1.部分相关名词
System Memory
手机内存,几个G到十几个G的那种,也是常说的DDR
On Chip Memory
手机自身的SRAM缓存,容量挺小(几百K到几M),但读写巨快
在TB(D)R架构下会存储Tile的Color,Depth,Stencil。
Stall
一个结果已经计算完了 但等另一个结果计算完成的等待过程
Fillrate
像素填充率是指图形处理单元在每秒内所渲染的像素数量,单位是MPixel/S(每秒百万像素),或者GPixel/S(每秒十亿像素),是用来度量当前显卡的像素处理性能的最常用指标。
像素填充率 = ROP运行的时钟频率 × ROP的个数 × 每个时钟的ROP可以处理的像素个数
2.常见渲染架构
IMR
Immediate Mode Rendering,中文立即渲染

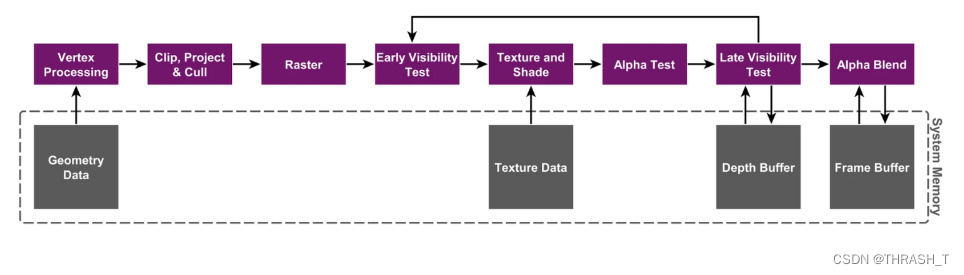
直接且传统的渲染架构,就是直接和内存进行交互,要几何信息、贴图信息就找内存拿,要读写Buffer就找内存改
TBR
Tile-Based Rendering,会将屏幕上的区域分成一个个的Tile分开来渲染

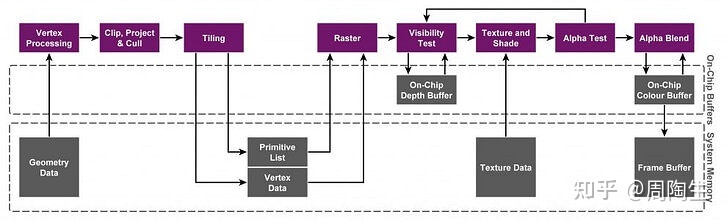
