围创建剧毒的红区来检测上溢出和下溢出。当前的实现是基于LLVM编译器,运行时库取代了malloc,free和其他函数,在堆区域上下创建红区,检测释放后堆区域的使用,并且负责错误报告。
贡献
在这篇论文中我们:
- 提出一种新的阴影内存使用方式,降低了系统负载
- 使用了创新的阴影状态编码来使能阴影内存压缩----128到1的映射---来检测越界和释放后使用错误
- 基于我们的阴影编码描述了一种特殊的内存分配器
- 评估一种新的公共有效工具以有效检测内存问题
阴影内存
很多工具使用阴影内存来存储每片应用数据相关的冗余数据。通常一个应用地址映射到一个阴影地址或者通过直接测量和偏移。也就是说整个应用地址空间映射到一个单独的阴影内存空间,或者通过多层转换包括表处理。直接映射例如TaintTrace和LIFT。TaintTrace要求一个和应用数据大小相等的阴影空间,这个会导致某些无法基于自身一半内存存活的应用的困难,LIFT的阴影区域有1/8的应用数据区域。
为了提供更加灵活的地址空间映射,有些工具提供了多级转换方式。Valgrind和Dr Memory分割他们的阴影内存区域成一片一片的,使用一个表来查表获取阴影内存。这样就需要附加的内存消耗。对于64位系统,Valgrind对不在低32GB的应用层地址使用附加的表层。
地址消毒算法
从原理上讲,我们的内存错误检测技术类似于基于Valgrind的工具AddrCheck:使用影子内存来记录是否每个应用内存的字节是可访问的,并且使用设备在每次应用装在和存储的时候来检查。然而,地址消毒使用了一种更有效率的影子映射,一种更紧凑的阴影编码,在栈,全局变量和堆中检查错误比Addrcheck快一个量级。下面这节讲述了地址消毒是如何编码和映射它的影子内存,插入它的指令,以及运行时如何运作的
影子内存
malloc函数返回的内存地址至少是8字节对齐的。可得,任何8字节对齐的堆内存序列处于以下9中状态之一:前k(0<=k<=8)字节是可寻址的,剩下的8-k个是不可以的。这个状态可以编码到影子内存的一个字节。
地址消毒使用1/8个虚拟地址空间到它的影子内存并且使用一个直接映射来转换应用地址到相关的影子地址。假如应用内存地址为Addr,影子内存对应的地址是 (Addr>>3)+Offset。如果Max-1是虚拟空间的最大有效地址的话,Offset的值需要满足如下条件:从Offset到Offset+Max/8没有在系统启动时占用。不想Umbra,Offset必须对每个平台静态选择,但是我们不把这个看作是有效得限制。在一个典型的32bit Linux or MacOS系统,它的虚拟地址空间是0x00000000-0xffffffff,我们设置Offset是0x20000000 (2^29)。在一个有47个有效地址的64bit系统中,我们使用Offset =0x0000100000000000 (2^44)。在某些情况下(例如Linux上使用-fPIE/pie编译选项)可以简单的使用0 Offset。
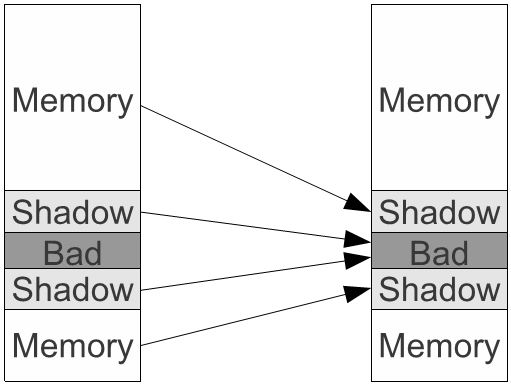
表1展示了地址空间分布,应用内存分为上下两部分,映射到相关的影子区域。使用影子映射到影子区域的地址给了我们在坏区的地址。所谓坏区,就是被页保护机制标记为无法访问的区域。
我们使用下面的编码方式来编码每个影子字节:0意味着所有8字节相关应用地址是可寻址的;k意味着前k字节是可寻址的;任何负值表示整个8 byte字都是无法寻址的。我们使用不同的负值来表示不同的不可寻址的内存(堆红区,栈红区,全局变量红区,释放后的内存)
影子映射可以描述成如下形式:(Addr>>Scale)+Offset,Scale是1到7中的一个数。如果Scale是N的话,影子内存占用1/2^N的虚拟地址空间,并且红区最小为2^N个字节。一个影子字节描述一个2^N字节大小的块的状态并且能编码成2^N+1种不同的值。较大的Scale值需要较少的影子内存和更大的红区大小来满足对齐要求。大于3的Scale值需要更复杂的指令来访问8字节对齐空间,但是对于那些无法申请一个独立而持续的1/8虚拟空间的应用来说是可选的。
指令
当进行一次8bytes内存访问时,地址消毒计算相应的影子字节,加载此字节,并且检查它是不是0:
ShadowAddr = (Addr >> 3) + Offset;
if (*ShadowAddr != 0)
ReportAndCrash(Addr);
ReportAndCrash(Addr);
当进行一次1,2,4bytes内存访问时,情况略复杂了点:如果影子内存的值为正(例如,仅仅8字节字的前k字节是可访问的)我们需要比较地址的前三位和k。
ShadowAddr = (Addr >> 3) + Offset;
k = *ShadowAddr;
if (k != 0 && ((Addr & 7) + AccessSize > k))
ReportAndCrash(Addr);
这两个例子中指令仅插入一个内存读到之前的内存访问代码中,我们假设一个N字节的访问是N字节对齐的。地址消毒可能遗失掉一个关于地址对齐的bug,如3.5所讲。
我们放置地址消毒指令到LLVM优化流水线的最后。以这种方式我们指令所有LLVM优化器的纯量和循环优化。比如,LLVM对本地栈对象的内存访问将不会实施修改。同时我们不能实施LLVM代码生成器的内存访问。