在第一个阶段,先把顶点着色器给执行完了,然后执行分Tile操作,给每个图元指定到块元里,然后再以Tile为单位去执行后续操作如光栅化等
分Tile操作就是形成一个图元的列表存到SystemMemory里
TBR增加了与On Chip Memory的交互,对于Buffer的操作会放在On Chip Memory上方便读写,在ColorBuffer搞定后在传到手机内存的FrameBuffer里
Defer
Defer的意思就是,等数据都传过来之后再一起处理
在刚刚TBR里,把图元集合成Tile就是一次Defer
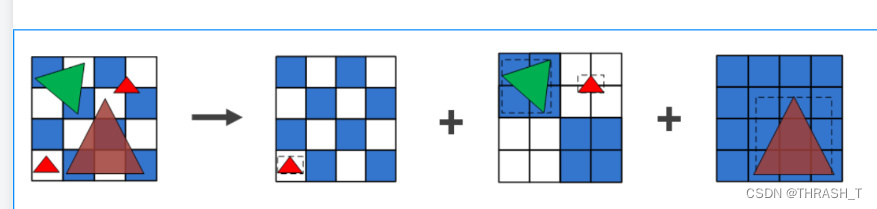
这个Defer又叫Binning过程,即确定哪些块元渲染哪些图元
TBDR

在TBR的基础上增加第二次Defer所以叫TBDR
这个Defer主要是优化Overdraw问题的。上节课说的EarlyZ除非严格从前往后不然无法完全优化Overdraw。
苹果:
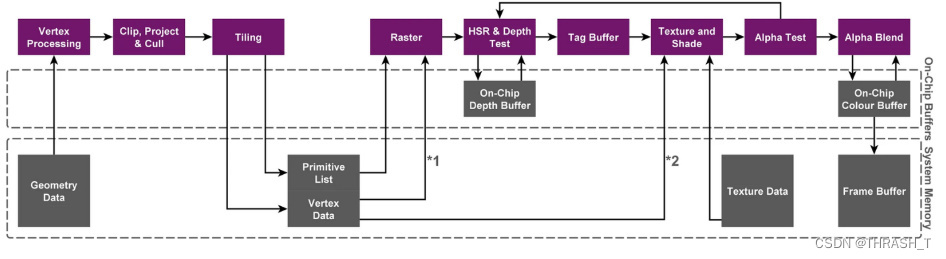
PowerVR会在原来EarlyZ的基础上增加了HSR,HiddenSurfaceRemoval,通过硬件层面的特性解决Overdraw问题
对于每个通过EarlyZ的Fragment,先读取第一次Defer产生的图元列表,标记哪个像素由哪个图元绘制,等Tile上的图元都处理完成时,它们都被标记上了,然后再把最近的不透明和最近的透明对象标记为需要被渲染传到fragment shader里
其他GPU的第二次Defer
骁龙:

Arm Mali:
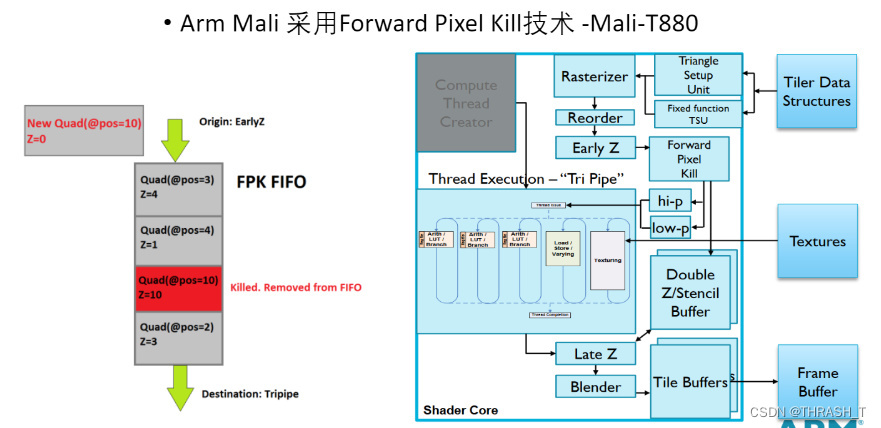
ForwardPixelKill,发生在EarlyZ之后,如果EarlyZ传过来的数据发现有同位置且深度较小的Quad时就会移除深度较大的Quad
TBR与IMR
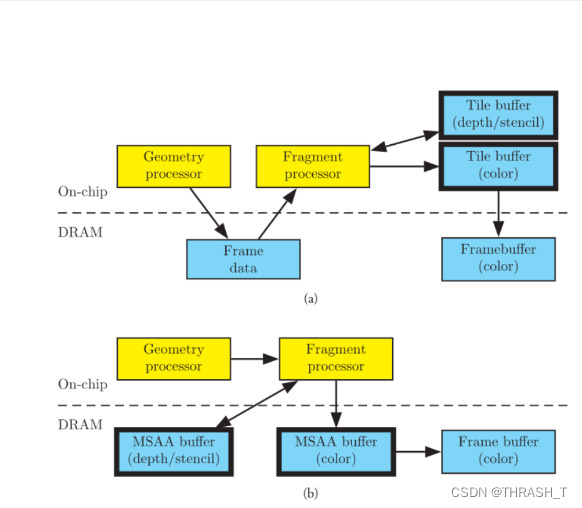
上TBR,下IMR,黄色为处理单元,蓝色为存储区域,其实也基本和上面的内容一个样(啊这张图有必要截吗?我是不是又在做那种事了)
3.TBR的特点
就是上面说到的,一块一块处理的,所以颜色也是一块一块刷出来的,而且整体有一定的顺序性

可见IMR在交界的地方有挺强的随机性(GPU乱序执行),不过TBR也有一定的随机性
TBR渲染速率并不比IMR快,目的是降低带宽,减少功耗
优点:
TBDR解决Overdraw
因为做成了一个个Tile,所以很多操作都是可以On-Chip Memory上做好,最终再把Color Buffer传给内存,降低带宽。不做Tile的话,每个Pass的每个DrawCall这样把Buffer传来传去,折磨带宽呢