错误上报代码(ReportAndCrash(Addr))仅执行一次,却被多处调用,所以它必须是紧凑的优质代码。目前我们使用一个简单的函数调用(例如 Appendix A),另一种选择可能是使用一个能产生硬件中断的指令
运行时库
运行时库的主要功能是管理影子内存。在应用启动的时候整个影子区域均被映射所以诶呦其他的程序可以使用它。影子内存的坏段被保护了。在Linux上影子内存不会被占用所以内存映射总是成功的,在MacOS上我们需要去禁掉地址空间随机分布。我们的预备实现显示同样的影子内存分布同样在windows上可以工作。
malloc和free函数被特殊的实现所取代,malloc函数分配额外的内存,红区,包围着返回的区域上下。红区越大,被检测到的上溢出和下溢出越大。
内存分配器的内存区域被一些空闲链表管理,当一个空闲链表是空时,一片内存区域和红区被从系统分配(如mmap)。对已n个区域我们分配n+1个红区,一个内存区域右边的红区就是下一个区域左边的红区。
左边的红区用来存储内存分配器内部的数据(如分配大小,线程ID等);而且,堆红区的最小大小是32bytes。这些内部数据不会被一个buffer下溢出覆盖,因为下溢出会先于实际的存储是被发现(因为下溢出发生在指令代码中)
free函数给整个内存区域下毒并且将它放入隔离区,也就是说这块区域不会很快被malloc分配。目前,隔离区实现为一个FIFO队列,保持一定大小的内存。
默认的malloc和free记录当前的调用栈来提供更有用的信息。malloc调用栈记录于左红区,而free调用栈记录于它自己区域的开始。4.3节介绍了如何去调节运行时库。
栈和全局变量
为了检测到全局变量和栈对象的越界访问,地址消毒器必须在它们周围创建有毒的红区。对于全局变量,红区在编译时刻被创建,红区的地址在应用启动时被传给运行时库。运行时库涂毒到红区并记录地址以便报告错误。
对于栈对象,红区被在运行时创建和涂毒,当前使用32bytes(1byte+31bytes来满足对齐要求)的红区,例如如下程序:
void foo() {char a[10];<function body> }
转换代码是:
void foo() {char rz1[32]char arr[10];char rz2[32-10+32];unsigned *shadow =(unsigned*)(((long)rz1>>8)+Offset);// poison the redzones around arr.shadow[0] = 0xffffffff; // rz1shadow[1] = 0xffff0200; // arr and rz2shadow[2] = 0xffffffff; // rz2<function body>// un-poison all.shadow[0] = shadow[1] = shadow[2] = 0; }
硬件支持
地址消毒执行的指令可以被一个单独的硬件指令checkN所取代(例如,check4 Addr表示4 bytes访问),等于如下:
ShadowAddr = (Addr >> Scale) + Offset;k = *ShadowAddr;if (k != 0 && ((Addr & 7) + N > k)GenerateException();
offset和scale的值存在于特俗的寄存器中并且在应用启动的时候被设置。
这样一个指令讲通过降低cache压力来提升性能,组成简单的数学操作并且达到更好的分支预测。它也将显著的降低二进制的大小。默认的checkN指令将是一个空操作,将被一个特殊的CPU flag激活。这个将允许有选择的测试特定的场景或者甚至测试长存的进程的部分生命周期。
指令例子
这里给了两个例子在x86_64平台上存储8 bytes和4 bytes
void foo(T *a) {*a = 0x1234;}
8-byte store:
clang -O2 -faddress-sanitizer a.c -c -DT=longpush %raxmov %rdi,%raxshr $0x3,%raxmov $0x100000000000,%rcxor %rax,%rcxcmpb $0x0,(%rcx) # Compare Shadow with 0jne 23 <foo+0x23> # To Errormovq $0x1234,(%rdi) # Original storepop %raxretqcallq __asan_report_store8 # Error
4-byte store:
clang -O2 -faddress-sanitizer a.c -c -DT=intpush %raxmov %rdi,%raxshr $0x3,%raxmov $0x100000000000,%rcxor %rax,%rcxmov (%rcx),%al # Get Shadowtest %al,%alje 27 <foo+0x27> # To original storemov %edi,%ecx # Slow pathand $0x7,%ecx # Slow pathadd $0x3,%ecx # Slow pathcmp %al,%cljge 2f <foo+0x2f> # To Errormovl $0x1234,(%rdi) # Original storepop %raxretqcallq __asan_report_store4 # Error