缺点:
tile要和DDR交互
部分如Tessellation的操作不支持TBR(因为本身对几何信息做出改变)
对于同时叠加在多个tile的三角形要绘制多次
4.移动端TBR优化建议
不使用FrameBuffer的时候清除掉,清空积累在tilebuffer上的数据 ,避免将tlebuffer刷新到system memory
不要在一帧里频繁切换FrameBuffer,减少tlebuffer和system memory的stall
移动平台建议用AB而不是AT(经验性结论,最好测试一下),必须用AT的话先做PreZ
图片压缩、mipmap
尽量使用Vertex传入的UV,不在fragment动态计算UV
延迟渲染尽量利用TileBuffer
如果在Unity中调整ProjectSetting---Quality---Rendering---Texture Quality的不同设置,或者不同分辨率下,帧率有很大的变化,大概率是带宽出问题了
MSAA在TBDR上很快
少在Fragment里Discard,防止打断EarlyZ
细心区分浮点类型(float half uniform等)优化带宽
尽量避免曲面细分,提倡LOD(TBR友好)
作业
结合课程,将demo打包到安卓平台,对比使用课上优化点前后的性能变化
使用UPR进行测试,设备是红米K30S,场景长这样
AssetStore找的,PolytopeStudio的资源,可以搜Lowpoly Medieval。总体是个Lowpoly风格,花花草草树树叶叶啥的都是AlphaTest做的,贴图大多是一个物体用一大张


自己经过一轮的测试发现测试的时候乱摆摄像头会导致数据有较大浮动,所以将摄像头固定在开始界面进行20秒的测试

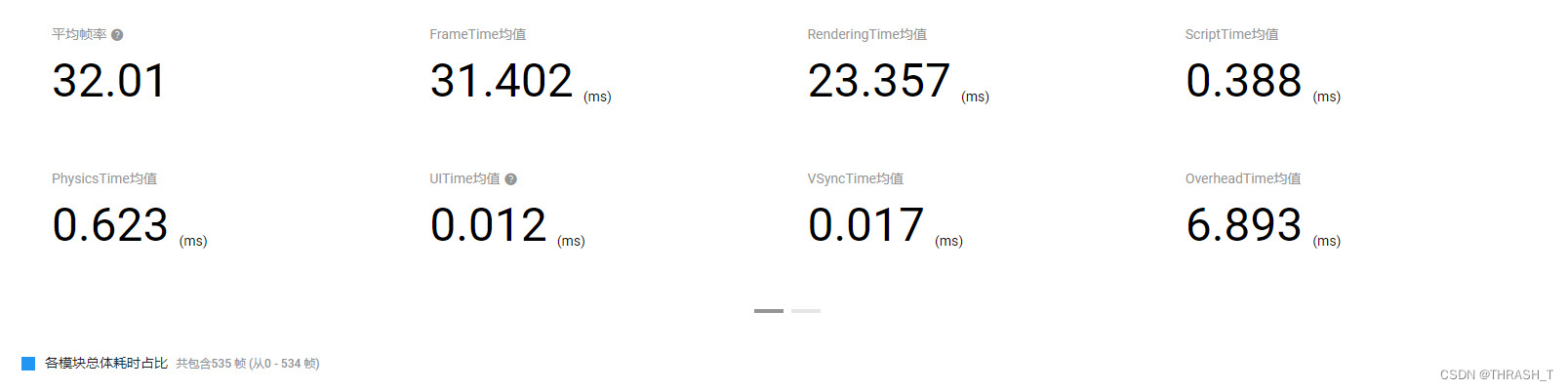
1.默认
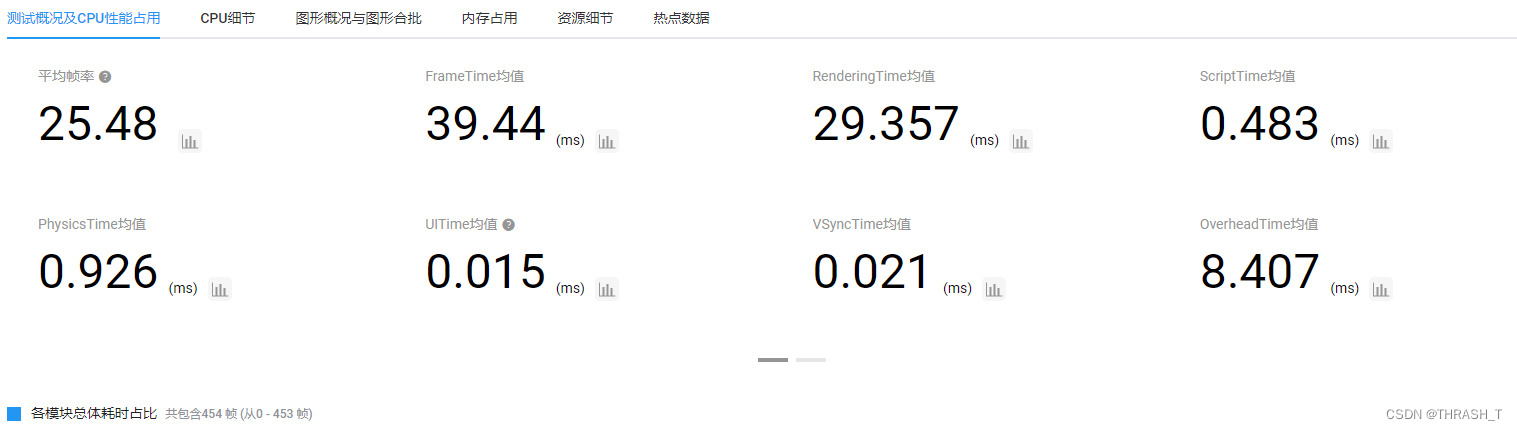
2.贴图压缩格式由No Override改为ETC2
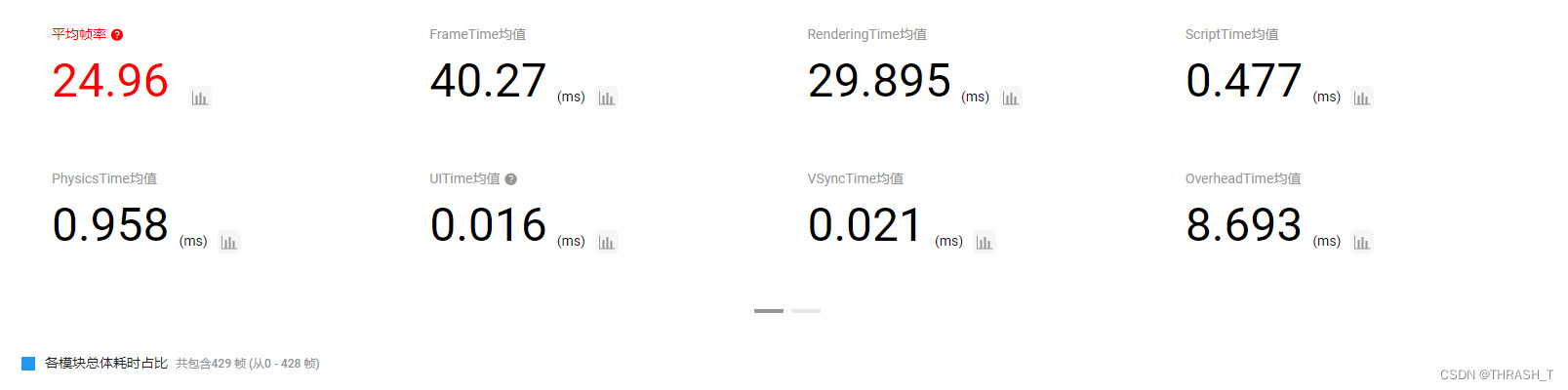
帧率变化不大,不过纹理资源峰值倒是由原来的300M变成了250M
3.贴图大小由2048改成1024
变化也不大
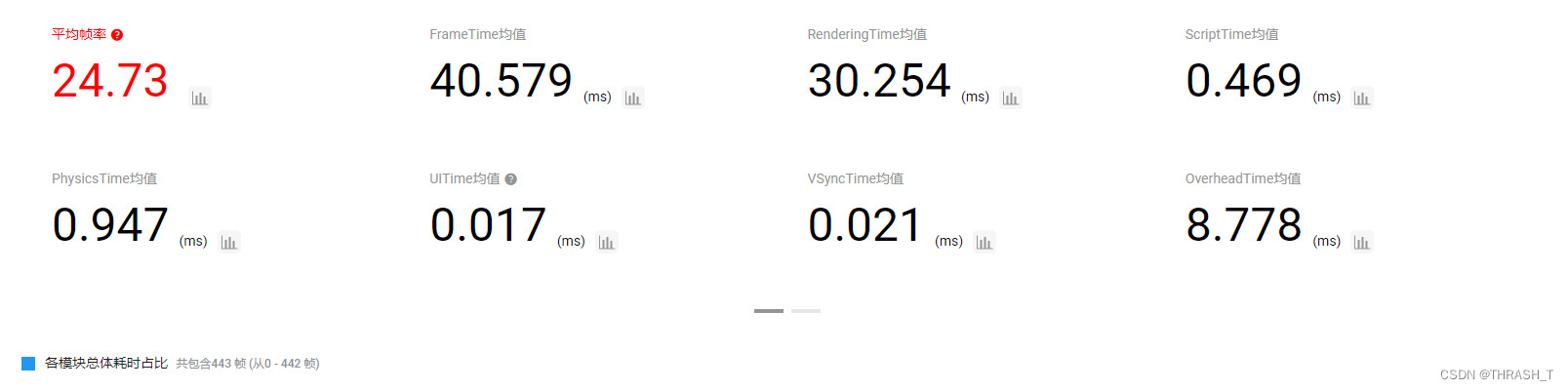
4.关闭AlphaTest
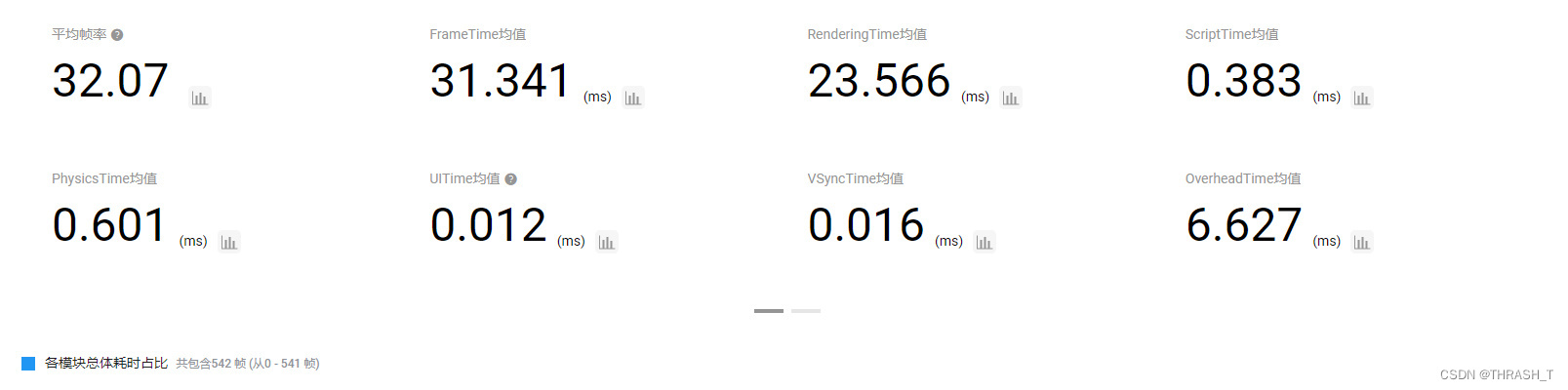 性能巨量优化,毕竟一地的草Overdraw可不是闹着玩的
性能巨量优化,毕竟一地的草Overdraw可不是闹着玩的
5.关闭Mipmap
性能稍微降低